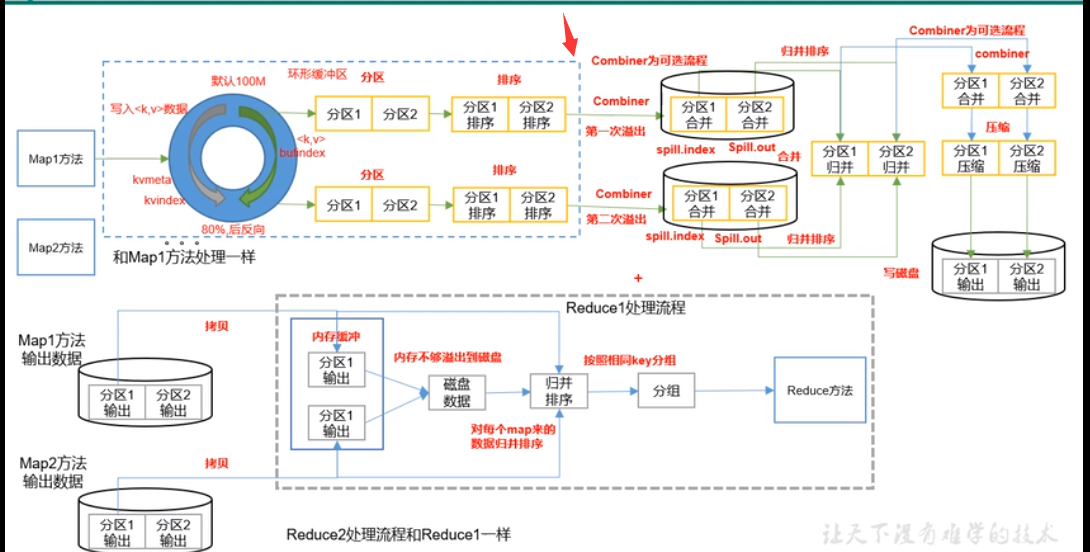
Combiner+GroupingComparator+shuffle原理+Reduce原理
1、Combiner

Combiner的输入输出对象必须一样。
2、GroupingComparator
运行代码:
map
package groupcompartor;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OrderMapper extends Mapper<LongWritable, Text,OrderBean, NullWritable> {
private OrderBean orderbean=new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fieds=value.toString().split("\t");
orderbean.setOrderId(fieds[0]);
orderbean.setProductId(fieds[1]);
orderbean.setPrice(Double.parseDouble(fieds[2]));
context.write(orderbean,NullWritable.get());
}
}
reduce
package groupcompartor;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class OrderReducer extends Reducer<OrderBean, NullWritable,OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
driver
package groupcompartor;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.logging.log4j.core.config.OrderComparator;
import java.io.IOException;
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(OrderDriver.class);
job. setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setGroupingComparatorClass(OderCompartor.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("d:\\linput"));
FileOutputFormat.setOutputPath(job,new Path("d:\\loutput"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
comparator
package groupcompartor;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OderCompartor extends WritableComparator {
protected OderCompartor() {
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean oa=(OrderBean)a;
OrderBean ob=(OrderBean)b;
return oa.getOrderId().compareTo(ob.getOrderId());
}
}
原本结果:
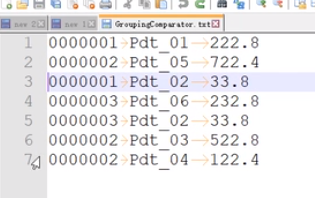
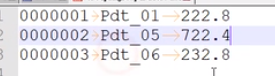
预期结果:
3.3.10 GroupingComparator分组案例实操
1.需求
有如下订单数据
表4-2 订单数据
|
订单id |
商品id |
成交金额 |
|
0000001 |
Pdt_01 |
222.8 |
|
Pdt_02 |
33.8 |
|
|
0000002 |
Pdt_03 |
522.8 |
|
Pdt_04 |
122.4 |
|
|
Pdt_05 |
722.4 |
|
|
0000003 |
Pdt_06 |
232.8 |
|
Pdt_02 |
33.8 |
现在需要求出每一个订单中最贵的商品。
(1)输入数据
(2)期望输出数据
1 222.8
2 722.4
3 232.8
3、shuffle原理
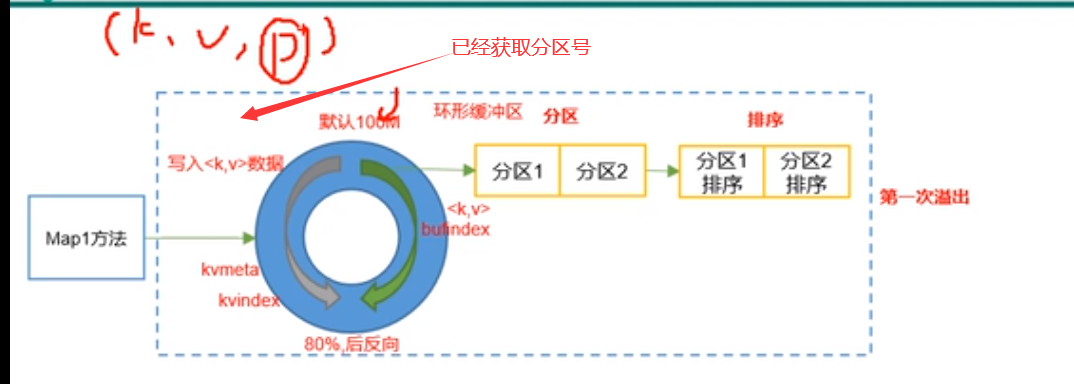


 浙公网安备 33010602011771号
浙公网安备 33010602011771号