spring mybatis
2018-06-22 16:05 DawnLin 阅读(178) 评论(0) 收藏 举报1.普通的JDBC加载数据库
-
加载JDBC驱动;
-
建立并获取数据库连接;
-
创建 JDBC Statements 对象;
-
设置SQL语句的传入参数;
-
执行SQL语句并获得查询结果;
-
对查询结果进行转换处理并将处理结果返回;
-
释放相关资源(关闭Connection,关闭Statement,关闭ResultSet)
MyBatis 编程步骤
- 创建 SqlSessionFactory
- 通过 SqlSessionFactory 获取 SqlSession
- 通过 SqlSession 执行数据库操作
- 提交事务
- 关闭会话
1、 连接池,问题:连接池多样;解决:DataSource隔离解耦,统一从DataSource里面获取数据库连接,DataSource具体由DBCP实现还是由容器的JNDI实现都可以
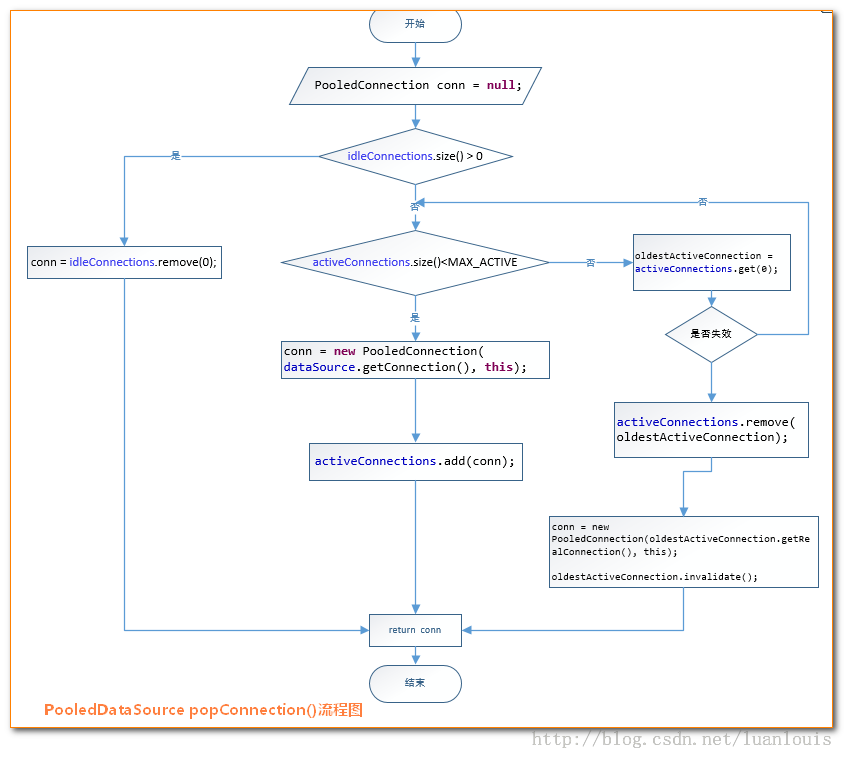
- 先看是否有空闲(idle)状态下的PooledConnection对象,如果有,就直接返回一个可用的PooledConnection对象;否则进行第2步。
- 查看活动状态的PooledConnection池activeConnections是否已满;如果没有满,则创建一个新的PooledConnection对象,然后放到activeConnections池中,然后返回此PooledConnection对象;否则进行第三步;
- 看最先进入activeConnections池中的PooledConnection对象是否已经过期:如果已经过期,从activeConnections池中移除此对象,然后创建一个新的PooledConnection对象,添加到activeConnections中,然后将此对象返回;否则进行第4步。
- 线程等待,循环2步
2、 Sql语句在代码中硬编码,造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。问题:可读性差,改动java代码需要重新编译,打包,在SQL端执行不方便。
解决,抽离sql语句,统一放在配置文件中。涉及到传入参数映射和动态SQL
3、 对结果集解析存在硬编码(查询列名),sql变化导致解析代码变化,系统不易维护,如果能将数据库记录封装成pojo对象解析比较方便。
2.关于Mybatis的结构
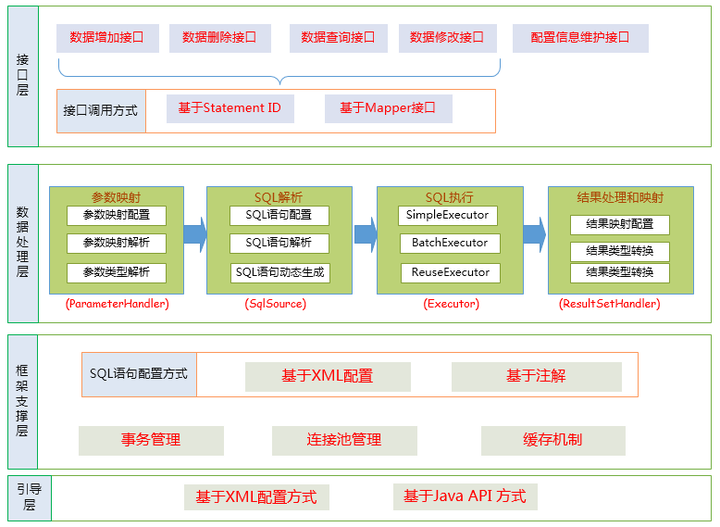
Mybatis 和数据库的交互方式:1.使用传统的MyBatis提供的API; 2.使用Mapper接口


spring-mybatis 是怎么动态生成mapper 代理类的
1.启动时加载解析mapper的xml ;2.然后绑定namespace(XMLMapperBuilder) 3.生成该mapper的代理工厂(MapperRegistry) 4.getMapper的时候生成mapper代理类 5. new MapperProxy实现InvocationHandler接口进行拦截代理
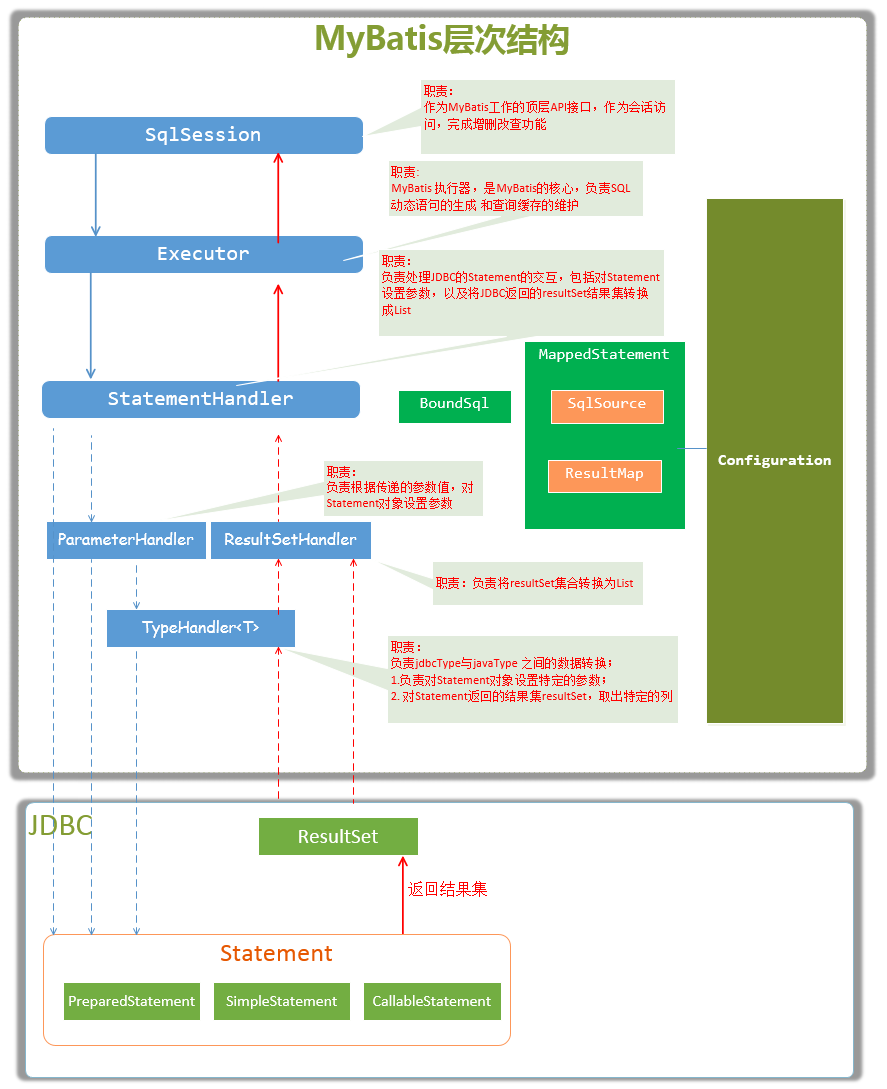
SqlSession:作为MyBatis工作的主要顶层API,表示和数据库交互的会话,完成必要数据库增删改查功能;
Executor:MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护;
StatementHandler:封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合。
ParameterHandler:负责对用户传递的参数转换成JDBC Statement 所需要的参数;
ResultSetHandler:负责将JDBC返回的ResultSet结果集对象转换成List类型的集合;
TypeHandler:负责java数据类型和jdbc数据类型之间的映射和转换;
MappedStatement:MappedStatement维护了一条<select|update|delete|insert>节点的封装;
SqlSource:负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回;
BoundSql:表示动态生成的SQL语句以及相应的参数信息;
Configuration:MyBatis所有的配置信息都维持在Configuration对象之中;
2.5、缓存
缓存是MyBatis里比较重要的部分,有两种缓存:SESSION或STATEMENT作用域级别的缓存,默认是SESSION,BaseExecutor中根据MappedStatement的Id、SQL、参数值以及rowBound(边界)来构造CacheKey,并使用BaseExccutor中的localCache来维护此缓存。
- 全局的二级缓存,通过CacheExecutor来实现,其委托TransactionalCacheManager来保存/获取缓存,这个全局二级缓存比较复杂,后面还需要专题分析,至于其缓存的效率以及应用场景也留到那时候再分析。
一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。Mybatis默认开启一级缓存。简单的使用HashMap来存储
![]()
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession去操作数据库得到数据会存在二级缓存区域,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。 二级缓存是多SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。Mybatis默认没有开启二级缓存需要在setting全局参数中配置开启二级缓存。
![]() 需要解决的问题,1。查询 select *from A join B 2。 update from B ,需要改变1关联的namespace的cache
需要解决的问题,1。查询 select *from A join B 2。 update from B ,需要改变1关联的namespace的cache![]()

 需要解决的问题,1。查询 select *from A join B 2。 update from B ,需要改变1关联的namespace的cache
需要解决的问题,1。查询 select *from A join B 2。 update from B ,需要改变1关联的namespace的cache
Mybatis 和 Hibernate 的 区别
总体来说 mybatis 和 hibernate 都属于持久层框架。就目前主流的 ORM 框架而言,hibernate 数据全自动 ORM 实现,而 mybatis 属于半自动 ORM 实现。他们最直观的区别在于:
hibernate 完整的实现了对象到数据库结构的映射,也就是说在使用 hibernate 的时候,你可以不需要关心数据库结构,而仅仅只用知道数据库结构对应的对象即可,hibernate 提供了一系列的操作使你所有的数据库操作转换成对象的操作,而 hibernate 在执行操作的时候会自动的帮你生成对应的 sql 并执行,并把返回的结果集封装成对应的对象返回。
而 mybatis 在实现是仅仅是对结果集进行了对象的封装返回,而执行的 sql 需要开发人员自己去实现。
虽然 hibernate 是全自动 ORM 框架,但是在某些情况下并不是那么好用,比如:
- 在某些情况下,数据库权限没有全部开放,只能执行部分 sql 操作的时候。
- 数据库查询操作十分繁琐,sql 执行很复杂,为了提供效率,需要对 sql 进行优化。
- 数据库查询需要用到存储过程时。
等等以上情况在使用 hibernate 时就不能应付了。这时使用 mybatis 则是一个不错的选择。但是如果存在多数据库访问的情况下,hibernate 会是一个更好的选择,而 mybatis 在操作多数据库时,同一个数据库操作需要实现不同的 sql。
实际项目关于Hibernate和Mybatis的选型:
1、数据量:有以下情况最好选用Mybatis
如果有超过千万级别的表
如果有单次业务大批量数据提交的需求(百万条及以上的),这个尤其不建议用Hibernate
如果有单次业务大批量读取需求(百万条及以上的)(注,hibernate多表查询比较费劲,用不好很容易造成性能问题)
2、表关联复杂度
如果主要业务表的关联表超过20个(大概值),不建议使用hibernate
3、人员
如果开发成员多数不是多年使用hibernate的情况,建议使用mybatis
4、数据库对于项目的重要程度
如果项目要求对于数据库可控性好,可深度调优,用mybatis
7.20更新:
关于Executor的选择 核心
Mybatis中所有的Mapper语句的执行都是通过Executor进行的,Executor是Mybatis的一个核心接口。Executor接口的实现类有BaseExecutor和CachingExecutor,而BaseExecutor的子类又有SimpleExecutor、ReuseExecutor和BatchExecutor,但BaseExecutor是一个抽象类,其只实现了一些公共的封装,而把真正的核心实现都通过方法抽象出来给子类实现,如doUpdate()、doQuery();CachingExecutor只是在Executor的基础上加入了缓存的功能,底层还是通过Executor调用的,所以真正有作用的Executor只有SimpleExecutor、ReuseExecutor和BatchExecutor。它们都是自己实现的Executor核心功能,没有借助任何其它的Executor实现,它们是实现不同也就注定了它们的功能也是不一样的。Executor是跟SqlSession绑定在一起的,每一个SqlSession都拥有一个新的Executor对象,由Configuration创建。
1.SimpleExecutor是Mybatis执行Mapper语句时默认使用的Executor。它提供最基本的Mapper语句执行功能,没有过多的封装的。
Mybatis里默认的ExecutorType就是Simple, 在类org.apache.ibatis.session.Configuration里可以看到初始化属性
protected ExecutorType defaultExecutorType = ExecutorType.SIMPLE;
2.ReuseExecutor,顾名思义,是可以重用的Executor。它重用的是Statement对象,它会在内部利用一个Map把创建的Statement都缓存起来,每次在执行一条SQL语句时,它都会去判断之前是否存在基于该SQL缓存的Statement对象,存在而且之前缓存的Statement对象对应的Connection还没有关闭的时候就继续用之前的Statement对象,否则将创建一个新的Statement对象,并将其缓存起来。因为每一个新的SqlSession都有一个新的Executor对象,所以我们缓存在ReuseExecutor上的Statement的作用域是同一个SqlSession。
3.BatchExecutor的设计主要是用于做批量更新操作的。其底层会调用Statement的executeBatch()方法实现批量操作。
日常中的调试,如果是SQL语句的问题,请移步类org.apache.ibatis.executor.SimpleExecutor, 打个断点把SQL语句拷贝出来然后去数据库跑一下。
如果选出来的数据没问题,那剩下的大致应该是ResultMap的设置问题。
https://blog.csdn.net/clementad/article/details/46928621

字节码精简:优化代码,直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
- 优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
- 自定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
- 自定义集合类型(ConcurrentBag):提高并发读写的效率;
- 其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究(但没说具体怎么优化)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号