数据结构
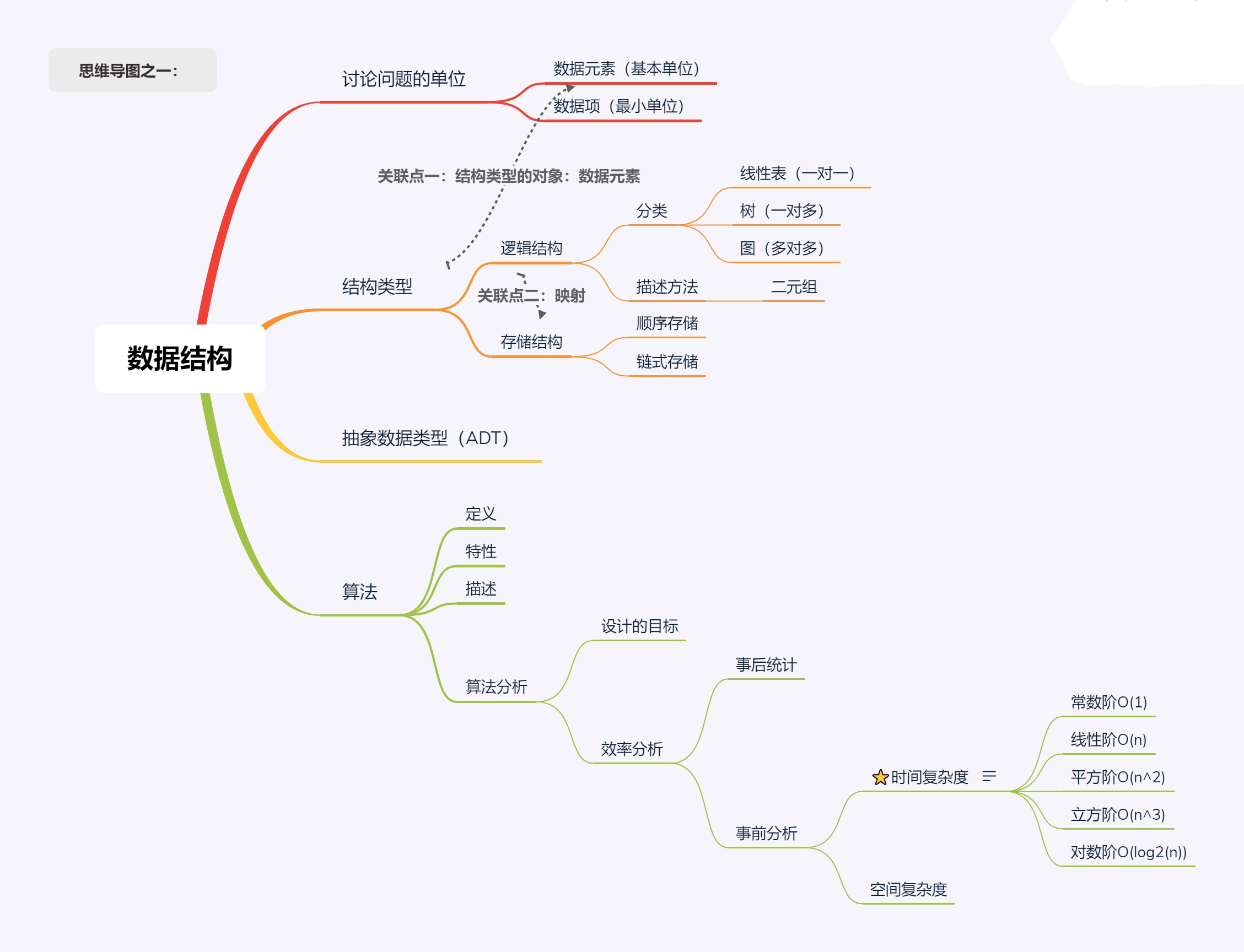
数据结构绪论:
数据结构:带“结构”的数据元素的集合;
数据元素:是数据集合中的一个“个体”,是数据结构中讨论的基本单位;
数据项:是数据结构中讨论的不可再分的最小单位;
二元组:
格式:
Data_Structure=(D,R)
D={di| 1≤i≤n,n≥0}
R={rj | 1≤j≤m,m≥0}
注:rj表示集合R中的第j个关系,每个关系用序偶表示。 序偶<x,y>(x,y∈D) x为第1个元素,y为第2个元素。
举例:
LinearList={D,R}
D={A,B,C}
R=
顺序、链式存储结构:逻辑上相邻存储在物理位置(地址)上是否相邻;
⭐抽象数据类型:用户定义的、表示应用问题的数学模型以及定义在 这个模型上一组操作的总称。 包含:数据对象、关系集合、基本操作
ADT Complex {
数据对象:
D={e1,e2 | e1,e2均为实数}
数据关系:
R={<e1,e2> | e1是复数的实数部分,e2 是复数的虚数部分 }
基本操作:
AssignComplex(&z,v1,v2):构造复数Z DestroyComplex(&z):销毁复数z GetReal(z,&real):返回复数z的实部值 GetImag(z,&Imag):返回复数z的虚部值 Add(z1,z2,&sum):返回两个复数z1、z2的和 ……} ADT Complex
算法:
算法的定义:对特定问题求解步骤的一种描述,它是指令 的有限序列,每一条 指令表示一个或多个操作。
算法的特性:有穷性、确定性、可行性、输入、输出;
算法的描述:自然语言、流程图、程序设计语言、伪代码;
算法设计的目标:正确性、可使用性、可读性、健壮性、时间效率高与存储量 低;
算法效率:
(1)时间复杂度:可由其基本运算的执行次数来计量;
算法中基本运算执行次数T(n)是问题规模n的某个函数
记作: T(n) = O(f(n))
T(n):基本运算执行次数
n:问题规模
“O”标记的形式定义: 若f(n)是正整数n的一个函数,则T(n)=O(f(n)) 表示存在一个正的常数M,使得当n≥n0时都满足: |T(n)|≤M|f(n)|
换句话说:当自变量n趋向于无穷大时,两者的比值 是一个小于等于M的常数。 如T(n) = n2, f(n) = 3n2+2n+1000只求出T(n)的最高阶,忽略其低阶项和常系数, 这样既可简化T(n)的计算,又能比较客观地反映 出当n很大时算法的时间性能。
例如,T(n) = 3n2 + 2n + 1000 = O(n2)
(2)空间复杂度:算法在运行过程中临时占用的存储空间的度量 。一般也是问题规模n的的函数S(n)=O(g(n))
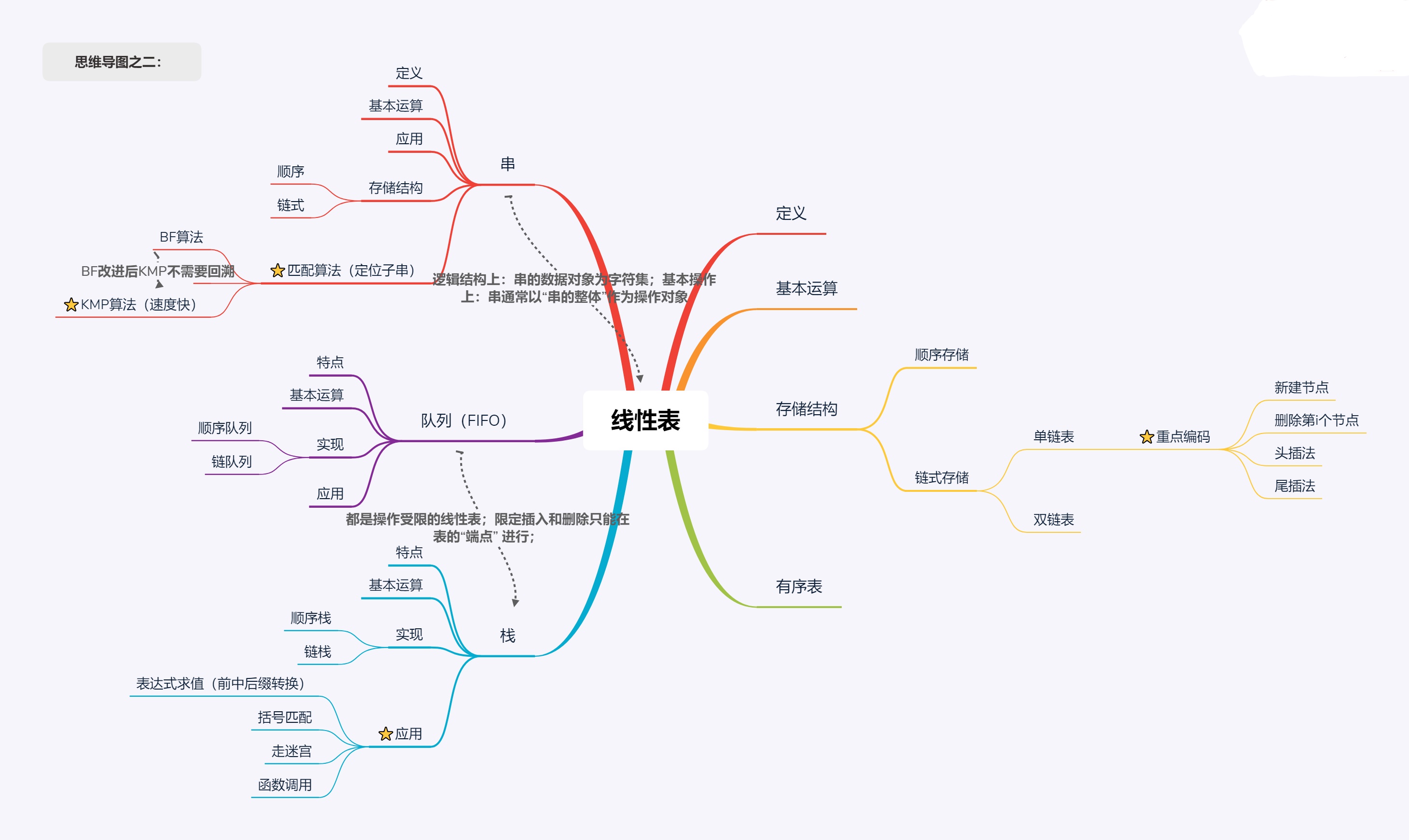
线性表:
普通线性表:
(1)定义:具有相同特性的数据元素的一个有限序列。 一般表示为 (a1, a2 ...,ai-1, ai, ai+1, ..., an) ;
(2)基本运算:
▲LocateElem(L,e):返回L中第一个值域与e相等的 逻辑位序。若这样的元素不存在,则返回0 ▲GetElem(L,i,&e):用e返回L中第i个元素的值 ▲ListInsert(&L,i,e):在L中第i个元素之前插入e ▲ListDelete(&L,i,&e):删除L中第i个元素 ▲LocateElem(L,e):返回L中第一个值域与e相等的 逻辑位序。若这样的元素不存在,则返回0 ▲GetElem(L,i,&e):用e返回L中第i个元素的值 ▲ListInsert(&L,i,e):在L中第i个元素之前插入e ▲ListDelete(&L,i,&e):删除L中第i个元素
(3)线性表的存储:
顺序存储:
【1】定义:使用一块地址连续的存储空间,按照线性 表中元素的逻辑顺序依次存放相应元素。
【2】⭐随机存储取特性:
利用地址相邻的特性,根据公式进行地址的计算:
LOC(ai)=LOC(a1)+(i-1)*len
LOC(a1):线性表的基地址
len: 每个元素的长度
【3】在C语言中的定义(数组):
#define MaxSize 50
typedef int ElemType; //ElemType类型实际上是int
typedef struct
{
ElemType data[MaxSize]; //存放顺序表中的元素
int length; //顺序表的长度
}SqList; //SequenceList, 顺序表
链式存储:
【1】特点:线性表中的数据元素存放在一组地址任意 的存储节点,节点之间使用“链”进行连接。
【2】链表存储密度低:存储密度=数据所占空间/节点所占用空间(节点所占用空间=数据占用空间+指针占用空间)
【3】节点和单链表类型的定义如下(链表):
typedef struct LNode //定义单链表节点结构体
{
ElemType data; //数据域
struct LNode *next; //指向后继节点
} LinkList;
【4】重点代码:
①新建节点:
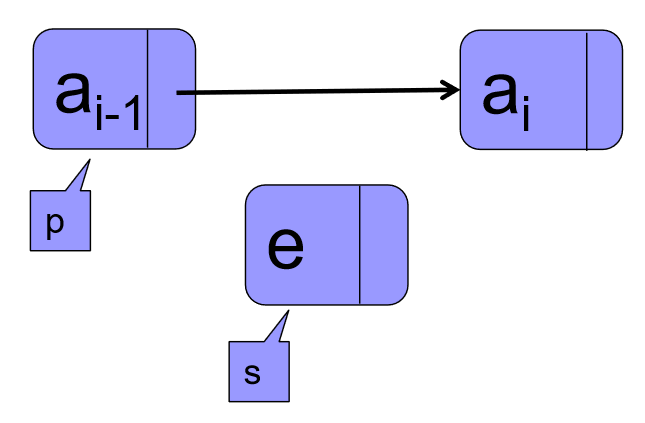
s = new LNode;
s->data = e;
s->next = p->next;
p->next = s;
②删除第i个节点:
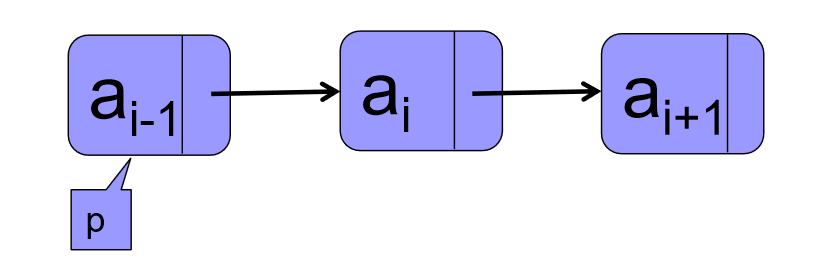
q = p->next;
e = q->data;
p->next = q->next;
delete q;
③头插法
void CreateListF(LinkList *&L, ElemType a[], int n)
{ LinkList *s;
int i;
L = new LNode;
L->next = NULL; //创建头节点,其next域置为NULL
for (i=0; i<n; i++){ //循环建立数据节点
s = new LNode;
s->data = a[i]; //创建数据节点*s
s->next = L->next; //将*s插在原开始节点之前,头节点之后
L->next = s;
}
}
④尾插法
void CreateListR(LinkList *&L, ElemType a[], int n)
{ LinkList *s,*r;
int i; L = new LNode; //创建头节点
r=L; //r始终指向尾节点,开始时指向头节点
for (i=0; i<n; i++) //循环建立数据节点
{ s = new LNode;
s->data = a[i]; //创建数据节点*s
r->next = s; //将*s插入*r之后
r = s;
}
r->next = NULL; //尾节点next域置为NULL
}
【5】双链表:节点中有两个指针域 一个指向后继节点,一个指向前驱节点。(方便查找一个节点的前驱与后继)
typedef struct DNode //声明双链表节点类型
{
ElemType data;
struct DNode *prior; //指向前驱节点
struct DNode *next; //指向后继节点
}DLinkList;
栈:
后进先出的线性表.
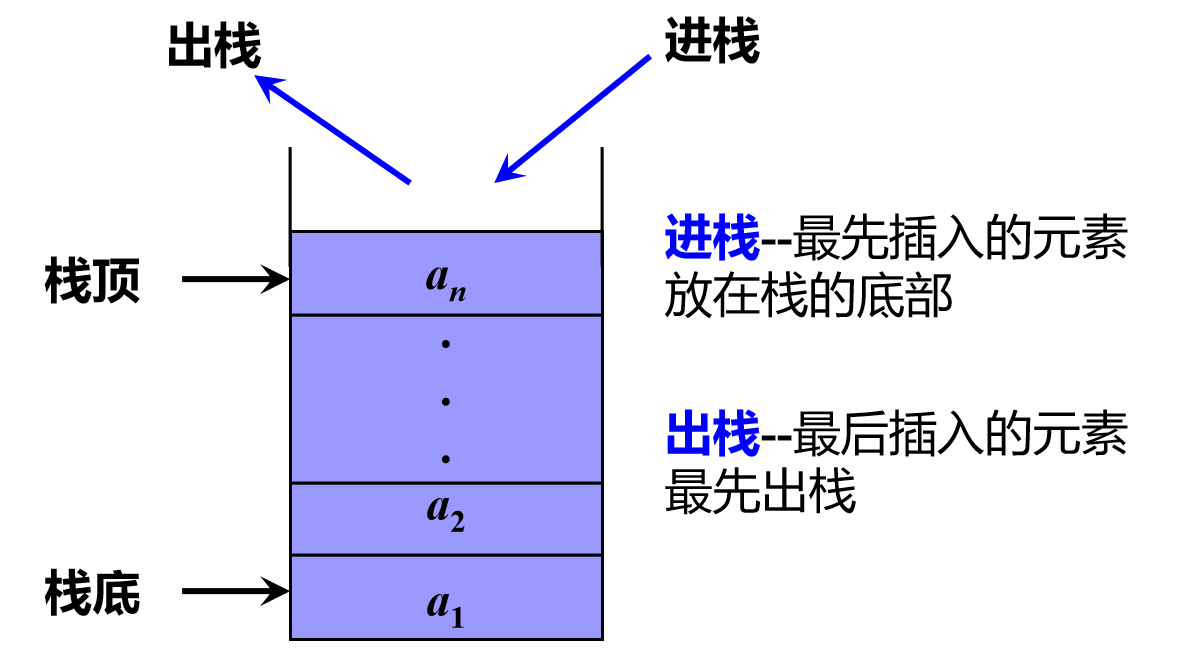
【1】特点:
①栈顶元素先出栈,栈底元素后出栈;
②时进时出→元素未完全进栈时,即可出栈;
【2】基本操作:
▲InitStack(&S) //操作结果:构造一个空栈 S
▲DestroyStack(&S) //初始条件:栈 S 已存在 操作结果:栈 S 被销毁
▲StackEmpty(S) //初始条件:栈S已存在 操作结果:若栈S为空栈,则返回TRUE,否则 FALSE
▲StackLength(S) //初始条件:栈S已存在。 操作结果:返回S的元素个数,即栈的长度
▲GetTop(S, &e) //查看栈顶元素,不同于Pop 初始条件:栈 S 已存在且非空。 操作结果:用 e 返回 S 的栈顶元素。
▲ClearStack(&S) //初始条件:栈 S 已存在。 操作结果:将 S 清为空栈。
▲Push(&S, e) //初始条件:栈 S 已存在。 操作结果:插入元素 e 为新的栈顶元素。
▲Pop(&S, &e) //初始条件:栈 S 已存在且非空。 操作结果:删除S的栈顶元素,并用e返回其值
【3】栈的表示与实现:
(1)顺序栈(即栈的顺序存储结构):
一组地址连续的存储单元依次存放自栈底到栈顶的数据元素。
◼ 初始分配量:MAXSIZE
◼ 栈底指针base,总是指向栈底。
◼ 栈顶指针top。栈空时,top等于base;栈非空时, 总是指向栈顶元素+1的位置。
插入一个栈顶元素,指针top增1;
删除一个栈顶元素,指针top减1;
非空栈中的栈顶指针始终在栈顶元素的下一个位置上。
⭐ 栈的顺序存储表示
#define MAXSIZE 100;//存储空间初始分配量
typedef int ElemType;
typedef int Position;
typedef struct {
ElemType *base; //栈构造前和销毁后,base的值为NULL
Position top; //栈顶指针
int size; //当前已分配的存储空间,以元素为单位
} SqStack;
(2)链栈:
注:链栈中指针的方向指向前驱结点。(头插法)
⭐链栈的定义:
typedef struct node{
LElemType data;
struct node *link;
}StackNode,*LinkStack;
链栈的特点:
◼ 插入和删除(进栈/出栈)只能在表头位置(栈顶)进行;
◼ 链栈中的结点是动态产生的,可不考虑上溢问题;
◼ 无需附加头结点,栈顶指针就是链表(即链栈)头指针。
⭐链栈进栈运算:
Status Push(LinkStack &S , ElemType e)
{/*将元素e进链栈 */
StackNode *p;
p = new StackNode;
if (!p) exit(OVERFLOW);
p->data = e;
p->link = S;
S = p;
return OK;
}
⭐链栈出栈运算:
Status Pop(LinkStack &S,SElemType &e)
{/*从链栈顶取出元素存至e */
if (s->next==NULL)
return false;
StackNode *p;//临时指针,用来销毁栈顶元素
e = S->data;
p = S;
S = S->next;
delete p;
return OK;
}
⭐栈在算法中的作用:暂存程序运行的中间状态
队列:
先进先出(FIFO) 的 线性表. 在表一端插入,在另一 端删除.
【1】基本运算:
▲ InitQueue(&Q) //操作结果:构造一个空队列Q。
▲ DestroyQueue(&Q) //初始条件:队列Q已存在。 操作结果:队列Q被销毁,不再存在。
▲ QueueEmpty(Q) //初始条件:队列Q已存在。 操作结果:若Q为空队列,则返回TRUE,否则返回 FALSE
▲ QueueLength(Q) //初始条件:队列Q已存在。 操作结果:返回Q的元素个数,即队列的长度。
▲ GetHead(Q, &e) //初始条件:Q为非空队列。 操作结果:用e返回Q的队头元素。
▲ ClearQueue(&Q) //初始条件:队列Q已存在。 操作结果:将Q清为空队列。
▲ EnQueue(&Q, e) //入队 初始条件:队列Q已存在。 操作结果:插入元素e为Q的新的队尾元素。
▲ DeQueue(&Q, &e) //出队 初始条件:Q为非空队列。 操作结果:删除Q的队头元素,并用e返回其值。
【2】队列类型的实现:
(1)顺序队列:
#define MAXQSIZE 100 //最大队列长度
typedef struct
{
QElemType *base; //初始化动态分配存储空间
int front, rear ; /*队首、队尾*/
}SqQueue;
SqQueue Q;
(2)链队列结构:
typedef int QElemType;
typedef struct QNode {// 结点类型
QElemType data;
struct QNode *next;
} QNode, *QueuePtr;
typedef struct { // 链队列类型
QueuePtr front; // 队头指针
QueuePtr rear; // 队尾指针
} LinkQueue;
⭐【3】解决假溢出——循环队列

入/出队列运算 利用“模运算”,则:
入队:Q.rear=(Q.rear+1)%m
出队:Q.front=(Q.front+1)%m
判断队空队满:
队空:front==rear 队满:front==rear
少用一个元素空间:
队空:Q.rear = Q.front
队满:(Q.rear+1) % m = Q.front
串:
【1】定义:由零个或多个字符组成的有限序列,一般记 为:s='a1a2...an' (n≥0)
*串中字符的个数n称为串的长度;包含零个字符, 即长度为零的串称为空串,用ф表示。(非空格串;空格串是一个或多个空格组成的)
◼ 子串:串中任意个连续的字符组成的子序列。
◼ 主串:包含子串的串称为主串。
◼ 位置:字符在序列中的序号。
子串在主串中的位置以子串的第一个字符在主串中 的位置来表示。
◼ 相等:两个串的长度相等,并且对应位置的字符 都相同。
【2】基本运算:
▲ StrEmpty(S) //初始条件:串S已存在。 操作结果:若S为空串,则返回TRUE,否则返回 FALSE。 ''表示空串,空串的长度为零。
▲ StrCompare(S, T) //初始条件:串S和T存在。 操作结果:若S>T,则返回值>0; 若S=T,则返回值=0; 若S<T,则返回值<0。 等价于C语言中的strcmp函数(按ASCII码值进行大 小比较) 原理:对字符串的每个字符逐个进行比较。
▲ StrLength(S) //初始条件:串 S 存在。 操作结果:返回 S 的元素个数,称为串的长度。 等价于C语言中的strlen函数
▲ Concat(&T, S1, S2) //初始条件:串 S1 和 S2 存在。 操作结果:用T返回由S1和S2联接而成的新串。
▲ SubString(&Sub, S, pos, len) //初始条件:串 S 存在,1≤pos≤StrLength(S) 且 0≤len≤StrLength(S)-pos+1。 操作结果:用 Sub 返回串 S 的第 pos 个字符 起长度为 len 的子串。
▲ Index(S, T, pos) 初始条件:串S和T存在,T是非空串, 1≤pos≤StrLength(S)。 操作结果: 若主串 S 中存在和串 T 值相同的子 串, 则返回它在主串 S 中第pos个字符之后第一 次出现的位置;否则函数值为0。 ◼ “子串在主串中的位置”指子串中的第一个字符在 主串中的位序。
▲ Replace(&S, T, V) 初始条件:串S, T和V均已存在,且T是非空串 操作结果:用 V 替换主串 S 中出现的所有与 (模式串)T 相等的不重叠的子串。
▲ StrInsert (&S, pos, T) 初始条件:串S和T存在, 1≤pos≤StrLength(S)+1 操作结果:在串S的第pos个字符之前插入串T。
▲ StrDelete (&S, pos, len) 初始条件:串S存在1≤pos≤StrLength(S)-len+1。 操作结果:从串S中删除第pos个字符起长度为len 的子串。
▲ ClearString (&S) 初始条件:串S存在。 操作结果:将S清为空串。
【3】算法
BF算法:
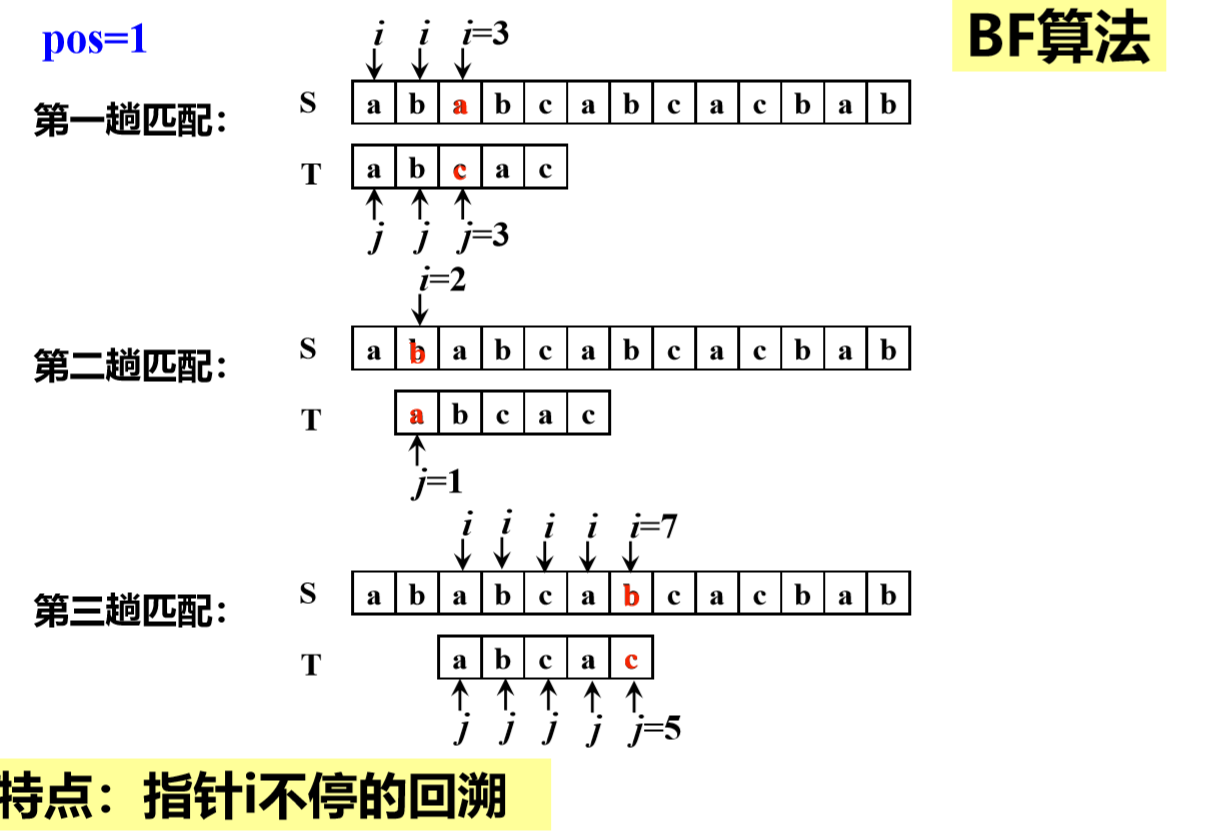
BF算法的时间复杂度:
若n为主串长度,m为子串长度,最坏情况是
主串前面n-m个位置都部分匹配到子串的最后一位, 即这n-m位各比较了m次
最后m位也各比较了1次 总次数为:(n-m)m+m=(n-m+1)m 若m<<n,则算法复杂度O(n*m)
KMP算法:
参考:https://blog.csdn.net/dark_cy/article/details/88698736
代码:
int Index_KMP(SString S, SString T, int pos) {
// 1≤pos≤StrLength(S)
i = pos; j = 1;
while (i <= S[0] && j <= T[0]) {
if (j == 0 || S[i] == T[j]) { ++i; ++j; } // 继续比较后继字符
else j = next[j]; // 模式串向右移动
}
if (j > T[0])
return i-T[0]; // 匹配成功
else return 0;
} // Index_KMP
难题解答:
应用一、括号匹配、中缀表达式转后缀表达式等“匹配”类问题:
解决方法:选择特定部分类型数据入栈、入队,结合实时输出以及暂时储存、调用第二个栈等。
例如(中缀转后缀):

参考来源:https://blog.csdn.net/weixin_44260779/article/details/90695746
应用二、迷宫问题(回溯法、广度遍历优先、深度遍历优先):
解决方法:利用栈来存储临时存储大量的临时数据,结合题目设置的判定条件使用各类判断如if,循环如while语句判断当前数据是否“合法”,合法入栈非法退栈,再利用递归等方法实现。
⭐复杂递归函数:多次分解求值
⭐广度遍历优先(最优解)代码:
private WideBlock wb; //广度遍历的终点节点
/*
广度优先遍历
*/
public void findPath4(){
wideFirst();
}
public void wideFirst(){
WideBlock start = new WideBlock(startX , startY , null);
Queue<WideBlock> q = new LinkedList<WideBlock>();
map[startX][startY] = 1;
q.offer(start);
while(q.peek() != null){
WideBlock b = q.poll();
int x = b.getX();
int y = b.getY();
if(x == endX && y == endY){ //判断当前节点是否已达终点
wb = b;
return;
}
if (x - 1 >= 0 && map[x - 1][y] == 0) { //判断当前节点的能否向上走一步,如果能,则将下一步节点加入队列
q.offer(new WideBlock(x - 1 , y , b)); //子节点入队
map[x - 1][y] = 1; //标记已访问
}
if (y + 1 <= mapY && map[x][y + 1] == 0) { //判断当前节点能否向右走一步
q.offer(new WideBlock(x , y + 1 , b));
map[x][y + 1] = 1;
}
if (x + 1 <= mapX && map[x + 1][y] == 0) {
q.offer(new WideBlock(x + 1 , y , b));
map[x + 1][y] = 1;
}
if (y - 1 >= 0 && map[x][y - 1] == 0) {
q.offer(new WideBlock(x , y - 1 , b));
map[x][y -1] = 1;
}
}
}
//打印广度遍历的路径
public void printWidePath(){
WideBlock b = wb;
int count = 1;
while(b != null){
System.out.print("(" + b.getX() + "," + b.getY() + ") ");
b = b.getParent();
if(count++ % 10 == 0){
System.out.println("");
}
}
}
参考来源:https://www.cnblogs.com/wanghang-learning/p/9430672.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号