
源码分析 | ClickHouse和他的朋友们(4)Pipeline处理器和调度器
本文首发于 2020-06-12 20:57:10
《ClickHouse和他的朋友们》系列文章转载自圈内好友 BohuTANG 的博客,原文链接:
https://bohutang.me/2020/06/11/clickhouse-and-friends-processor/
以下为正文。
最后更新: 2020-08-15
本文谈下 ClickHouse 核心科技:处理器 Processor 和有向无环调度器 DAG Scheduler。
这些概念并不是 ClickHouse 首创,感兴趣的同学可以关注下 materialize 的 timely-dataflow,虎哥用 golang 也写过一个原型。
拼的是实现细节,正是这些模块的精良设计,才有了 ClickHous e整体的高性能。
Pipeline问题
在传统数据库系统中,一个 Query 处理流程大体是:

其中在 Plan 阶段,往往会增加一个 Pipeline 组装(一个 transformer 代表一次数据处理):

所有 transformer 被编排成一个流水线(pipeline),然后交给 executor 串行式执行,每执行一个 transformer 数据集就会被加工并输出,一直到下游的 sinker。
可以看到,这种模型的优点是简单,缺点是性能低,无法发挥 CPU 的并行能力,通常叫火山模型(volcano-style),对于 OLTP 低延迟来说足够,对于计算密集的 OLAP 来说是远远不够的,CPU 不到 100% 就是犯罪!
对于上面的例子,如果 transformer1 和 transformer2 没有交集,那么它们就可以并行处理:
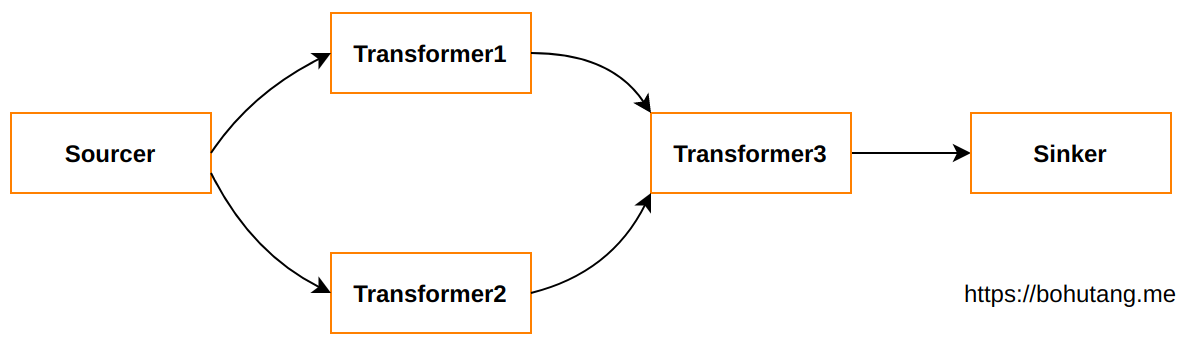
这样就涉及到一些比较灵魂的问题:
- 如何实现 transformer 的灵活编排?
- 如何实现 transformer 间的数据同步?
- 如何实现 transformer 间的并行调度?
Processor 和 DAG Scheduler
1. Transformer 编排
ClickHouse 实现了一系列基础 transformer 模块,见 src/Processors/Transforms,比如:
- FilterTransform – WHERE 条件过滤
- SortingTransform – ORDER BY 排序
- LimitByTransform – LIMIT 裁剪
当我们执行:
SELECT * FROM t1 WHERE id=1 ORDER BY time DESC LIMIT 10
对于 ClickHouse 的 QueryPipeline 来说,它会按照以下方式进行编排组装:
QueryPipeline::addSimpleTransform(Source)
QueryPipeline::addSimpleTransform(FilterTransform)
QueryPipeline::addSimpleTransform(SortingTransform)
QueryPipeline::addSimpleTransform(LimitByTransform)
QueryPipeline::addSimpleTransform(Sinker)
这样就实现了 Transformer 的编排,但是执行时数据如何进行同步呢?
2. Transformer 数据同步
当 QueryPipeline 进行 transformer 编排时,我们还需要进行更加底层的 DAG 连通构建。
connect(Source.OutPort, FilterTransform.InPort)
connect(FilterTransform.OutPort, SortingTransform.InPort)
connect(SortingTransform.OutPort, LimitByTransform.InPort)
connect(LimitByTransform.OutPort, Sinker.InPort)
这样就实现了数据的流向关系,一个 transformer 的 OutPort 对接另外一个的 InPort,就像我们现实中的水管管道一样,接口有 3 通甚至多通。
3. Transformer 执行调度
现在管道组装起来了,那么管道内的水如何进行处理和给压流动呢?
ClickHouse 定义了一套 transform 状态,processor 根据这些状态来实现调度。
enum class Status
{
NeedData // 等待数据流进入
PortFull, // 管道流出端阻塞
Finished, // 完成状态,退出
Ready, // 切换到 work 函数,进行逻辑处理
Async, // 切换到 schedule 函数,进行异步处理
Wait, // 等待异步处理
ExpandPipeline, // Pipeline 需要裂变
};
当 source 生成数据后,它的状态会设置为 PortFull,意思是等着流入其他 transformer 的 InPort,processor 会开始调度 FilterTransformer(NeedData) 的 Prepare,进行 PullData,然后它的状态设置为 Ready,等待 processor 调度 Work 方法进行数据Filter处理,大家就这样靠状态让 processor 去感知,来调度和做状态迁移,直到 Finished 状态。
这里值得一提的是 ExpandPipeline 状态,它会根据 transformer 的实现,可以把一个 transformer 裂变出更多个 transformer 并行执行,达到一个爆炸效果。
Example
SELECT number + 1 FROM t1;
为了更加深入理解 ClickHouse 的 processor 和 scheduler 机制,我们来一个原生态的 example:
- 一个 Source:
- AdderTransformer 对每个数字做加1操作
- 一个 Sinker,输出结果
1. Source
class MySource : public ISource
{
public:
String getName() const override { return "MySource"; }
MySource(UInt64 end_)
: ISource(Block({ColumnWithTypeAndName{ColumnUInt64::create(), std::make_shared<DataTypeUInt64>(), "number"}})), end(end_)
{
}
private:
UInt64 end;
bool done = false;
Chunk generate() override
{
if (done)
{
return Chunk();
}
MutableColumns columns;
columns.emplace_back(ColumnUInt64::create());
for (auto i = 0U; i < end; i++)
columns[0]->insert(i);
done = true;
return Chunk(std::move(columns), end);
}
};
2. MyAddTransform
class MyAddTransformer : public IProcessor
{
public:
String getName() const override { return "MyAddTransformer"; }
MyAddTransformer()
: IProcessor(
{Block({ColumnWithTypeAndName{ColumnUInt64::create(), std::make_shared<DataTypeUInt64>(), "number"}})},
{Block({ColumnWithTypeAndName{ColumnUInt64::create(), std::make_shared<DataTypeUInt64>(), "number"}})})
, input(inputs.front())
, output(outputs.front())
{
}
Status prepare() override
{
if (output.isFinished())
{
input.close();
return Status::Finished;
}
if (!output.canPush())
{
input.setNotNeeded();
return Status::PortFull;
}
if (has_process_data)
{
output.push(std::move(current_chunk));
has_process_data = false;
}
if (input.isFinished())
{
output.finish();
return Status::Finished;
}
if (!input.hasData())
{
input.setNeeded();
return Status::NeedData;
}
current_chunk = input.pull(false);
return Status::Ready;
}
void work() override
{
auto num_rows = current_chunk.getNumRows();
auto result_columns = current_chunk.cloneEmptyColumns();
auto columns = current_chunk.detachColumns();
for (auto i = 0U; i < num_rows; i++)
{
auto val = columns[0]->getUInt(i);
result_columns[0]->insert(val+1);
}
current_chunk.setColumns(std::move(result_columns), num_rows);
has_process_data = true;
}
InputPort & getInputPort() { return input; }
OutputPort & getOutputPort() { return output; }
protected:
bool has_input = false;
bool has_process_data = false;
Chunk current_chunk;
InputPort & input;
OutputPort & output;
};
3. MySink
class MySink : public ISink
{
public:
String getName() const override { return "MySinker"; }
MySink() : ISink(Block({ColumnWithTypeAndName{ColumnUInt64::create(), std::make_shared<DataTypeUInt64>(), "number"}})) { }
private:
WriteBufferFromFileDescriptor out{STDOUT_FILENO};
FormatSettings settings;
void consume(Chunk chunk) override
{
size_t rows = chunk.getNumRows();
size_t columns = chunk.getNumColumns();
for (size_t row_num = 0; row_num < rows; ++row_num)
{
writeString("prefix-", out);
for (size_t column_num = 0; column_num < columns; ++column_num)
{
if (column_num != 0)
writeChar('\t', out);
getPort()
.getHeader()
.getByPosition(column_num)
.type->serializeAsText(*chunk.getColumns()[column_num], row_num, out, settings);
}
writeChar('\n', out);
}
out.next();
}
};
4. DAG Scheduler
int main(int, char **)
{
auto source0 = std::make_shared<MySource>(5);
auto add0 = std::make_shared<MyAddTransformer>();
auto sinker0 = std::make_shared<MySink>();
/// Connect.
connect(source0->getPort(), add0->getInputPort());
connect(add0->getOutputPort(), sinker0->getPort());
std::vector<ProcessorPtr> processors = {source0, add0, sinker0};
PipelineExecutor executor(processors);
executor.execute(1);
}
总结
从开发者角度看还是比较复杂,状态迁移还需要开发者自己控制,不过 upstream 已经做了大量的基础工作,比如对 source的封装 ISource,对 sink 的封装 ISink,还有一个基础的 ISimpleTransform,让开发者在上层使用 processor 时更加容易,可以积木式搭建出自己想要的 pipeline。
ClickHouse 的 transformer 数据单元是 Chunk,transformer 对上游 OutPort 流过来的 Chunk 进行加工,然后输出给下游的 InPort,图连通式的流水线并行工作,让 CPU 尽量满负荷工作。
当一个 SQL 被解析成 AST 后,ClickHouse 根据 AST 构建 Query Plan,然后根据 QueryPlan 构建出 pipeline,最后由 processor 负责调度和执行。
目前,ClickHouse 新版本已经默认开启 QueryPipeline,同时这块代码也在不停的迭代。
欢迎关注我的微信公众号【数据库内核】:分享主流开源数据库和存储引擎相关技术。

| 标题 | 网址 |
|---|---|
| GitHub | https://dbkernel.github.io |
| 知乎 | https://www.zhihu.com/people/dbkernel/posts |
| 思否(SegmentFault) | https://segmentfault.com/u/dbkernel |
| 掘金 | https://juejin.im/user/5e9d3ed251882538083fed1f/posts |
| 开源中国(oschina) | https://my.oschina.net/dbkernel |
| 博客园(cnblogs) | https://www.cnblogs.com/dbkernel |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号