PyTorch量化感知训练技术:模型压缩与高精度边缘部署实践
在神经网络研究的前沿,我们正面临着模型精度与运行效率之间的权衡挑战。尽管架构优化、层融合和模型编译等技术已取得显著进展,但这些方法往往不足以同时满足边缘设备部署所需的模型尺寸和精度要求。
研究人员通常采用三种主要策略来实现模型压缩同时保持准确性:
- 模型量化:通过降低模型权重的数值精度表示(例如将16位浮点数转换为8位整数),减少神经网络的内存占用和计算复杂度。
- 模型剪枝:识别并移除训练好的神经网络中贡献较小的神经元或权重,以简化网络架构而不显著影响性能。
- 知识蒸馏(又称教师-学生训练):训练一个更小、更高效的网络(学生模型)来复现更大、更复杂模型(教师模型)的软预测输出。软标签使学生模型获得更好的泛化能力,因为它们代表了类别相似性的高层次抽象理解,而非传统的独热编码表示。
本文将深入探讨模型量化的原理、主要量化技术类型以及如何使用PyTorch实现这些技术。
量化技术基础
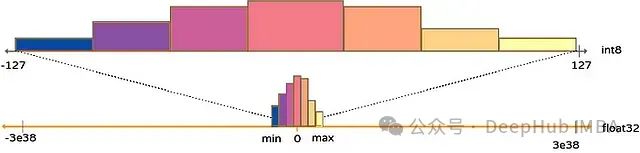
量化是神经网络优化中最强大且实用的技术之一。它通过将模型数据(包括网络参数和激活值)从高精度浮点表示(通常为16位)转换为低精度表示(通常为8位整数),从而降低神经网络的计算和内存需求。这种转换带来多方面的优势:
- GPU可利用更快速、更经济的8位计算单元(如NVIDIA GPU的Tensor Cores)执行卷积和矩阵乘法运算,显著提高计算吞吐量。
- 对于受内存带宽限制的网络层,量化可显著降低数据传输需求,减少总体运行时间。这类层的运行瓶颈主要在数据读写而非计算本身,因此从带宽优化中获益最大。
- 模型内存占用的减少不仅节省存储空间,还能减小参数更新大小,提高缓存利用率。
- 数据从内存传输到计算单元的过程消耗能量。将精度从16位降至8位能使数据量减半,有效降低功耗。
将高精度数值映射至低精度表示有多种方法(如零点量化、绝对最大值量化等),本文不作深入讨论。对此感兴趣的读者可参考Hao Wu等人和Amir Gholani等人的相关技术论文。
https://avoid.overfit.cn/post/c4a82be1e3a84f79912849651c4f4714

 浙公网安备 33010602011771号
浙公网安备 33010602011771号