
用 C# 开发一个解释器语言——基于《Crafting Interpreters》的实战系列(二)词法分析器
词法分析器
词法分析器是编译器或解释器的第一道关卡,它负责把源码字符串拆解成一个个有意义的词法单元(Token)。后续的语法分析器和解释器都会依赖这些 Token。
词法分析器(Lexical Analyzer 或 Scanner)做的事情包括:
-
从源码文本逐字符扫描
-
识别出单词、数字、符号、字符串等基本元素
-
忽略空格、注释等无关字符
-
把这些元素封装成 Token,包含类型、字面量值和所在行号
LoxSharp 词法分析器实现
1. 设计 Token 与 TokenType
我们首先定义了 TokenType 枚举,列出所有可能的词法单元类型,包括:
-
单字符符号(如
(、)、;) -
一或两个字符的操作符(如
!、!=、==) -
关键字(
var、if、print等) -
字面量类型(字符串、数字、标识符)
-
文件结尾标志(EOF)
/// <summary> /// 词法单元类型 /// </summary> public enum TokenType { // 单字符 token LEFT_PAREN, RIGHT_PAREN, LEFT_BRACE, RIGHT_BRACE, COMMA, DOT, MINUS, PLUS, SEMICOLON, SLASH, STAR, // 一或两个字符的 token,也就是运算符 BANG, BANG_EQUAL, EQUAL, EQUAL_EQUAL, GREATER, GREATER_EQUAL, LESS, LESS_EQUAL, // 字面量 IDENTIFIER, STRING, NUMBER, // 关键字 AND, CLASS, ELSE, FALSE, FUN, FOR, IF, NIL, OR, PRINT, RETURN, SUPER, THIS, TRUE, VAR, WHILE, // 文件结束 EOF } /// <summary> /// 词法单元 /// </summary> public class Token { public TokenType Type { get; } /// <summary> /// 原始 /// </summary> public string Lexeme { get; } /// <summary> /// 字面量值 /// </summary> public object Literal { get; } /// <summary> /// 源代码行号 /// </summary> public int Line { get; } public Token(TokenType type, string lexeme, object literal, int line) { Type = type; Lexeme = lexeme; Literal = literal; Line = line; } public override string ToString() { return $"{Type} {Lexeme} {Literal}"; } }
2. 核心扫描逻辑
词法分析器的核心是 Scanner 类,它维护源码字符串和当前扫描位置:
-
用指针
current遍历源码 -
用指针
start记录当前 Token 开始的位置 -
逐个字符判断 Token 类型,生成 Token 并加入列表
-
跳过空白和注释
-
处理数字、字符串、标识符和关键字
/// <summary> /// 词法分析器 /// Scanner 的职责是将一整个源代码字符串拆解为一系列 Token(词法单元) /// </summary> public class Scanner { private readonly string source; private readonly List<Token> tokens = new(); private int start = 0; private int current = 0; private int line = 1; private static readonly Dictionary<string, TokenType> keywords = new() { { "and", TokenType.AND }, { "class", TokenType.CLASS }, { "else", TokenType.ELSE }, { "false", TokenType.FALSE }, { "for", TokenType.FOR }, { "fun", TokenType.FUN }, { "if", TokenType.IF }, { "nil", TokenType.NIL }, { "or", TokenType.OR }, { "print", TokenType.PRINT }, { "return", TokenType.RETURN }, { "super", TokenType.SUPER }, { "this", TokenType.THIS }, { "true", TokenType.TRUE }, { "var", TokenType.VAR }, { "while", TokenType.WHILE } }; public Scanner(string source) { this.source = source; } public List<Token> ScanTokens() { while (!IsAtEnd()) { start = current; ScanToken(); } tokens.Add(new Token(TokenType.EOF, "", null, line)); return tokens; } private bool IsAtEnd() { return current >= source.Length; } private void ScanToken() { char c = Advance(); switch (c) { case '(': AddToken(TokenType.LEFT_PAREN); break; case ')': AddToken(TokenType.RIGHT_PAREN); break; case '{': AddToken(TokenType.LEFT_BRACE); break; case '}': AddToken(TokenType.RIGHT_BRACE); break; case ',': AddToken(TokenType.COMMA); break; case '.': AddToken(TokenType.DOT); break; case '-': AddToken(TokenType.MINUS); break; case '+': AddToken(TokenType.PLUS); break; case ';': AddToken(TokenType.SEMICOLON); break; case '*': AddToken(TokenType.STAR); break; case '!': AddToken(Match('=') ? TokenType.BANG_EQUAL : TokenType.BANG); break; case '=': AddToken(Match('=') ? TokenType.EQUAL_EQUAL : TokenType.EQUAL); break; case '<': AddToken(Match('=') ? TokenType.LESS_EQUAL : TokenType.LESS); break; case '>': AddToken(Match('=') ? TokenType.GREATER_EQUAL : TokenType.GREATER); break; case '/': if (Match('/')) { // 单行注释直到行尾 while (Peek() != '\n' && !IsAtEnd()) Advance(); } else { AddToken(TokenType.SLASH); } break; case ' ': case '\r': case '\t': // 忽略空白字符 break; case '\n': line++; break; case '"': String(); break; default: if (IsDigit(c)) { Number(); } else if (IsAlpha(c)) { Identifier(); } else { Console.WriteLine($"[Line {line}] Unexpected character: {c}"); } break; } } private char Advance() { return source[current++]; } private void AddToken(TokenType type) { AddToken(type, null); } private void AddToken(TokenType type, object literal) { string text = source.Substring(start, current - start); tokens.Add(new Token(type, text, literal, line)); } private bool Match(char expected) { if (IsAtEnd()) return false; if (source[current] != expected) return false; current++; return true; } private char Peek() { if (IsAtEnd()) return '\0'; return source[current]; } private char PeekNext() { if (current + 1 >= source.Length) return '\0'; return source[current + 1]; } private void String() { while (Peek() != '"' && !IsAtEnd()) { if (Peek() == '\n') line++; Advance(); } if (IsAtEnd()) { Console.WriteLine($"[Line {line}] Unterminated string."); return; } // Closing " Advance(); string value = source.Substring(start + 1, current - start - 2); AddToken(TokenType.STRING, value); } private void Number() { while (IsDigit(Peek())) Advance(); if (Peek() == '.' && IsDigit(PeekNext())) { Advance(); while (IsDigit(Peek())) Advance(); } double value = double.Parse(source.Substring(start, current - start)); AddToken(TokenType.NUMBER, value); } private void Identifier() { while (IsAlphaNumeric(Peek())) Advance(); string text = source.Substring(start, current - start); if (!keywords.TryGetValue(text, out TokenType type)) { type = TokenType.IDENTIFIER; } AddToken(type); } private bool IsDigit(char c) => c >= '0' && c <= '9'; private bool IsAlpha(char c) => (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_'; private bool IsAlphaNumeric(char c) => IsAlpha(c) || IsDigit(c); }
3. 运行测试示例
下面是一段简单的测试代码,展示扫描器如何工作:
class Program { static void Main(string[] args) { TestScanner(); Console.ReadKey(); } static void TestScanner() { string source = @" var language = ""LoxSharp""; print(language + "" is awesome!""); if (true) print(123);"; Scanner scanner = new Scanner(source); var tokens = scanner.ScanTokens(); foreach (var token in tokens) { Console.WriteLine(token); } } }
运行结果:
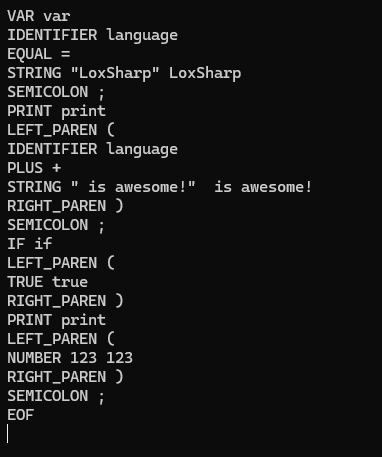
LoxSharp 的词法分析器模块。它是解析和执行的第一步,承担着将源码转换成结构化数据的重任

 浙公网安备 33010602011771号
浙公网安备 33010602011771号