

暴力匹配(数据思维赛-安全文本信息抽取)
训练集有四列数据:
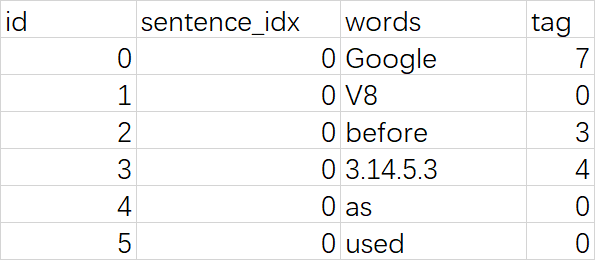
id为序号,sentence_idx为语句的序号,words为从一条语句中解析出的单词,tag为每个word对应的tag标签。
test集给出前三列数据,求每一个word对应的tag数据。
经过观察,发现训练集和测试集有大量的重复数据,所以尝试使用硬匹配的方式给出一份数据:
1 import pandas as pd 2 import time 3 4 train_data = pd.read_csv('train.csv',converters={i: str for i in range(0, 100)}) 5 test_data = pd.read_csv('test.csv',converters={i: str for i in range(0, 100)}) 6 7 train_words = train_data['words'].values.tolist() 8 train_tag = train_data['tag'].values.tolist() 9 test_words = test_data['words'].values.tolist() 10 11 pred=[] 12 time_start=time.time() 13 for i in range(len(test_words)): 14 if i%10000==0: 15 print("***结束查找 ",i," 个") 16 time_end=time.time() 17 print("---执行了 ",time_end - time_start," 秒\n") 18 time_start=time.time() 19 x=test_words[i].lower() 20 if x in train_words: 21 j=train_words.index(x) 22 pred.append(train_tag[j]) 23 else: 24 pred.append(str(0)) 25 26 test_data['tag']=pred 27 28 #test_data = pd.DataFrame({'id': test_data['id'], 'tag': pred}) 29 test_data.to_csv('result.csv', index=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号