DeepCoder正式发布:开源14B代码模型超越OpenAI O1,挑战o3-mini!
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!
Agentica联手Together.AI,用强化学习打造出真正“能写代码”的开源大模型
近日,Agentica Project 联合 Together AI 发布了开源模型 DeepCoder-14B-Preview,这是一个专为代码生成场景打造的大语言模型(LLM),基于 Deepseek-R1 架构微调而来,采用强化学习训练,在 LiveCodeBench 基准测试中取得 60.6% 通过率,超越了 OpenAI 的 o1 模型,逼近 o3-mini 表现。
这一成绩引发了业界的广泛关注。DeepCoder 不仅在 LiveCodeBench 上表现亮眼,还在 Codeforces、HumanEval 和数学竞赛 AIME2024 等多个基准测试中展现出与闭源模型相当甚至更优的推理能力。
📊 性能对比图:参数量 vs 代码通过率
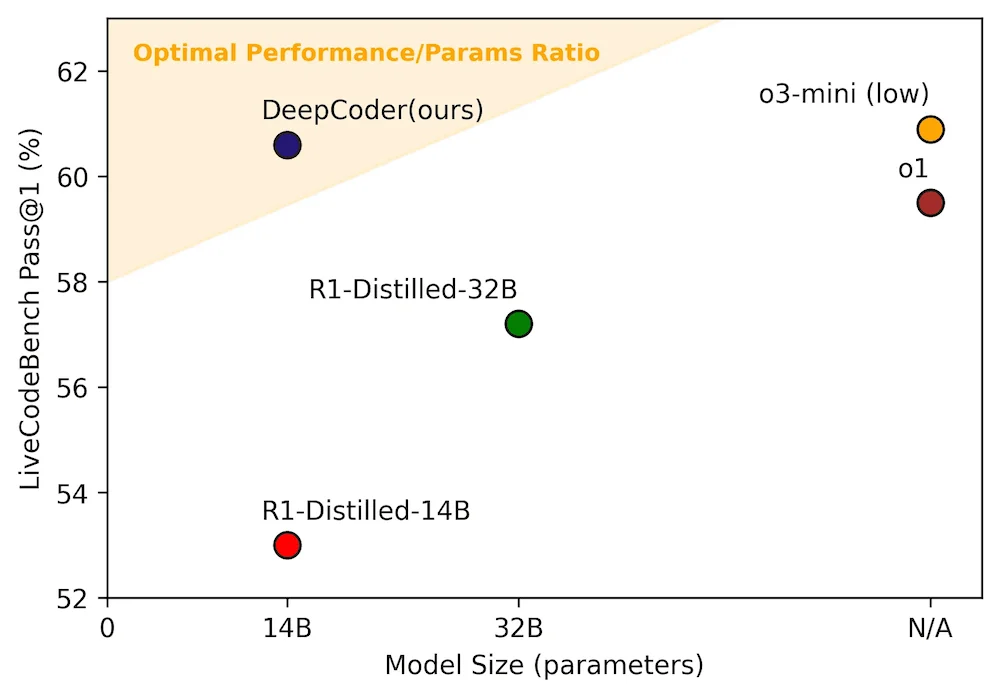
🔍 DeepCoder 的背后:开源、强化学习与推理优化三重突破
✅ 强化学习大幅优化训练收敛速度
DeepCoder 使用了基于 verl 框架 改造后的 分布式强化学习流水线,实现了训练效率的质变:
- 推理与训练并行进行:当前批次训练使用上一轮推理结果
- 训练迭代加速 1.4 倍
- End-to-end RL 整体效率提升 2 倍
这让原本需耗时“数月”的强化学习流程,缩短为“数周”完成。
✅ 高质量代码数据构建:从“容易+模糊”到“困难+可验证”
与很多现有代码数据集不同,DeepCoder 团队拒绝喂模型“低质量、不可验证”的数据:
- 自动筛选包含 至少5个单元测试 的编程题
- 剔除“过于简单”或已被模型轻松解决的问题
- 确保每道题都能通过测试进行 reward 信号反馈
这保证了强化学习过程中,模型的优化目标是“真实、困难、能评估”的问题,而不是追求假象准确率。
💡 为什么 DeepCoder 意义重大?
- 📂 全开源:不仅提供模型文件,还包括训练代码、数据集、改进的 RL 框架
- 🧠 专注推理能力提升:不只生成漂亮代码,更重视 程序可验证性与逻辑正确性
- ⛓️ 可复现性强:从训练日志到工程流程,完整透明
- 🤝 鼓励社区参与:Agentica 项目强调 “推动 RL for LLM 的社区协作与众包创新”
🧪 开发者反馈:初测表现超出预期
在 Reddit 社区,一位开发者分享了使用 14B 量化模型(q4)在本地运行的初体验:
“就日常开发任务来说,它的表现已经优于 GPT-4o,我甚至怀疑它可能比 o3-mini 更强……至少中小规模代码场景它是我目前试过的最佳选择之一。”
💬 专家点评:强化学习 + 代码 = 挑战与突破并存
AI 教父 Andrew Ng 在《The Batch》通讯中高度评价 DeepCoder:
“强化学习用于代码任务存在两个核心挑战:
- 可验证样本稀缺
- 奖励信号成本高(需要大量测试执行)
DeepCoder 优化了这两点,并将 RL 训练从‘几个月’压缩到‘几周’,为 LLM 的推理训练提供了可复现模板。”
他特别提到,DeepCoder 的 Verl-Pipeline 开源框架 为开发者提供了极具实用价值的 RL 训练工具链。
🔗 关键资源入口(开发者请收好)
- 🔗 项目官网:https://agentica-project.com
- 💾 模型下载:HuggingFace - DeepCoder-14B
- 🧠 GitHub 源码:https://github.com/agentica-project/rllm
- 📖 官方博客解析:https://www.together.ai/blog/deepcoder
📌 总结:开源社区的又一次胜利
在大模型领域,开源不只是“便宜的替代品”。DeepCoder 证明:
只要数据足够干净,训练方法足够科学,模型规模足够合理,开源 LLM 完全可以挑战闭源巨头。
无论你是模型训练研究者、代码 LLM 开发者,还是强化学习工程实践者,DeepCoder 都值得深入一看。
📣 如果你正在研究「AI生成代码」、「RLHF/代码验证」、「Agent任务编排」等方向,DeepCoder 提供了极具价值的可复现范式和训练路线图,值得深入解读。
如果这篇文章对你有帮助的话,别忘了【在看】【点赞】支持下哦~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号