VideoMind:Chain-of-LoRA突破时间盲区让AI真正看懂长视频
视频作为一种富含信息且密集的媒介,已广泛应用于娱乐、社交媒体、安全监控和自动驾驶等领域。人类能够轻松理解视频内容,例如理解因果关系、定位特定时刻以及关联动作。
但是人工智能,尤其是大型语言模型(LLM)及其多模态(MLLM)变体,在视频理解方面仍然面临挑战,尤其是在处理长视频时。尽管像 GPT-4V 或 Claude 这样的模型可以详细描述图像或短片,但在需要根据长序列中特定时间间隔推断事件时,它们往往表现不佳。它们虽然可以提供笼统的总结,但难以精确定位事件发生的时刻,或理解事件之间的因果关系。标准的 Chain-of-Thought (CoT) 技术在基于文本的推理中表现出色,但在需要将“思考”与精确时间相关联的视觉证据时,会遇到困难。
视频不仅仅是一系列静态图像,它还包含一个至关重要的时间维度。理解视频不仅需要识别“正在发生什么”,还需要识别“何时发生”、“持续多久”以及“与什么相关”。当前的 MLLM 通常通过抽样帧来处理视频,这可能会错过关键时刻或难以在较长时间内保持上下文。它们缺乏一种强大的时间定位机制,无法将推理和答案明确地链接回视频中特定的、可验证的时间段。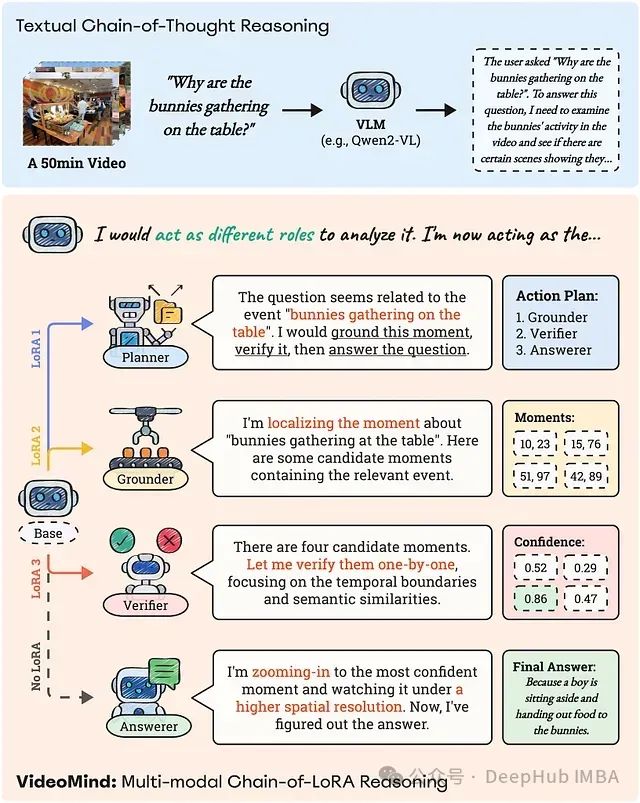
图 1:VideoMind 的 Chain-of-LoRA 推理策略应用于一个 50 分钟长视频的复杂问题。问题由 Planner 分解,并分发给 Grounder、Verifier 和 Answerer,以系统地定位、验证和解释相关的视频时刻。与纯文本 CoT 过程相比,这种基于角色的管道能够实现更像人类的视频推理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号