spark学习进度21(聚合操作、连接操作)
聚合操作:
groupby:
// 1. 创建 SparkSession val spark = SparkSession.builder() .master("local[6]") .appName("agg processor") .getOrCreate() import spark.implicits._ @Test def groupBy(): Unit = { // 2. 数据读取 val schema = StructType( List( StructField("id", IntegerType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("hour", IntegerType), StructField("season", IntegerType), StructField("pm", DoubleType) ) ) val sourceDF = spark.read .schema(schema) .option("header", value = true) .csv("dataset/beijingpm_with_nan.csv") // 3. 数据去掉空值 val cleanDF = sourceDF.where('pm =!= Double.NaN) // 分组 val groupedDF: RelationalGroupedDataset = cleanDF.groupBy('year, $"month") // 4. 使用 functions 函数来完成聚合 import org.apache.spark.sql.functions._ // 本质上, avg 这个函数定义了一个操作, 把表达式设置给 pm 列 // select avg(pm) from ... group by groupedDF.agg(avg('pm) as "pm_avg") .orderBy('pm_avg.desc) .show() groupedDF.agg(stddev(""))//求方差 .orderBy('pm_avg.desc) .show() // 5. 使用 GroupedDataset 的 API 来完成聚合 groupedDF.avg("pm") .select($"avg(pm)" as "pm_avg") .orderBy("pm_avg") .show() groupedDF.sum() .select($"avg(pm)" as "pm_avg") .orderBy("pm_avg") .show() }
多维聚合:
@Test def multiAgg(): Unit = { //不同来源的pm值 //统计在同一个月,不同来源的pm //同一年,不同来源的pm的平均值 //整体上看,不同来源的pm值是多少 val schemaFinal = StructType( List( StructField("source", StringType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("hour", IntegerType), StructField("season", IntegerType), StructField("pm", DoubleType) ) ) val pmFinal = spark.read .schema(schemaFinal) .option("header", value = true) .csv("dataset/pm_final.csv") import org.apache.spark.sql.functions._ // 需求1: 不同年, 不同来源, PM 值的平均数 // select source, year, avg(pm) as pm from ... group by source, year val postAndYearDF = pmFinal.groupBy('source, 'year) .agg(avg('pm) as "pm") // 需求2: 在整个数据集中, 按照不同的来源来统计 PM 值的平均数 // select source, avg(pm) as pm from ... group by source val postDF = pmFinal.groupBy('source) .agg(avg('pm) as "pm") .select('source, lit(null) as "year", 'pm) // 合并在同一个结果集中 postAndYearDF.union(postDF) .sort('source, 'year.asc_nulls_last, 'pm) .show() }
rollup

@Test def rollup(): Unit = { import org.apache.spark.sql.functions._ val sales = Seq( ("Beijing", 2016, 100), ("Beijing", 2017, 200), ("Shanghai", 2015, 50), ("Shanghai", 2016, 150), ("Guangzhou", 2017, 50) ).toDF("city", "year", "amount") // 滚动分组, A, B 两列, AB, A, null sales.rollup('city, 'year) .agg(sum('amount) as "amount") .sort('city.asc_nulls_last, 'year.asc_nulls_last) .show() }
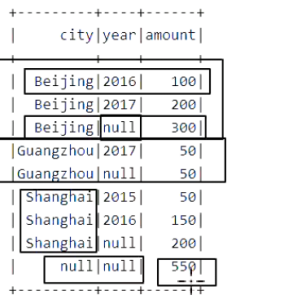
@Test def rollup1(): Unit = { import org.apache.spark.sql.functions._ // 1. 数据集读取 val schemaFinal = StructType( List( StructField("source", StringType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("hour", IntegerType), StructField("season", IntegerType), StructField("pm", DoubleType) ) ) val pmFinal = spark.read .schema(schemaFinal) .option("header", value = true) .csv("dataset/pm_final.csv") // 2. 聚合和统计 // 需求1: 每个PM值计量者, 每年PM值统计的平均数 groupby source year // 需求2: 每个PM值计量者, 整体上的PM平均值 groupby source // 需求3: 全局所有的计量者, 和日期的PM值的平均值 groupby null pmFinal.rollup('source, 'year) .agg(avg('pm) as "pm") .sort('source.asc_nulls_last, 'year.asc_nulls_last) .show() }

cube:全排列
@Test def cube(): Unit = { val schemaFinal = StructType( List( StructField("source", StringType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("hour", IntegerType), StructField("season", IntegerType), StructField("pm", DoubleType) ) ) val pmFinal = spark.read .schema(schemaFinal) .option("header", value = true) .csv("dataset/pm_final.csv") import org.apache.spark.sql.functions._ pmFinal.cube('source, 'year) .agg(avg('pm) as "pm") .sort('source.asc_nulls_last, 'year.asc_nulls_last) .show() }

cubeSql:
@Test def cubeSql(): Unit = { val schemaFinal = StructType( List( StructField("source", StringType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("hour", IntegerType), StructField("season", IntegerType), StructField("pm", DoubleType) ) ) val pmFinal = spark.read .schema(schemaFinal) .option("header", value = true) .csv("dataset/pm_final.csv") pmFinal.createOrReplaceTempView("pm_final")//临时表 val result = spark.sql("select source, year, avg(pm) as pm from pm_final group by source, year " + "grouping sets ((source, year), (source), (year), ())" + "order by source asc nulls last, year asc nulls last") result.show() }
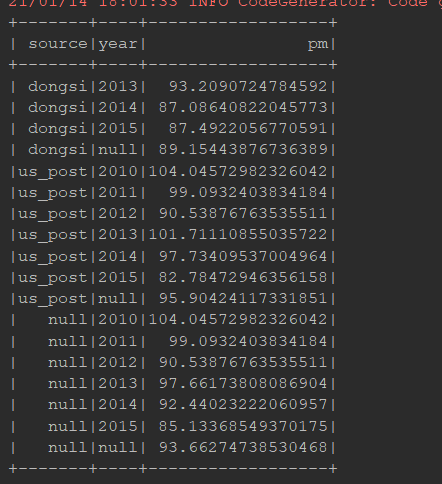
RelationalGroupedDataset
连接操作:
无类型连接算子 join 的 API
Step 1: 什么是连接
-
按照 PostgreSQL 的文档中所说, 只要能在一个查询中, 同一时间并发的访问多条数据, 就叫做连接.
做到这件事有两种方式
-
一种是把两张表在逻辑上连接起来, 一条语句中同时访问两张表
select * from user join address on user.address_id = address.id -
还有一种方式就是表连接自己, 一条语句也能访问自己中的多条数据
select * from user u1 join (select * from user) u2 on u1.id = u2.id
-
Step 2: join 算子的使用非常简单, 大致的调用方式如下
-
join(right: Dataset[_], joinExprs: Column, joinType: String): DataFrame
Step 3: 简单连接案例
-
表结构如下
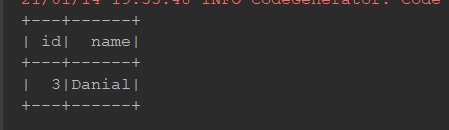
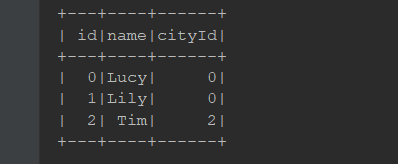
+---+------+------+ +---+---------+ | id| name|cityId| | id| name| +---+------+------+ +---+---------+ | 0| Lucy| 0| | 0| Beijing| | 1| Lily| 0| | 1| Shanghai| | 2| Tim| 2| | 2|Guangzhou| | 3|Danial| 0| +---+---------+ +---+------+------+如果希望对这两张表进行连接, 首先应该注意的是可以连接的字段, 比如说此处的左侧表
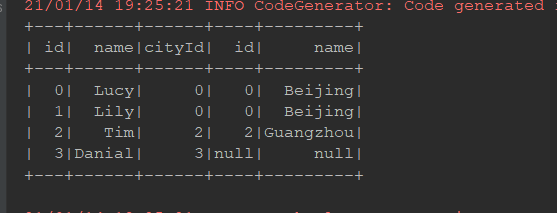
cityId和右侧表id就是可以连接的字段, 使用join算子就可以将两个表连接起来, 进行统一的查询val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 0)) .toDF("id", "name", "cityId") val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou")) .toDF("id", "name") person.join(cities, person.col("cityId") === cities.col("id")) .select(person.col("id"), person.col("name"), cities.col("name") as "city") .show() /** * 执行结果: * * +---+------+---------+ * | id| name| city| * +---+------+---------+ * | 0| Lucy| Beijing| * | 1| Lily| Beijing| * | 2| Tim|Guangzhou| * | 3|Danial| Beijing| * +---+------+---------+ */
Step 4: 什么是连接?
-
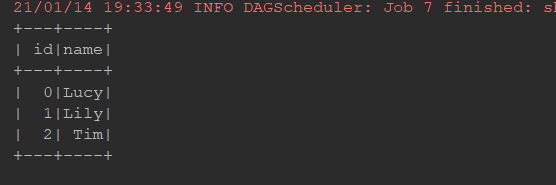
现在两个表连接得到了如下的表
+---+------+---------+ | id| name| city| +---+------+---------+ | 0| Lucy| Beijing| | 1| Lily| Beijing| | 2| Tim|Guangzhou| | 3|Danial| Beijing| +---+------+---------+通过对这张表的查询, 这个查询是作用于两张表的, 所以是同一时间访问了多条数据
spark.sql("select name from user_city where city = 'Beijing'").show() /** * 执行结果 * * +------+ * | name| * +------+ * | Lucy| * | Lily| * |Danial| * +------+ */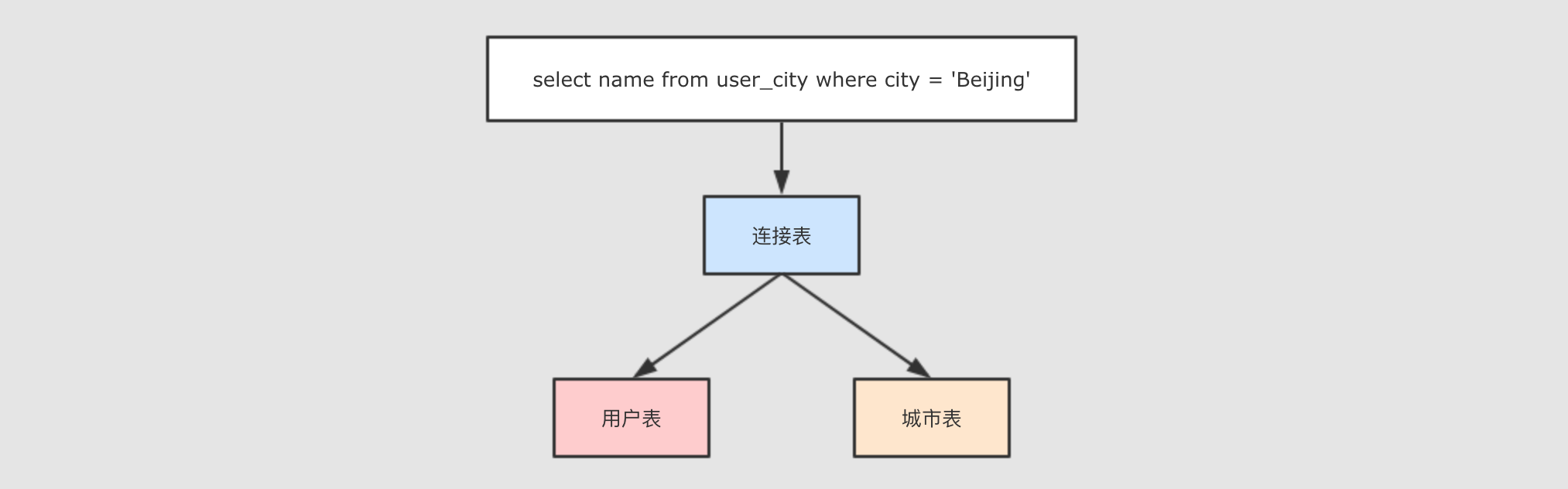
| 连接类型 | 类型字段 | 解释 |
|---|---|---|
|
交叉连接 |
|
|
|
内连接 |
|
|
|
全外连接 |
|
|
|
左外连接 |
|
|
|
|
|
|
|
|
|
|
|
右外连接 |
|
|






val spark = SparkSession.builder() .master("local[6]") .appName("join") .getOrCreate() import spark.implicits._ private val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 3)) .toDF("id", "name", "cityId") person.createOrReplaceTempView("person") private val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou")) .toDF("id", "name") cities.createOrReplaceTempView("cities") @Test def introJoin(): Unit = { val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 0)) .toDF("id", "name", "cityId") val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou")) .toDF("id", "name") val df = person.join(cities, person.col("cityId") === cities.col("id")) .select(person.col("id"), person.col("name"), cities.col("name") as "city") // .show() df.createOrReplaceTempView("user_city") spark.sql("select id, name, city from user_city where city = 'Beijing'") .show() }
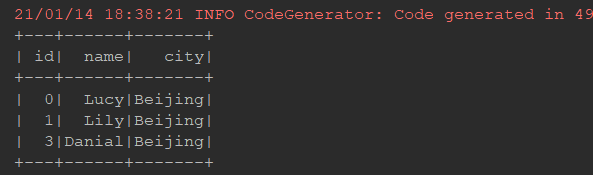
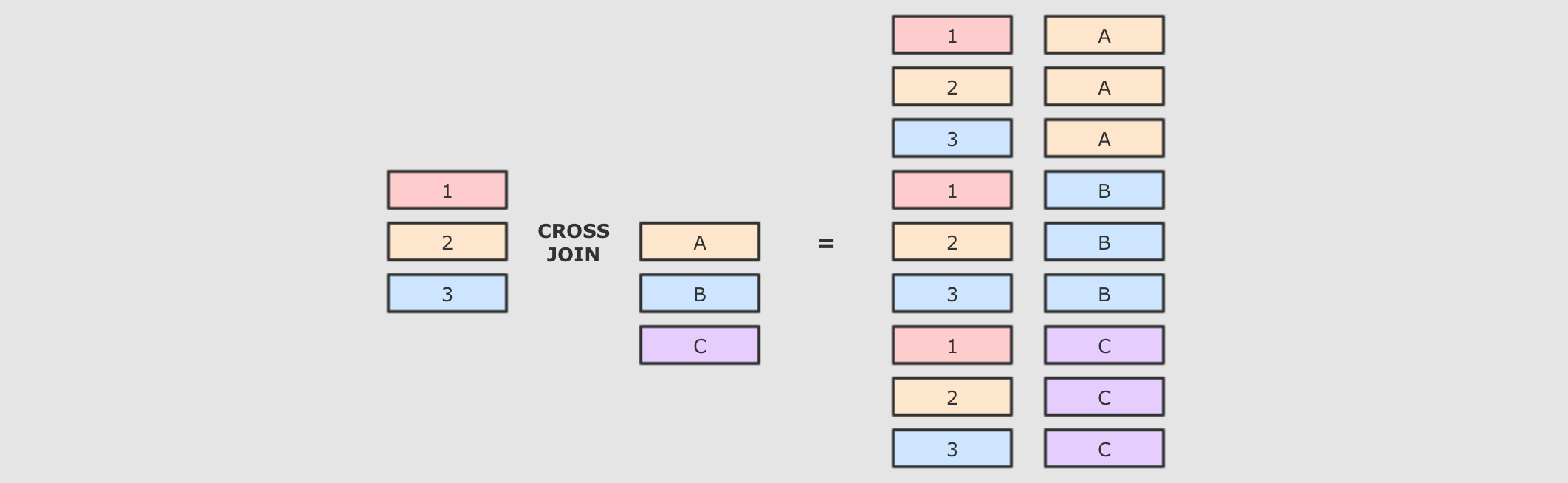
交叉连接:
@Test def crossJoin(): Unit = { person.crossJoin(cities) .where(person.col("cityId") === cities.col("id")) .show() spark.sql("select u.id, u.name, c.name from person u cross join cities c " + "where u.cityId = c.id") .show() }
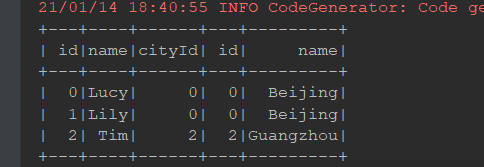
内连接:
@Test def inner(): Unit = { person.join(cities, person.col("cityId") === cities.col("id"), joinType = "inner") .show() spark.sql("select p.id, p.name, c.name " + "from person p inner join cities c on p.cityId = c.id") .show() }
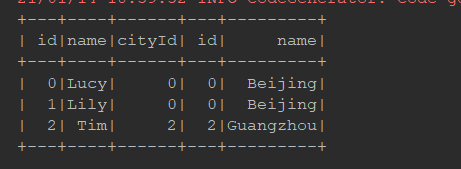
全外连接:
@Test def fullOuter(): Unit = { // 内连接, 就是只显示能连接上的数据, 外连接包含一部分没有连接上的数据, 全外连接, 指左右两边没有连接上的数据, 都显示出来 person.join(cities, person.col("cityId") === cities.col("id"), joinType = "full") .show() spark.sql("select p.id, p.name, c.name " + "from person p full outer join cities c " + "on p.cityId = c.id") .show() }
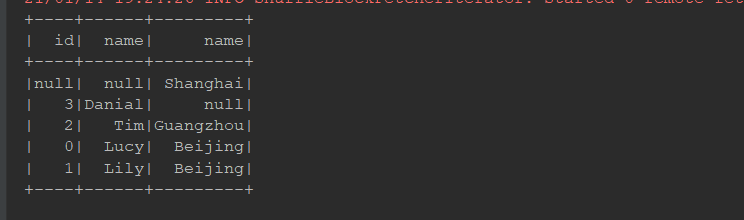
左外连接:
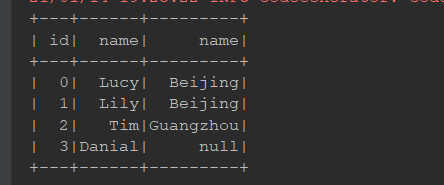
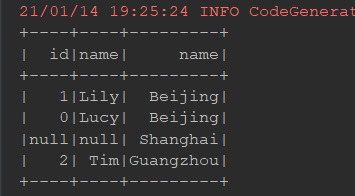
@Test def leftRight(): Unit = { // 左连接 person.join(cities, person.col("cityId") === cities.col("id"), joinType = "left") .show() spark.sql("select p.id, p.name, c.name " + "from person p left join cities c " + "on p.cityId = c.id") .show() // 右连接 person.join(cities, person.col("cityId") === cities.col("id"), joinType = "right") .show() spark.sql("select p.id, p.name, c.name " + "from person p right join cities c " + "on p.cityId = c.id") .show() }

semi和anti:
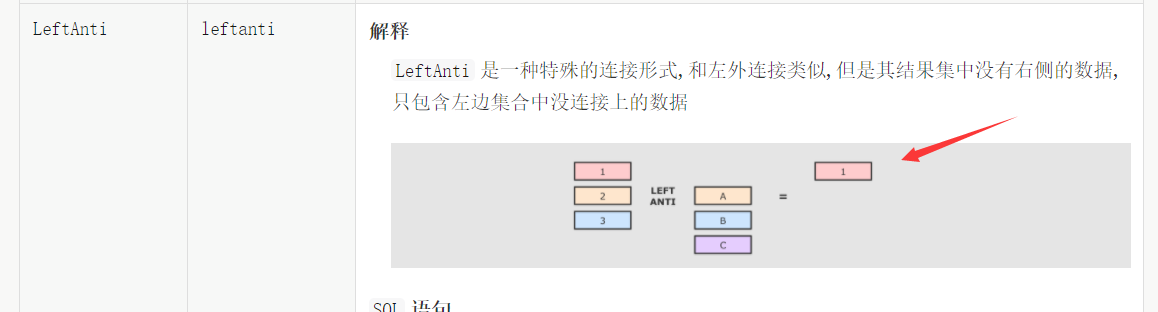

@Test def leftAntiSemi(): Unit = { // 左连接 anti person.join(cities, person.col("cityId") === cities.col("id"), joinType = "leftanti") .show() spark.sql("select p.id, p.name " + "from person p left anti join cities c " + "on p.cityId = c.id") .show() // 右连接 person.join(cities, person.col("cityId") === cities.col("id"), joinType = "leftsemi") .show() spark.sql("select p.id, p.name " + "from person p left semi join cities c " + "on p.cityId = c.id") .show() }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号