MySQL优化、锁

1. MySQL优化-查看执行记录
MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化。
使用explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。
EXPLAIN 命令用法十分简单, 在 SELECT 语句前加上 explain 就可以了, 例如:

1.1 SQL语句优化-explain分析问题
expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra,下面对这些字段进行解释:
id: select查询的标识符. 每个 select都会自动分配一个唯一的标识符.
select_type:表示查询的类型。
table:输出结果集的表
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:哪个字段或常数与key一起被使用
rows:扫描出的行数(估算的行数)
Extra:执行情况的描述和说明

1.1.1 id
SELECT识别符。这是SELECT的查询序列号
1.1.2 select_type
PRIMARY :子查询中最外层查询
SUBQUERY : 子查询内层第一个SELECT,结果不依赖于外部查询
DEPENDENT SUBQUERY:子查询内层第一个SELECT,依赖于外部查询
UNION :UNION语句中第二个SELECT开始后面所有SELECT,
SIMPLE:简单的 select 查询,不使用 union 及子查询
UNION :UNION 中的第二个或随后的 select 查询,不依赖于外部查询的结果集
1.1.3 Table
显示这一步所访问数据库中表名称
1.1.4 Type
对表访问方式
ALL:
SELECT * FROM emp \G
完整的表扫描通常不好
SELECT * FROM (SELECT * FROM emp WHERE empno = 1) a ;
system:表仅有一行(=系统表)。这是const联接类型的一个特
const:表最多有一个匹配行
1.1.5 Possible_keys
该查询可以利用的索引,如果没有任何索引显示 null
1.1.6 Key
Mysql 从 Possible_keys 所选择使用索引
1.1.7 Rows
2. MySQL优化-慢查询
MySQL的慢查询,全名是慢查询日志,是MySQL提供的一种日志记录,用来记录在MySQL中响应时间超过阀值的语句。具体环境中,运行时间超过long_query_time值的SQL语句,则会被记录到慢查询日志中。简单的说就是运行很长时间的sql语句
MySQL的慢查询日志功能,默认是关闭的,需要手动开启。
2.1 查看是否开启慢查询
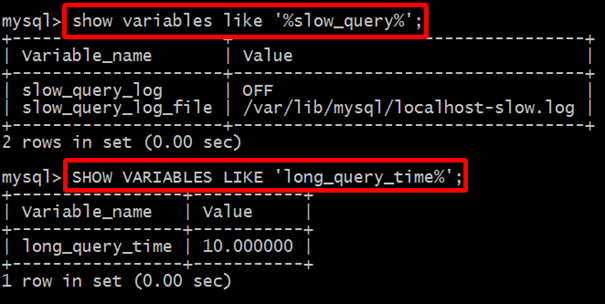
Ø slow_query_log :是否开启慢查询日志,ON 为开启,OFF 为关闭,如果为关闭可以开启。
Ø log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
Ø slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
Ø long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志,单位为秒。
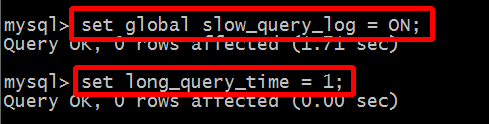
2.2 临时开启慢查询功能
在 MySQL 执行 SQL 语句设置,但是如果重启 MySQL 的话将失效
set global slow_query_log = ON; set global long_query_time = 1;
2.3 永久开启慢查询功能
修改/etc/my.cnf配置文件,重启 MySQL, 这种永久生效. [mysqld]
slow_query_log = ON slow_query_log_file = /var/log/mysql/slow.log long_query_time = 1

2.4 慢查询格式
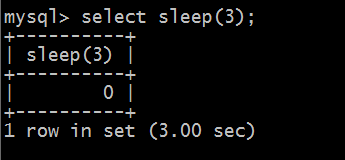
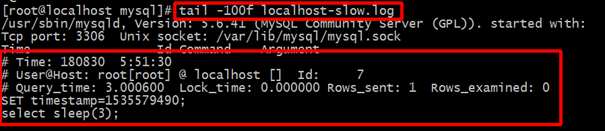
说明:
第一行,SQL查询执行的时间
第二行,执行SQL查询的连接信息,用户和连接IP
第三行,记录了一些我们比较有用的信息,如下解析
Query_time,这条SQL执行的时间,越长则越慢
Lock_time,在MySQL服务器阶段(不是在存储引擎阶段)等待表锁时间
Rows_sent,查询返回的行数
Rows_examined,查询检查的行数,越长就当然越费时间
第四行,设置时间戳,没有实际意义,只是和第一行对应执行时间。
第五行及后面所有行(第二个# Time:之前),执行的sql语句记录信息,因为sql可能会很长
3. MySQL优化-profiling分析查询
通过慢日志查询可以知道哪些SQL语句执行效率低下,通过explain我们可以得知SQL语句的具体执行情况,索引使用等,还可以结合show命令查看执行状态。
如果觉得explain的信息不够详细,可以同通过profiling命令得到更准确的SQL执行消耗系统资源的信息。
profiling默认是关闭的。可以通过以下语句查看
打开功能: mysql>set profiling=1; --1是开启、0是关闭
执行需要测试的sql 语句:

mysql> show profiles\G; 可以得到被执行的SQL语句的时间和ID
mysql>show profile for query 1; 得到对应SQL语句执行的详细信息
show profile命令格式:
SHOW PROFILE [type [, type] … ]
[FOR QUERY n]
[LIMIT row_count [OFFSET offset]]
type:
ALL
| BLOCK IO
| CONTEXT SWITCHES
| CPU
| IPC
| MEMORY
| PAGE FAULTS
| SOURCE
| SWAPS
以上的16rows是针对非常简单的select语句的资源信息,对于较复杂的SQL语句,会有更多的行和字段,比如converting HEAP to MyISAM 、Copying to tmp table等等,由于以上的SQL语句不存在复杂的表操作,所以未显示这些字段。通过profiling资源耗费信息,我们可以采取针对性的优化措施。
测试完毕以后,关闭参数:mysql> set profiling=0
4. MySQL锁
数据库锁定机制简单来说,就是数据库为了保证数据的一致性,而使各种共享资源在被并发访问变得有序所设计的一种规则。对于任何一种数据库来说都需要有相应的锁定机制,所以MySQL自然也不能例外。
MySQL数据库由于其自身架构的特点,存在多种数据存储引擎,每种存储引擎所针对的应用场景特点都不太一样,为了满足各自特定应用场景的需求,每种存储引擎的锁定机制都是为各自所面对的特定场景而优化设计,所以各存储引擎的锁定机制也有较大区别。
MySQL各存储引擎使用了三种类型(级别)的锁定机制:表级锁定,行级锁定和页级锁定。
4.1 表级锁定(table-level)
表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并大度大打折扣。
使用表级锁定的主要是MyISAM,MEMORY,CSV等一些非事务性存储引擎。
4.2 行级锁定(row-level)
行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力而提高一些需要高并发应用系统的整体性能。
虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
使用行级锁定的主要是InnoDB存储引擎。
4.3 页级锁定(page-level)
页级锁定是MySQL中比较独特的一种锁定级别,在其他数据库管理软件中也并不是太常见。页级锁定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力也同样是介于上面二者之间。另外,页级锁定和行级锁定一样,会发生死锁。
在数据库实现资源锁定的过程中,随着锁定资源颗粒度的减小,锁定相同数据量的数据所需要消耗的内存数量是越来越多的,实现算法也会越来越复杂。不过,随着锁定资源颗粒度的减小,应用程序的访问请求遇到锁等待的可能性也会随之降低,系统整体并发度也随之提升。
使用页级锁定的主要是BerkeleyDB存储引擎。
4.4 总结:
Ø 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
Ø 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
Ø 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
Ø 适用:从锁的角度来说,表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号