大家都对电商的商品查询并不陌生,比如我们想根据商品名称查询所有商品信息。

有些技术的童鞋第一念头是搜索引擎;有些技术的童鞋第一念头是模糊查询,如like?(如果商品信息存放到mysql里,我们一般使用like查询)
我们都知道,不同的场景决定了不同技术的使用场景也不同,那我们该如何选择呢?
那我们先做个实验吧(实验对象是mysql 8.0 community 版,windows10)
1.安装mysql 8.0 community 版本 https://dev.mysql.com/downloads/windows/installer/8.0.html
我使用的web版本 step by step
2.安装客户端SQLyog MySQ https://www.cr173.com/soft/22147.html
3 连接mysql 报错:
SQLyog连接报错 Error No.2058 Plugin caching_sha2_password could not be loaded
解决方法:windows 下cmd 登录 mysql -u root -p 登录你的 mysql 数据库,然后 执行这条SQL:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
#password 是你自己设置的root密码
4.插入数据
依赖包:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
程序

public void mysqlOneByOneInsert() {
// JDBC 驱动名及数据库 URL
String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";
String DB_URL = "jdbc:mysql://localhost:3306/www?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=false";//链接的mysql
// 数据库的用户名与密码,需要根据自己的设置
String USER = "root";
String PASS = "wangwei456";
try {
long start=System.currentTimeMillis();
Class.forName(JDBC_DRIVER);
Connection connection = DriverManager.getConnection(DB_URL, USER, PASS);
PreparedStatement stmt = connection.prepareStatement("INSERT INTO PERSON(ID,NAME,AGE,ADDRESS,SALARY) values(?,?,?,?,?);");
for(int i=0;i<1000000;i++) {
stmt.setInt(1, i+1);
stmt.setString(2, "mkyong"+i);
stmt.setInt(3, i%100);
stmt.setString(4, "address"+i);
stmt.setFloat(5, 25000.00f);
stmt.executeUpdate();
}
stmt.close();
connection.close();
System.out.println("耗时:"+(System.currentTimeMillis()-start)+" 毫秒");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
中间报错:
java.sql.SQLException: The server time zone value '???ú±ê×??±??' is unrecognized or represents more
解决方法:
在jdbc连接的url后面加上serverTimezone=GMT即可解决问题,如果需要使用gmt+8时区,需要写成GMT%2B8
感受:mysql输入插入速度(单条)简直是龟速呀 耗时:4390167 毫秒=4390秒=73分钟
1.精确查询 无索引
SELECT * FROM PERSON WHERE NAME='mkyong99999'
耗时:0.747秒
2.模糊查询 无索引
SELECT * FROM PERSON WHERE NAME LIKE 'mkyong99999%'
查询耗时:0.732秒
3.精确查询 有索引
SELECT * FROM PERSON WHERE NAME='mkyong99999'
耗时:0.01秒
4.模糊查询 有索引
FLUSH TABLES; SELECT * FROM PERSON WHERE NAME LIKE 'mkyong99999%'
耗时:0.02秒
是不是很惊诧?看看执行计划

走的是索引。和很多人的常识是相反的。
5.无索引
SELECT * FROM PERSON WHERE ADDRESS='杭州大街100号99999'
耗时 0.911秒
6.无索引
FLUSH TABLES; SELECT * FROM PERSON WHERE ADDRESS LIKE '杭州大街100号99999'
耗时0.775秒
7.有索引
FLUSH TABLES; SELECT * FROM PERSON WHERE ADDRESS='杭州大街100号99999' SELECT * FROM PERSON WHERE ADDRESS LIKE '杭州大街100号99999'
都是0.01秒
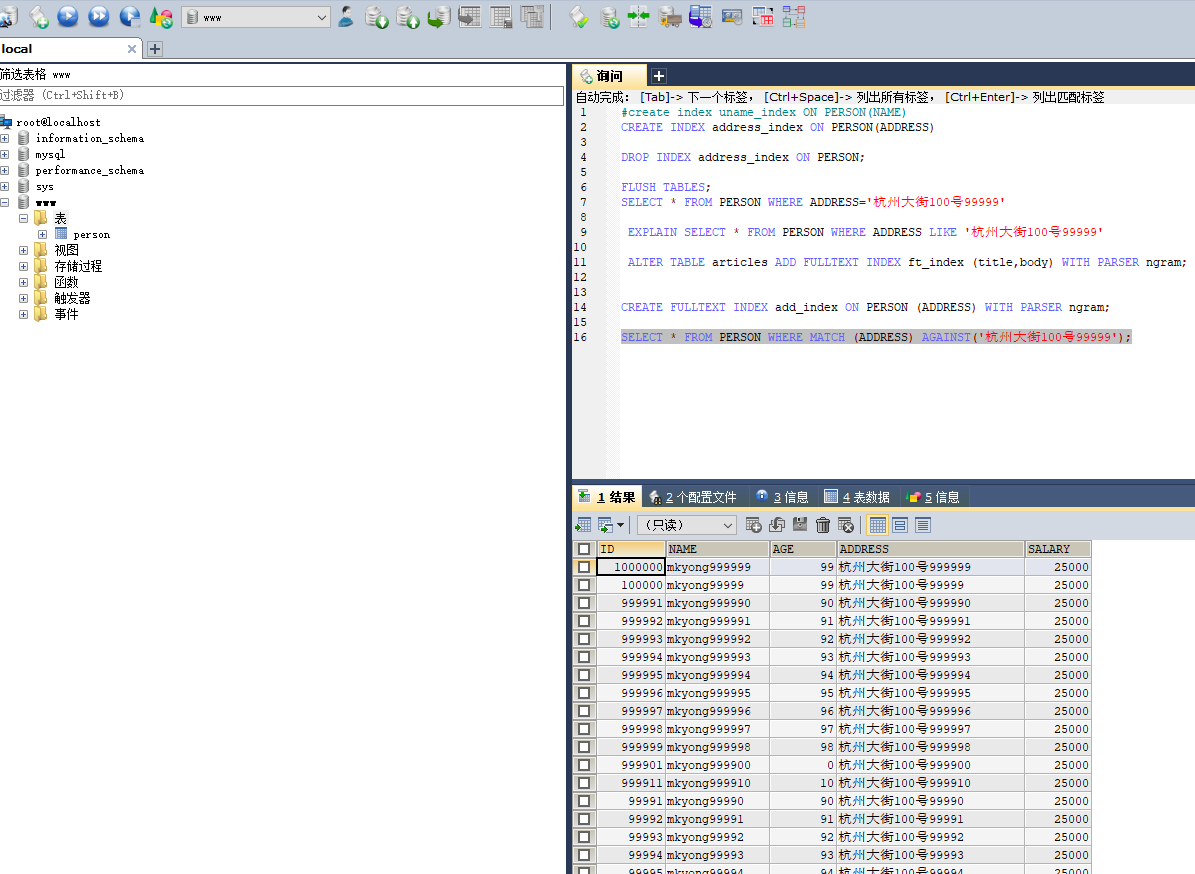
8.针对有些字段比较长,使用模糊查询会慢的问题,mysql 从5.6后提供了全文检索功能,以5.8为例 <https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html>
ngram Full-Text Parser提供了分词的功能
创建全文索引
CREATE FULLTEXT INDEX add_index ON PERSON (ADDRESS) WITH PARSER ngram;
查询
SELECT * FROM PERSON WHERE MATCH (ADDRESS) AGAINST('杭州大街100号99999');
耗时:23秒
小结:
1.like查询不一定不走索引,以实验验证为准
2.商品量或者数据量比较小的情况下(通常100w以下),like查询并不慢。
3.搜索引擎在千万,亿级别或者以上起到的作用才会比较明显,下篇会继续分析。
4.mysql提供的全文索引的使用还是在掌握的情况下再使用,否则反而会影响系统性能
参考文献:
【1】https://blog.csdn.net/jared456/article/details/80380853
【2】https://blog.csdn.net/weixin_37577564/article/details/80329775

微信公众号: 架构师日常笔记 欢迎关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号