RDD操作
一、RDD的创建
从本地文件系统创建加载数据创建RDD
lines1 = sc.textFile("file:///home/zt/my.txt")
lines1
lines1.collect()

从hdfs加载数据创建RDD
1.hdfs的创建
start-all.sh 或 start-dfs.sh

2.上传文件至hdfs并查看
hdfs dfs -put /usr/local/pythonspace/text.txt /pythonspace/01
hdfs dfs -ls /pythonspace/01


3.进入spark加载hdfs文件
>>> lines1 = sc.textFile("/pythonspace/01/text.txt")
>>> lines1
>>> lines1.collect()
4.通过并行集合(列表)创建RDD
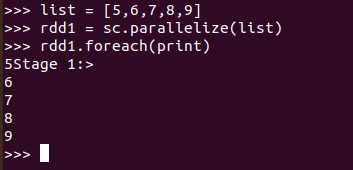
>>> list = [5,6,7,8,9]
>>> rdd1 = sc.parallelize(list)
>>> rdd1.foreach(print)
二、RDD操作
转换操作
1. filter(func)
案例:过滤指定单词
定义显式函数实现方式
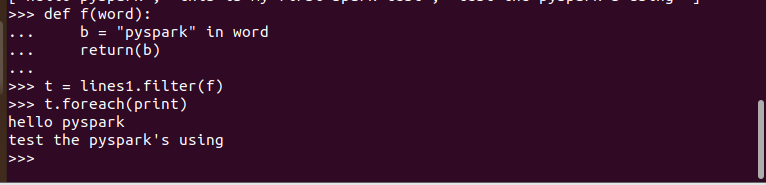
>>> def f(word):
... b = "pyspark" in word
... return(b)
...
>>> t = lines1.filter(f)
>>> t.foreach(print)
匿名函数实现方式
>>> lines1 = sc.textFile("/pythonspace/01/text.txt")
>>> t1 = lines1.filter(lambda word:"pyspark" in word)
>>> t1.foreach(print)

2.map(func)
含义:将每个元素传递到函数func中,并将结果返回为一个新的数据集
案例:字符串分词
定义显示函数方式实现
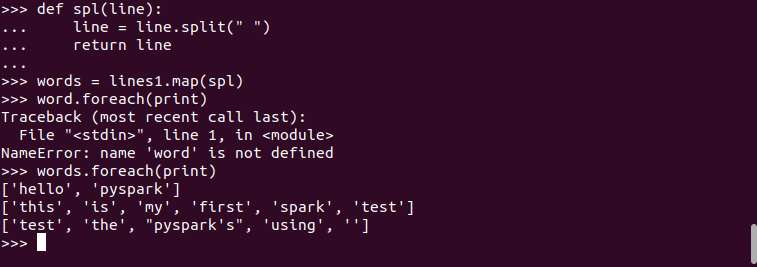
>>> def spl(line):
... line = line.split(" ")
... return line
...
>>> words = lines1.map(spl)
>>> word.foreach(print)
定义匿名函数实现方式
>>> words = lines1.map(lambda line:line.split())
>>> words.foreach(print)
['hello', 'pyspark']
['this', 'is', 'my', 'first', 'spark', 'test']
['test', 'the', "pyspark's", 'using']

案例:数据加100
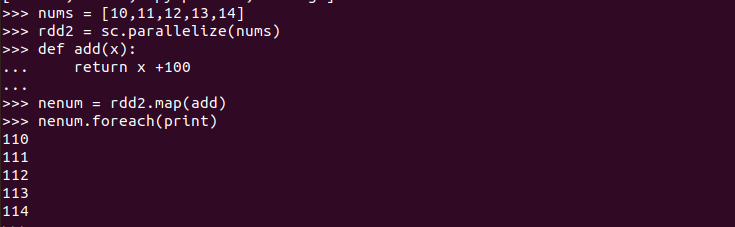
>>> nums = [10,11,12,13,14]
>>> rdd2 = sc.parallelize(nums)
>>> def add(x):
... return x +100
...
>>> nenum = rdd2.map(add)
>>> nenum.foreach(print)
案例:字符串加固定前缀
>>> rdd2 = rdd3.map(lambda x:"hello"+x)
>>> rdd2.foreach(print)

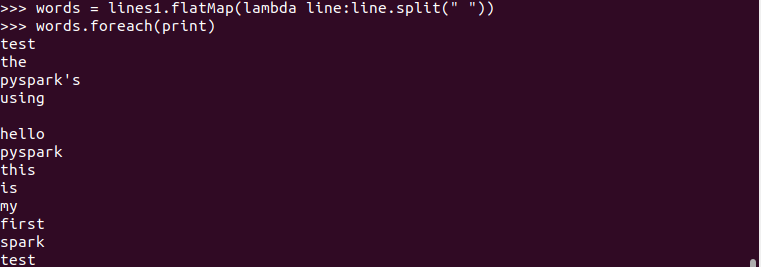
3. flatMap(func)
会将每一个输入对象输入映射为一个新集合,然后把这些新集合连成一个大集合。
>>> words = lines1.flatMap(lambda line:line.split(" "))
>>> words.foreach(print)
案例:将单词映射成键值对
>>> words = lines1.flatMap(lambda line:line.split()).map(lambda word:(word,1))
>>> words.collect()

4. reduceByKey()
按照相同的key,对value进行聚合(求和),在进行计算时要求元素必须时键值对形式的:(Key - Value类型)
案例: 统计词频,累加
>>> data = [(key,value)]
>>> words = sc.parallelize(data)
>>> words2 = words.reduceByKey(lambda a,b:a+b)
>>> words2.foreach(print)

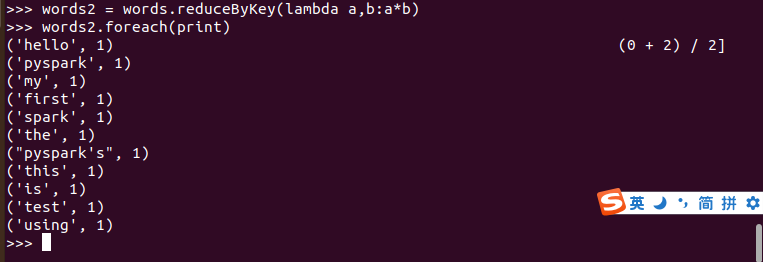
案例: 乘法运算
>>> words2 = words.reduceByKey(lambda a,b:a*b)
>>> words2.foreach(print)
5. groupByKey()
按照key对RDD中的value进行分组,从而生成单一的序列。
案例:单词分组,并查看分组的内容
words2.groupByKey().foreach(print)

案例:分组之后做累加的map
>>> words.groupByKey().map(lambda x: (x[0],sum(x[1]))).foreach(print)

6. sortByKey()
案例:对序列进行升序排列或者降序排序
words.sortByKey().foreach(print)

7. sortBy()
查看分区数

案例:对词频统计按词频排序
>>>words.sortBy(lambda x:x[1], True).collect()
>>> words.sortBy(lambda x:x[1], False).collect()

RDD写入文本文件
a、写入本地文件系统,并查看结果

b、写入分布式文件系统,并查看结果

行动操作

1. foreach(func)——通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
2. collect()——以数组的形式返回数据集的所有元素
3. count()——返回数据集中的元素个数
4.first()——返回数据集中的第一个元素
5. take(n)——以数组的形式返回数据集中的前n个元素
6. reduce(func) ——通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
与reduceByKey区别
reduce:将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
redeceByKey:对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号