传统的大数据处理方式一般是批处理式的,也就是说,今天所收集的数据,我们明天再把今天收集到的数据算出来,以供大家使用,但是在很多情况下,数据的时效性对于业务的成败是非常关键的。
Spark 和 Flink 都是通用的开源大规模处理引擎,目标是在一个系统中支持所有的数据处理以带来效能的提升。两者都有相对比较成熟的生态系统。是下一代大数据引擎最有力的竞争者。
Spark 的生态总体更完善一些,在机器学习的集成和易用性上暂时领先。
Flink 在流计算上有明显优势,核心架构和模型也更透彻和灵活一些。
本文主要通过实例来分析flink的流式处理过程,并通过源码的方式来介绍流式处理的内部机制。
DataStream整体概述

主要分5部分,下面我们来分别介绍:
1.运行环境StreamExecutionEnvironment
StreamExecutionEnvironment是个抽象类,是流式处理的容器,实现类有两个,分别是
LocalStreamEnvironment:
RemoteStreamEnvironment:
/** * The StreamExecutionEnvironment is the context in which a streaming program is executed. A * {@link LocalStreamEnvironment} will cause execution in the current JVM, a * {@link RemoteStreamEnvironment} will cause execution on a remote setup. * * <p>The environment provides methods to control the job execution (such as setting the parallelism * or the fault tolerance/checkpointing parameters) and to interact with the outside world (data access). * * @see org.apache.flink.streaming.api.environment.LocalStreamEnvironment * @see org.apache.flink.streaming.api.environment.RemoteStreamEnvironment */
2.数据源DataSource数据输入
包含了输入格式InputFormat
/** * Creates a new data source. * * @param context The environment in which the data source gets executed. * @param inputFormat The input format that the data source executes. * @param type The type of the elements produced by this input format. */ public DataSource(ExecutionEnvironment context, InputFormat<OUT, ?> inputFormat, TypeInformation<OUT> type, String dataSourceLocationName) { super(context, type); this.dataSourceLocationName = dataSourceLocationName; if (inputFormat == null) { throw new IllegalArgumentException("The input format may not be null."); } this.inputFormat = inputFormat; if (inputFormat instanceof NonParallelInput) { this.parallelism = 1; } }
flink将数据源主要分为内置数据源和第三方数据源,内置数据源有 文件,网络socket端口及集合类型数据;第三方数据源实用Connector的方式来连接如kafka Connector,es connector等,自己定义的话,可以实现SourceFunction,封装成Connector来做。
3.DataStream转换
DataStream:同一个类型的流元素,DataStream可以通过transformation转换成另外的DataStream,示例如下
@link DataStream#map
@link DataStream#filter
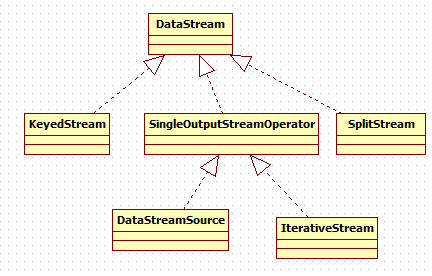
StreamOperator:流式算子的基本接口,三个实现类
AbstractStreamOperator:
OneInputStreamOperator:
TwoInputStreamOperator:
/** * Basic interface for stream operators. Implementers would implement one of * {@link org.apache.flink.streaming.api.operators.OneInputStreamOperator} or * {@link org.apache.flink.streaming.api.operators.TwoInputStreamOperator} to create operators * that process elements. * * <p>The class {@link org.apache.flink.streaming.api.operators.AbstractStreamOperator} * offers default implementation for the lifecycle and properties methods. * * <p>Methods of {@code StreamOperator} are guaranteed not to be called concurrently. Also, if using * the timer service, timer callbacks are also guaranteed not to be called concurrently with * methods on {@code StreamOperator}. * * @param <OUT> The output type of the operator */
4.DataStreamSink输出
/** * Adds the given sink to this DataStream. Only streams with sinks added * will be executed once the {@link StreamExecutionEnvironment#execute()} * method is called. * * @param sinkFunction * The object containing the sink's invoke function. * @return The closed DataStream. */ public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) { // read the output type of the input Transform to coax out errors about MissingTypeInfo transformation.getOutputType(); // configure the type if needed if (sinkFunction instanceof InputTypeConfigurable) { ((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig()); } StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction)); DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator); getExecutionEnvironment().addOperator(sink.getTransformation()); return sink; }
5.执行
/** * Executes the JobGraph of the on a mini cluster of ClusterUtil with a user * specified name. * * @param jobName * name of the job * @return The result of the job execution, containing elapsed time and accumulators. */ @Override public JobExecutionResult execute(String jobName) throws Exception { // transform the streaming program into a JobGraph StreamGraph streamGraph = getStreamGraph(); streamGraph.setJobName(jobName); JobGraph jobGraph = streamGraph.getJobGraph(); jobGraph.setAllowQueuedScheduling(true); Configuration configuration = new Configuration(); configuration.addAll(jobGraph.getJobConfiguration()); configuration.setString(TaskManagerOptions.MANAGED_MEMORY_SIZE, "0"); // add (and override) the settings with what the user defined configuration.addAll(this.configuration); if (!configuration.contains(RestOptions.BIND_PORT)) { configuration.setString(RestOptions.BIND_PORT, "0"); } int numSlotsPerTaskManager = configuration.getInteger(TaskManagerOptions.NUM_TASK_SLOTS, jobGraph.getMaximumParallelism()); MiniClusterConfiguration cfg = new MiniClusterConfiguration.Builder() .setConfiguration(configuration) .setNumSlotsPerTaskManager(numSlotsPerTaskManager) .build(); if (LOG.isInfoEnabled()) { LOG.info("Running job on local embedded Flink mini cluster"); } MiniCluster miniCluster = new MiniCluster(cfg); try { miniCluster.start(); configuration.setInteger(RestOptions.PORT, miniCluster.getRestAddress().get().getPort()); return miniCluster.executeJobBlocking(jobGraph); } finally { transformations.clear(); miniCluster.close(); } }
6.总结
Flink的执行方式类似于管道,它借鉴了数据库的一些执行原理,实现了自己独特的执行方式。
7.展望
Stream涉及的内容还包括Watermark,window等概念,因篇幅限制,这篇仅介绍flink DataStream API使用及原理。
下篇将介绍Watermark,下下篇是windows窗口计算。
参考资料
【1】https://baijiahao.baidu.com/s?id=1625545704285534730&wfr=spider&for=pc

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号