Hive 表复杂类型字段使用
1. Hive中复杂数据类型
1>. 复杂类型定义
1.1 map结构数据定义 map<string,string>
1.2 array结构数据定义 array<string>
1.3 struct结构数据定义 struct<id:int,name:string,age:int>
1.4 struct和array嵌套定义 array<struct<id:int,name:string,age:int>>
2>. 复杂类型数据封装
2.1 map类型
map(key1,val1,key2,val2,....) --使用map函数
2.2 struct类型
struct(val1,val2,val3,..) --使用struct构造器函数,对应列名默认是col1,col2,col3,...
named_struct(name1,val1,name2,val2,..) --使用带名称struct构造器函数,指定对应列名
2.3 array类型
array(val1,val2,val3,...)
collect_list() 函数
collect_set() 函数
3>. 复杂类型数据访问
3.1 map
map[key] --获取key对应的value
3.2 struct
struct.columnName --columnName代表列名
3.3 array
array[index] --index表示索引值
2. 具体使用案例
1>. 数据准备: 创建一个复杂类型的表+简单类型表
CREATE TABLE test.employee( name STRING, salary FLOAT, subordinates ARRAY<string>, deductions MAP<string,string>, address ARRAY<STRUCT<stree:string,city:string,state:string,zip:int>> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':' STORED AS TEXTFILE;
CREATE TABLE test.emp( name STRING, salary FLOAT, subord string, dedkey string, dedval FLOAT, stree string, city string, state string, zip int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
insert into test.emp (name,salary,subord,dedkey,dedval,stree,city,state,zip) values ('u001',25000,'sub001','ded-k01',10.01,'china','beijing','use','100000'); insert into test.emp (name,salary,subord,dedkey,dedval,stree,city,state,zip) values ('u001',25000,'sub002','ded-k02',20.02,'china-02','shanghai','use','100001'); insert into test.emp (name,salary,subord,dedkey,dedval,stree,city,state,zip) values ('u001',25000,'sub003','ded-k03',30.03,'china-03','lanzhou','use','100002');
2>. 根据简单类型表数据组装复杂类型表中数据
1). 使用collect_list()组装 ARRAY<string>字段 select name,collect_list(subord) subordinates from test.emp group by name; name subordinates u001 ["sub002","sub003","sub001"] 2). 使用collect_list()组装 ARRAY<STRUCT<stree:string,city:string,state:string,zip:int>>字段 select name,collect_set(named_struct('stree',stree,'city',city,'state',state,'zip',zip)) address from test.emp group by name; name address u001 [{"stree":"china-02","city":"shanghai","state":"use","zip":100001},{"stree":"china-03","city":"lanzhou","state":"use","zip":100002},{"stree":"china","city":"beijing","state":"use","zip":100000}] 3). 组装Map类型字段 select name,collect_set(named_struct('dedkey',dedkey,'dedval',dedval)) page_stats from test.emp group by name; u001 [{"dedkey":"ded-k02","dedval":20.02},{"dedkey":"ded-k03","dedval":30.03},{"dedkey":"ded-k01","dedval":10.01}] select name,collect_set(concat_ws('=',dedkey,cast(dedval as string))) page_stats from test.emp group by name; u001 ["ded-k02=20.02","ded-k03=30.03","ded-k01=10.01"] -- 第一步:将key-value字段组装成一个字符串,借助于concat_ws select name,concat_ws(':',dedkey,cast(dedval as string)) kvs from test.emp ; name kvs u001 ded-k03:30.03 u001 ded-k01:10.01 u001 ded-k02:20.02 -- 第二步: 将所有属于同一个人的数据组合在一起,,借助于collect_set select name,collect_set(concat_ws(':',dedkey,cast(dedval as string))) kvs from test.emp group by name; name kvs u001 ["ded-k02:20.02","ded-k03:30.03","ded-k01:10.01"] -- 第三步:将数组变成一个字符串,借助于concat_ws select name,concat_ws(',',collect_set(concat_ws(':',dedkey,cast(dedval as string)))) kvs from test.emp group by name; name kvs u001 ded-k02:20.02,ded-k03:30.03,ded-k01:10.01 -- 第四步: 将字符串转成map 使用函数str_to_map(text, delimiter1, delimiter2) -- text:是字符串 -- delimiter1:多个键值对之间的分隔符 -- delimiter2:key和value之间的分隔符 select name,str_to_map(concat_ws(',',collect_set(concat_ws(':',dedkey,cast(dedval as string)))),",",":") from test.emp group by name; map deductions u001 {"ded-k02":"20.02","ded-k03":"30.03","ded-k01":"10.01"}
3>. 最终插入复杂表的SQL
with deds as ( select name,str_to_map(concat_ws(',',collect_set(concat_ws(':',dedkey,cast(dedval as string)))),",",":") deductions from test.emp group by name ), adds as( select name,collect_set(named_struct('stree',stree,'city',city,'state',state,'zip',zip)) address from test.emp group by name ), subs as( select name,collect_list(subord) subordinates from test.emp group by name ) insert into table test.employee select coalesce(adds.name,deds.name,subs.name) name, 25000, subs.subordinates, deds.deductions, adds.address from deds full join adds on deds.name=adds.name full join subs on deds.name=subs.name;
4>. 最终复杂表中数据查询
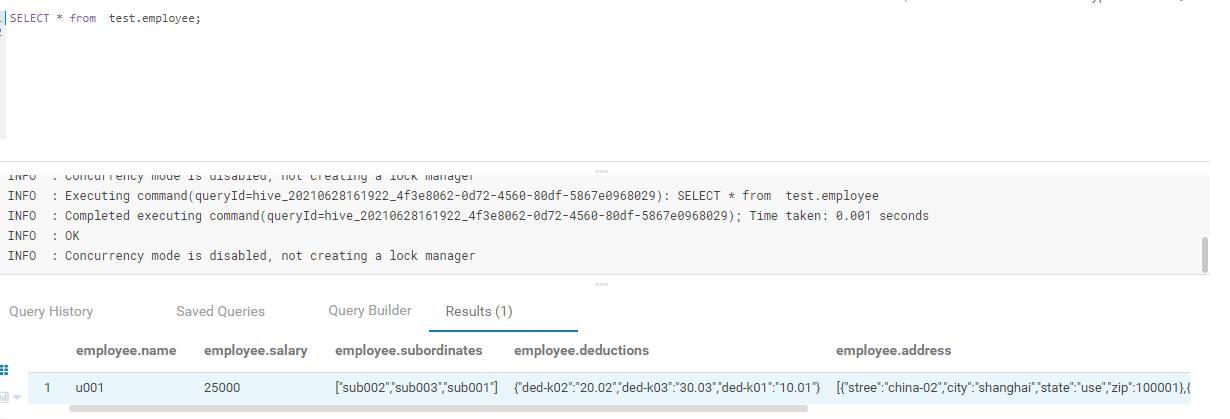
SELECT * from test.employee; employee.name employee.salary employee.subordinates employee.deductions u001 25000 ["sub002","sub003","sub001"] {"ded-k02":"20.02","ded-k03":"30.03","ded-k01":"10.01"} employee.address [{"stree":"china-02","city":"shanghai","state":"use","zip":100001},{"stree":"china-03","city":"lanzhou","state":"use","zip":100002},{"stree":"china","city":"beijing","state":"use","zip":100000}]
5>. Hive真实数据案例
CREATE TABLE `gt_os_bigdata.dwd_pro_calling_device_data_log`(
`shopid` string COMMENT '门店id',
`taskid` bigint COMMENT '任务id',
`deviceid` string COMMENT '设备id',
`callstatus` bigint COMMENT '呼叫状态',
`logtime` bigint COMMENT '呼叫时间',
`userid` string COMMENT '用户id',
`isrepeat` bigint COMMENT '是否重复呼叫',
`regioneid` string COMMENT '大区ID',
`branchidone` string COMMENT '一级分部id',
`branchidtwo` string COMMENT '二级分部id',
`username` string COMMENT '店员名称',
`devicename` string COMMENT '设备名称',
`shopname` string COMMENT '门店名称'
)COMMENT '呼叫器日志' `dt` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION'hdfs://grampus/team/smartdev/hive_db/iot_call/dwd/dwd_pro_calling_device_data_log';
需求说明:分别按照regioneid,branchidone,branchidtwo,shopid维度统计每天24小时呼叫器呼叫次数分布情况
select
regioneid,
str_to_map(concat_ws(',',collect_set(concat_ws(':',hr,cast(cn as string)))),",",":")
from (
select
regioneid,
from_unixtime(logtime,'HH') hr,
count(*) cn
from gm_os_bigdata.dwd_pro_calling_device_data_log
where dt= '2021-05-08'
group by regioneid,from_unixtime(logtime,'HH')
)t group by regioneid;
select
branchidone,
str_to_map(concat_ws(',',collect_set(concat_ws(':',hr,cast(cn as string)))),",",":")
from (
select
branchidone,
from_unixtime(logtime,'HH') hr,
count(*) cn
from gm_os_bigdata.dwd_pro_calling_device_data_log
where dt= '2021-05-08'
group by branchidone,from_unixtime(logtime,'HH')
)t group by branchidone;
select
branchidtwo,
str_to_map(concat_ws(',',collect_set(concat_ws(':',hr,cast(cn as string)))),",",":")
from (
select
branchidtwo,
from_unixtime(logtime,'HH') hr,
count(*) cn
from gm_os_bigdata.dwd_pro_calling_device_data_log
where dt= '2021-05-08'
group by branchidtwo,from_unixtime(logtime,'HH')
)t group by branchidtwo;
select
shopid,
str_to_map(concat_ws(',',collect_set(concat_ws(':',hr,cast(cn as string)))),",",":")
from (
select
shopid,
from_unixtime(logtime,'HH') hr,
count(*) cn
from gm_os_bigdata.dwd_pro_calling_device_data_log
where dt= '2021-05-08'
group by shopid,from_unixtime(logtime,'HH')
)t group by shopid;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号