

爬虫
随着网络的迅速发展,如何有效地提取并利用信息很大程度上决定了解决问题的效率。搜索引擎作为辅助程序员检索信息的工具已经有些力不从心。网络爬虫的出现,是为了更高效地获取指定信息需要定向抓取并分析网页资源。
~网络爬虫应用一般分为两个步骤:
1. 通过网络链接获取网页内容;
2. 对获得的网页内容进行处理;
这两个步骤分别使用不同的函数库:requests 和 beautifulsoup4 。
采用pip指令安装 requests 库:管理员打开命令行窗口 → 输入cmd → 输入 pip install requests ( besutifulsoup4 库的安装也是类似的)
但我更热衷于使用spyder,这两个库在spyder中直接使用,无需安装
• Requests 库
1. Requests 库的7个方法
|
方法 |
说明 |
|
requests.request() |
构造一个请求,支撑以下各方法的基础方法 |
|
requests.get() |
获取HTML网页的主要方法,对应于HTTP的GET |
|
requests.head() |
获取HTML网页头信息的方法,对应于HTTP的HEAD |
|
requests.post() |
向HTML网页提交POST请求的方法,对应于HTTP的POST |
|
requests.put() |
向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
|
requests.patch() |
向HTML网页提交局部修改请求,对应于HTTP的PATCH |
|
requests.delete() |
向HTML页面提交删除请求,对应于HTTP的DELETE |
2. Response对象的属性
|
属性 |
说明 |
|
r.status_code |
HTTP请求的返回状态,200表示连接成功,404表示失败 |
|
r.text |
HTTP响应内容的字符串形式,即,url对应的页面内容 |
|
r.encoding |
从HTTP header中猜测的响应内容编码方式 |
|
r. apparent_encoding |
从内容中分析出的响应内容编码方式(备选编码方式) |
|
r.content |
HTTP响应内容的二进制形式 |
|
属性 |
说明 |
|
r.status_code |
HTTP请求的返回状态,200表示连接成功,404表示失败 |
|
r.text |
HTTP响应内容的字符串形式,即,url对应的页面内容 |
|
r.encoding |
从HTTP header中猜测的响应内容编码方式 |
|
r. apparent_encoding |
从内容中分析出的响应内容编码方式(备选编码方式) |
|
r.content |
HTTP响应内容的二进制形式 |
|
r.raise_for_status() |
如果不是200,产生异常 requests.HTTPError
|
二、用 requests 库访问360搜索主页
函数说明:
| 函数名称 | 函数功能 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示连接失败 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.content | HTTP响应内容的二进制形式 |
| len() | 计算文本长度 |
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sun May 26 22:57:58 2019
@author: daydayup12138 学号07
初识爬虫
"""
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,引发异常
r.encording='utf-8'
return r
except:
return ''
for i in range (20):
url='http://www.so.com'
print('第',i+1,'次访问')
r=getHTMLText(url)
print('网络状态码:',r.status_code)
print('网页文本内容',r.text)
print('text的长度:',len(r.text))
print('content属性长度',len(r.content))
代码执行效果如下
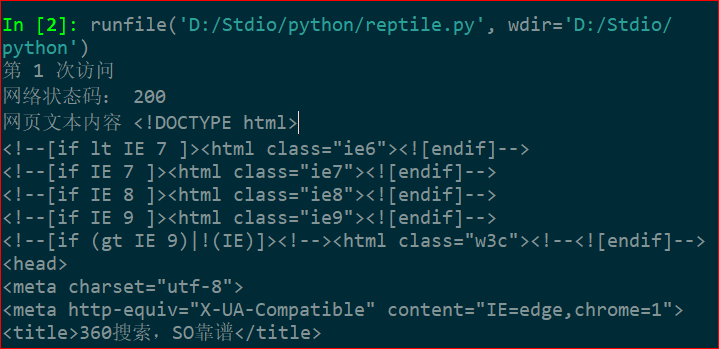

按照要求,循环访问了360搜索主页20次,由于输出结果过长,此处便不一一展示了。
如果多次访问同一网页,其 text, content 属性长度并未发生变化。
需要注意的一点是,当你频繁地运行此程序时,所访问的页面可能有反爬措施,导致输出结果异常,如:访问页面非我们输入的页面,访问时长过长等。
三、用 Beautifulsoup4 库提取网页源代码中的有效信息
下面是本次操作所访问的网页源代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<hl>我的第一个标题</hl>
<p id="first">我的第一个段落。</p>
</body>
<table border="1">
<tr>
<td>row 1, cell 1</td>
<td>row 1, cell 2</td>
</tr>
<tr>
<td>row 2, cell 1</td>
<td>row 2, cell 2</td>
<tr>
</table>
</html>
# -*- coding: utf-8 -*-
"""
Created on Mon May 27 15:52:44 2019
@author: 1
"""
# -*- coding: utf-8 -*-
"""
Created on Mon May 20 10:15:03 2019
@author: daydayup12138 07
"""
from bs4 import BeautifulSoup
html='''<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<hl>我的第一个标题</hl>
<p id="first">我的第一个段落。</p>
</body>
<table border="1">
<tr>
<td>row 1, cell 1</td>
<td>row 1, cell 2</td>
</tr>
<tr>
<td>row 2, cell 1</td>
<td>row 2, cell 2</td>
<tr>
</table>
</html>'''
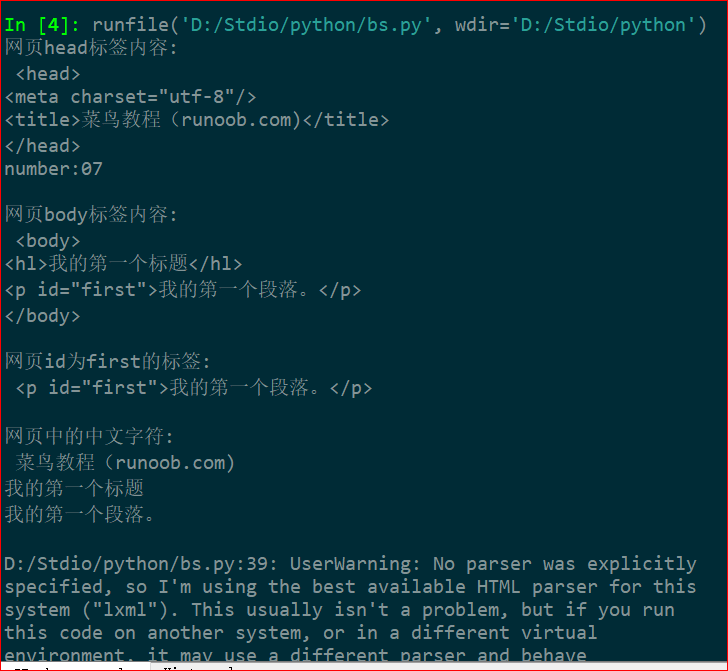
soup= BeautifulSoup(html)
print("网页head标签内容:\n",soup.head,"\nnumber:07\n")
print("网页body标签内容:\n",soup.body,"\n")
print("网页id为first的标签:\n",soup.p,"\n")
print("网页中的中文字符:\n",soup.title.string)
print(soup.hl.string)
print(soup.p.string,"\n")
输出效果
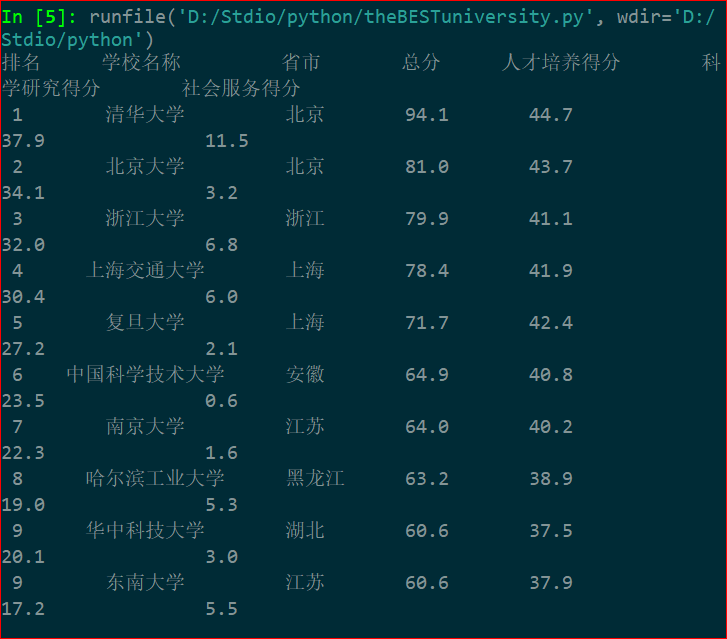
四、爬中国大学排名
以下数据均来自http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html
利用爬虫爬取2015年全国最好大学排名,代码如下:
代码执行效果如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号