



数据库常用编码和压缩算法介绍
在设计一个优秀的数据库时,存储空间、性能以及资源占用无疑是必须深入考虑的关键因素。这些因素直接关联到数据库的效率、成本以及用户的体验。这里面,编码与压缩也是至关重要的一环。
本文介绍压缩和编码的常用算法,帮助您在使用数据库的时候根据自己的数据表和数据列选择合适的编码格式,优化数据存储结构,节省存储空间,提高数据的读取和查询性能。
1. 编码
1.1 什么是编码?
工作中经常要将图片转成 BASE64 格式方便传输与存储,又或者需要处理音视频减少文件大小,从而提升传输效率,有的时候还会加密数据保障安全。这些都是编码。
维基百科对编码的定义是这样的:编码是信息从一种形式或格式转换为另一种形式的过程;解码则是编码的逆过程。
这种信息转化的过程,一般都会伴随着空间的减少。比如,使用数据字典将一个城市字符串“Beijing”编码映射成 11,存储空间可能就减少了一半。又因为在数据的扫描处理上,字符串的处理时间可能是数字的 2-3 倍以上,所以,如果要对比字段或者给字段排序,那使用数字的性能也全面优于使用字符串,查询性能能够得到较大的提升。
1.2 常见的编码算法
1.2.1 RLE(Run Length Encoding)
RLE算法将连续相同的数据序列编码为“重复次数 + 数据值”组合的形式,以节省存储空间。
比如给定字符串 “AABBBCCCCDDDDD”,经过 RLE 编码后变成了 “2A3B4C5D”。在压缩后的字符串中,RLE 将连续的 “AA” 替换为 “2A”,连续的 “BBB” 替换为 “3B”,连续的 “CCCC” 替换为 “4C”,以此类推。这样,RLE 就压缩了原始字符串,减少了重复字符的存储。
这种编码算法适合用在重复数据较多的场景,比如对图像数据的编码。 因为图像数据通常用 RGB 表示,如(255,0,0)。而图像相邻位置的像素值比较接近,RGB 对应的值相同,比如 [255,0,0;255,0,0;255,0,0;255,0,1;255,0,1 …],那么使用 RLE 就可以表示为 [3:255,0,0; 2:255,0,1],大大减少存储的数据大小。
1.2.2 Delta Encoding
Delta Encoding 是一个基于数值增量的编码算法,它会将数据转换为增量值进行存储,节省存储空间,也可以加快数据的查询速度。
举个例子,给定一个整数的数据序列 a = [10, 14, 18, 22, 26],经过 Delta Encoding 编码后得到的结果是 a’ = [10, 4, 4, 4, 4]。
这里编码的逻辑是,第一个数值保持不变,后续的数值用相对于前一个数值的增量值来表示。因此,原始数据序列中的 [10, 14, 18, 22, 26] 就被转换为 Delta Encoding 后的增量序列 [10, 4, 4, 4, 4]。
这种编码算法并非只能针对数值数据来进行编码。
HBase 里面使用的 Delta Encoding 系列算法,PREFIX、DIFF、FAST_DIFF 等,也能够支持对字符串数据的编码。 用 PREFIX(由 PrefixKeyDeltaEncoder 实现)举个例子。如下图所示,图的上半部分表示一个存储了 4 行数据的表,这个表的行键由两部分组成。
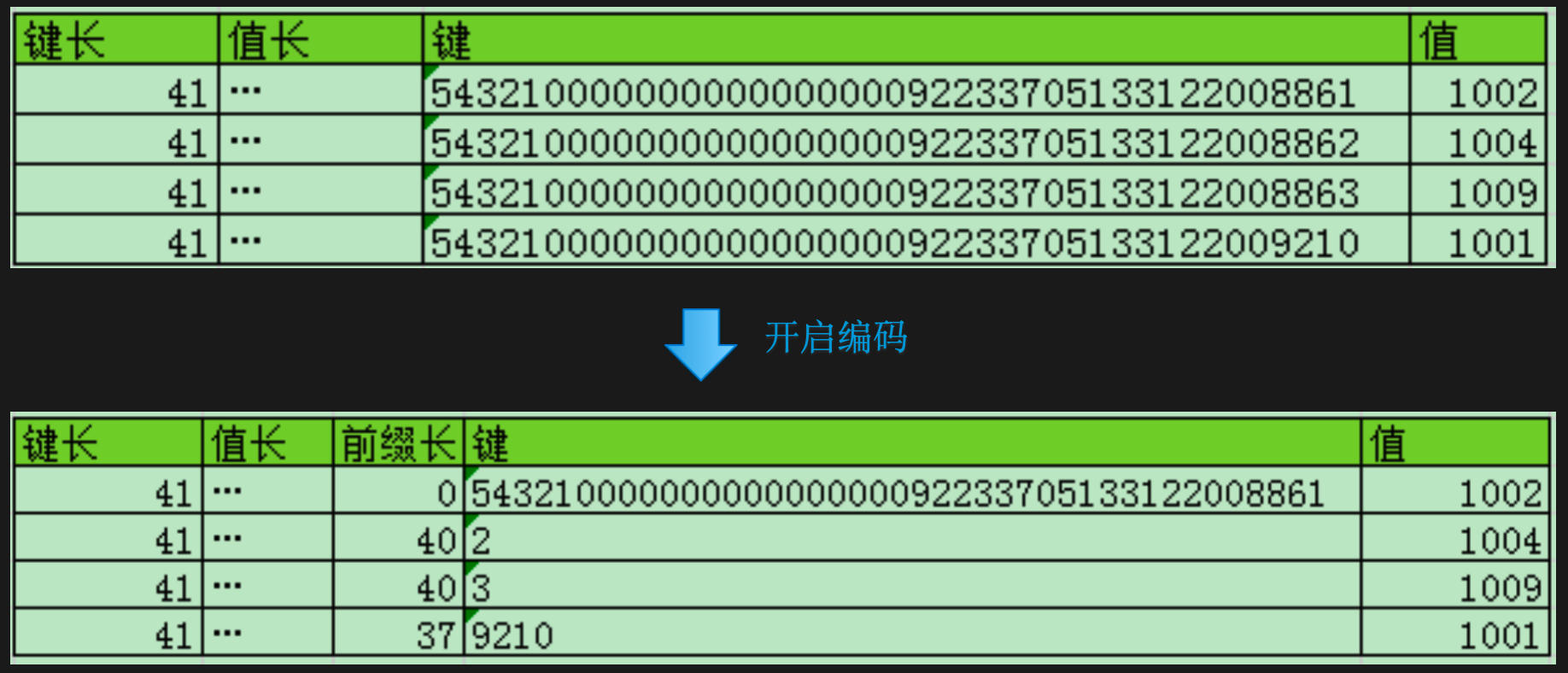
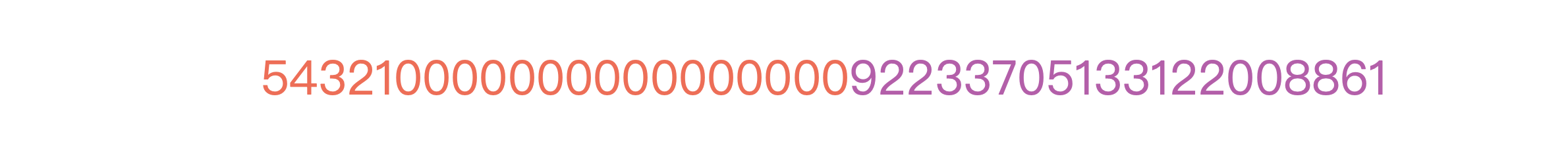
第一部分是将用户 ID 反转后补齐 20 位获得的,即行键中的红色部分。这个处理是为了避免热点区间,因为用户 ID 一般是连续的整数,而新用户一般比较活跃,产生的数据较多,所以反转后能够避免连续的新用户全部分到同一个分区或者服务器。
第二部分是一个用 Long.MAX_VALUE 减去当前时间戳,得到的值再补齐 20 位,即行键中的紫色部分。保证得到一个定长的行键,就能方便我们从行键中提取数据,而且最新的数据会排在前面。
再看图的下半部分,是开启编码后存储的数据示例。可以看到,表格里多存储了一列前缀长度,但是行键的位数大大减少了。具体怎么做到的呢?
第 2 行的前缀长 40,表示第 2 行行键的前 40 位跟第 1 行的行键全部一样,只有最后 1 位的 2 跟第 1 行行键不一样。第 3 行行键同样也是只有最后一位 3 跟前一个行键不一样。第 4 行的行键跟前面几行相比,前面 37 位都一样,只有最后 4 位不一样,那就只需要把最后不一样的 4 位存到数据块。
也就是说,如果单从键的长度大小来看,差不多压缩了 60%-70% 的存储空间。 所以,Delta Encoding 特别适合这种按字典序排序的键、值类数据的压缩。比如 HBase 按行键字典序排序。在时序数据库中,数据以时间戳为 key,这些 key 按顺序递增,同时按顺序排列存储。
HBase 默认是没有开启编码的,下面这个建表语句是在 HBase 表中使用 FAST_DIFF 编码的方法。
CREATE 't1', {NAME => 'cf1', DATA_BLOCK_ENCODING => 'FAST_DIFF'}
1.2.3 字典编码(Dictionary Encoding)
字典编码需要构建一个字典表,将数据值映射为字典索引进行存储,减少数据的存储空间,提高压缩比。
比如我们先构建一个城市的字典表,将城市映射成为一个数字,之后在表数据存储时,针对城市的列,我们只需要存储城市的数字编码即可。
字典表:
| 城市 | 编码 |
|---|---|
| 广州市 | 10 |
| 珠海市 | 11 |
| 佛山市 | 12 |
数据表:
| 姓名 | 年龄 | 城市 |
|---|---|---|
| 张三 | 21 | 11 |
| 李四 | 24 | 12 |
使用字典编码一方面可以节省存储空间,另一方面,如果需要根据城市去过滤查询,使用数字过滤的性能也比字符串要高。
字典编码适合低基数的列,也就是列的 distinct 取值较少的场景。当然,在分布式数据库中,还要考虑字典的全局性与唯一性,以免出现不同节点字典不一致导致数据不一致的情况。StarRocks 就是通过全局字典来解决这个问题的。也就是用一个统一的全局字典来统一所有节点的用来编码的字典表。
总结一下,各种编码方式只要是在合适的场景下使用,就都能节省一定的存储空间,有时候还能提升查询过滤的性能。而且,由于编码后占用空间减小,所以缓存到内存的数据量也变得更多了,同样能够提升性能,但带来的问题就是占用更多的 CPU 资源。
2. 压缩
2.1 什么是压缩?
不是所有的编码都能减少存储空间,比如 Base64 编码会将每 3 个字节的二进制数据转换为 4 个 Base64 字符,反而会增加存储空间。所以在数据库中,通常会结合编码与压缩一起节省存储空间,先将数据编码,然后再压缩。
在计算机技术中,压缩随处可见。它可以分为两种类型。
一种是有损压缩。压缩后的数据会丢失部分信息,但通常丢失的部分不影响数据的完整性。比如针对音频、视频等多媒体数据的压缩,我们常见的 JPEG 图像、MP3 其实都属于有损压缩的技术。
另一种是无损压缩。压缩数据可以完全还原成原始数据,不会损失任何信息。无损压缩通常适用于需要完全保留数据准确性和完整性的情况,数据库领域使用的基本都是无损压缩。
压缩主要是利用消除冗余信息,利用数据的统计特性来减少数据大小、节省存储空间、提升数据传输效率。它会结合不同的编码形式。比如结合字典编码,将重复出现的数据块替换为指向字典中的索引。还有 Huffman 编码,是根据字符出现频率分配不同长度的编码来实现压缩的。出现次数高的字符用短编码表示,出现次数低的字符用长编码表示,从而减少整体长度。
常用的压缩算法包括 Snappy、LZ4、Zstandard、GZip 等,不同的压缩算法会在压缩 / 解压缩速度与压缩比例之间做一个平衡。而且很多压缩算法还能够支持多层压缩,也就是压缩一次后,再进行压缩,这样可以进一步提升压缩比例,但是压缩 / 解压缩时间会相应增加。
这些压缩算法,通常能够压缩 50%-70% 以上的空间,极大地提升了数据的读取与写入速度。而且分布式数据库通常还会对数据进行多副本的备份,压缩后的数据再进行副本的同步,传输数据量也大大减少了,传输备份效率也会提升。
整理了几个数据库所支持的压缩算法,以及这些算法的一些压缩指标。
| 数据库 | 支持的压缩算法 |
|---|---|
| HBase | 支持 LZO、GZ、SNAPPY、LZ4、ZStandard、BZIP2、LZMA、Brotli 等压缩算法。 默认不开启压缩,支持设置列族级别的压缩。 |
| StarRocks | 支持 LZ4、ZStandard、zlib 和 Snappy 压缩算法。 在 StarRocks 中这些算法的压缩率排名是 zlib>Zstandard>LZ4>Snappy。 zlib 拥有较高的压缩比但是会影响到性能,官方建议使用 ZStandard、LZ4。 默认使用 LZ4,支持设置表级别压缩算法。 |
| ClickHouse | Clickhouse 把压缩算法、编码混用。 支持的压缩、编码算法很多,比如 LZ4、ZStandard、Delta、Gorilla 等。 默认使用 LZ4,支持设置列级别的压缩算法。 |
下面是这 3 个分布式数据库建表时启用编码与压缩的方法。
# HBase 启用压缩
CREATE 't1',
{NAME => 'cf1', COMPRESSION => 'SNAPPY'},
{NAME => 'cf2', COMPRESSION => 'GZ'}
# Starrocks 启用压缩
CREATE TABLE `t1`
(
`id` INT(11) NOT NULL,
`key` CHAR(200) NULL ,
`value` CHAR(200) NULL
) ENGINE = OLAP
UNIQUE KEY(`id`)
DISTRIBUTED BY HASH(`id`)
PROPERTIES (
"compression" = "ZSTD"
);
# Clickhouse 启用压缩
CREATE TABLE t3
(
dt Date CODEC(ZSTD),
ts DateTime CODEC(LZ4HC),
float_value Float32 CODEC(NONE),
double_value Float64 CODEC(LZ4HC(9)),
value1 Float32 CODEC(Delta, ZSTD),
value2 Float32 CODEC(Gorilla)
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(dt)
ORDER BY (dt, ts);
这 3 个分布式数据库都支持 LZ4 算法,而且其中两个都把它当做默认的压缩算法,Clickhouse 则最为灵活,可以设置列级别的压缩算法。而 HBase 默认是不启用编码与压缩的,用户可以基于自己的数据选用一个合适的编码压缩算法,一般都会提升整体的性能。
2.2 压缩算法指标
不同的压缩算法,在不同场景、不同类型数据集、不同机器配置下表现差异较大,可以从这个压缩性能基准测试网站看到各种压缩算法的压缩比率、压缩速度、解压速度的一个对比。
以下是一段生成 parquet 文件并进行压缩的代码:
import pyarrow as pa
import pyarrow.parquet as pq
import random
import time
# 创建一个员工表,包含员工ID、部门ID、薪资 3列
data = {
'employ_id': [],
'dep_no': [],
'salary': [],
}
# 随机生成 10000000 个员工数据
for i in range(10000000):
data['employ_id'].append('NO' + str(i + 1)) # 员工ID从1开始递增
data['dep_no'].append(random.randint(1, 10)) # 部门ID随机取值范围为1-10
data['salary'].append(random.randint(1000, 10000)) # 薪资随机取值范围为1000-10000
table = pa.table(data)
# 不压缩写入
start_time = time.time()
pq.write_table(table, 'employee_no_compress.parquet', compression=None)
end_time = time.time()
execution_time = (end_time - start_time) * 1000
print(f"不压缩执行时间: {execution_time} 毫秒")
# 使用 SNAPPY 压缩写入
start_time = time.time()
pq.write_table(table, 'employee_snappy.parquet', compression='SNAPPY')
end_time = time.time()
execution_time = (end_time - start_time) * 1000
print(f"SNAPPY压缩执行时间: {execution_time} 毫秒")
# 使用 LZ4 压缩写入
start_time = time.time()
pq.write_table(table, 'employee_lz4.parquet', compression='LZ4')
end_time = time.time()
execution_time = (end_time - start_time) * 1000
print(f"LZ4压缩执行时间: {execution_time} 毫秒")
代码中随机生成了 1000 万行员工数据,然后分别不压缩、使用 Snappy 压缩、使用 LZ4 压缩后写入 Parquet 文件。输出结果如下所示。
不压缩执行时间: 512.6681327819824 毫秒
SNAPPY压缩执行时间: 579.6384811401367 毫秒
LZ4压缩执行时间: 596.900224685669 毫秒
同时输出文件大小分别为:不压缩 = 153.9M、Snappy 压缩 = 73.3M、LZ4 压缩 = 66.7M。
可以看到,压缩率 LZ4 相对更高,Snappy 则性能稍优。
但压缩也不是“放之四海而皆准”的。在一些高性能系统中,如果大量使用压缩,将会占用较多的 CPU 资源,进而有可能导致系统响应性能下降。而且有时候数据需要解压后才能查询过滤,这对读性能又是一个不利的因素。
3. 总结
本文介绍了编码与压缩的原理和用途,包括节省存储空间,通过优化数据对比和过滤让相同的内存下能够缓存更多的数据,从而提升数据传输、读写的性能。当然,带来的副作用是对 CPU 资源的占用。
比如 HBase2.0 之前有一个叫做 PREFIX_TREE 的编码算法,某些情况下甚至直接导致 CPU 占用 100%,不过在 HBase2.0 之后的版本,这个编码算法被弃用了。
不同的编码与压缩的方式基本是在平衡效率与性能,用户需要根据使用场景进行取舍。比如在时序数据集下可能就适合用 Delta 编码压缩的方式。低基数的全球地址表就适合使用字典编码等。本文也提供了一个使用自己数据集来测试不同压缩方式的例子,可以用来判断哪个压缩算法更合适现有数据集。
编码与压缩是数据库高性能的一个重要因素,LZ4、Snappy、ZStandard 是在数据库引擎中支持较广的压缩方式,一般情况下使用默认的编码压缩会取得较好的性能平衡,知道调整这些编码与压缩算法的方法,可以让用户根据自己的数据集的进行一些性能调优。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号