



行式存储和列式存储对比以及Parquet存储格式介绍
1. 行列存储对比
行式存储就是将数据库的一行数据物理上也存储在一起,列式存储则是按照列将数据物理上存储在一起。
下图中,R1C1 代表第 1 行数据的第 1 列,R3C1 代表第 3 行的第 1 列。
1. 行列存储对比
行式存储就是将数据库的一行数据物理上也存储在一起,列式存储则是按照列将数据物理上存储在一起。
下图中,R1C1 代表第 1 行数据的第 1 列,R3C1 代表第 3 行的第 1 列。
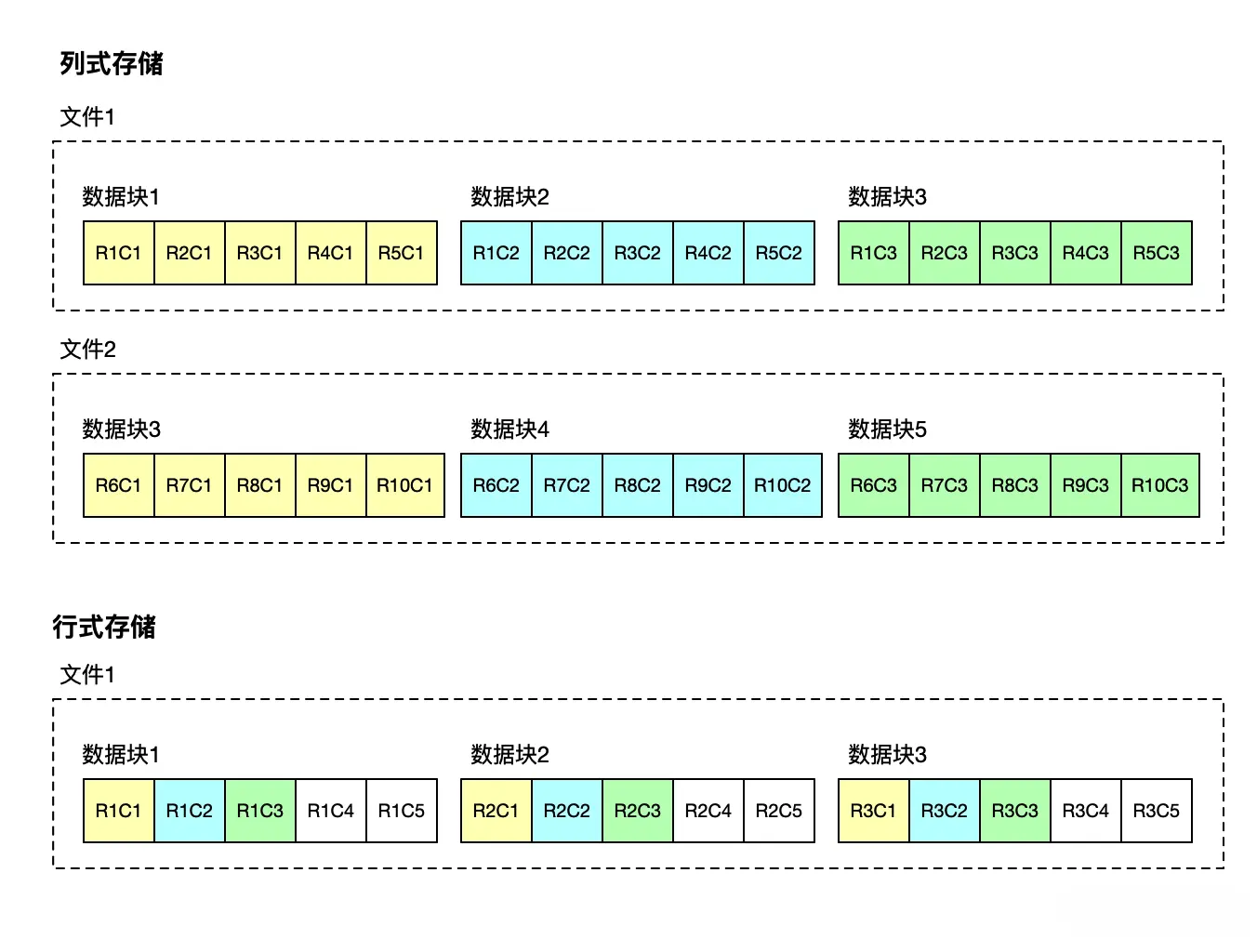
- 在列式存储下,列 C1 的数据在磁盘上聚簇地存储在数据块(或者页),但是一列可以由多个数据块或者数据文件存储。
- 在行式存储下,行 R1 的数据在磁盘上聚簇地存储在数据块上。
行式存储与列式存储的发展,与其对应的不同类型的数据库发展息息相关。
假设一个订单表有 40 个字段,包括订单编号、订单金额、订单状态、商品名称、会员信息等。
在 OLTP(联机事务处理)场景下,通常我们的需求是根据订单编号来更新订单状态,或者通过订单编号查询订单的细节信息(金额、商品名称等)来处理售后需求等。
在这些场景里,都需要用订单编号来把订单的详情,也就是这 40 个字段都查询、展示出来,更新某些字段后,再整行存储。
如果使用行式存储,这 40 个字段就会存储在磁盘的同一个数据块里,读取数据的时候能够一次性顺序读取出来。反之,如果使用列式存储,一行数据的这 40 个字段可能分布在 40 个数据块里,我们要遍历这 40 个数据块才能将这个订单的详情“凑”完整。
所以,OLTP 场景下,一般使用行式存储,这就是传统关系型数据库的做法。
虽然不是说关系型数据库就一定要用行式存储,但是关系型数据库的一些特性就决定了使用行式存储是一个较优的选择。
- 在 OLTP 场景,数据一般以行的形式进行处理与查询,一行数据通常被一起插入、一起查询、一起更新,这样,使用行式存储就能够以最少的磁盘读写代价处理一行业务数据的读写。
- 关系型数据库需要支持事务,一行数据或者多行数据需要能够一起持久化成功或者一起失败,按行存储能够简化读写的 I/O,提升性能。
MySQL 这种关系型数据库数据的写入并不是直接发生在磁盘上的。它的更新操作首先是将数据写入内存,并同时生成一条 Redo 日志记录。这种日志记录机制保证了数据的持久性和可恢复性,用于故障时重做来恢复数据。当达到特定的刷新阈值时,如事务提交或日志缓冲区满,内存中的数据才会被写入磁盘。
因此,即使在事务的上下文中,数据的写入或更新也不是立即映射到磁盘上的行式存储结构中的。这个过程是由 InnoDB 存储引擎内部的缓冲和日志刷新机制决定的,能够有效地提高事务处理的性能。
而到了 OLAP(联机分析处理)场景下,同样的订单表,我们关注的是销售额怎么样,哪些商品品类卖得比较好等。这时候通常是按日期统计一下订单金额字段的总和。
如果使用列式存储,同一列的值存储在一起,假设某天的销售额有 10000 个订单需要统计,那么可能 5000 个订单的订单金额列存储在一起,订单金额这一列就只占用 2 个数据块,这样只需要扫描这 2 个数据块,将扫描到的数据直接累加,就得到了销售额。
反之,如果使用行式存储,一个数据块即使能够存储 1000 行数据,那么也要扫描 10000/1000=10 个数据块,扫描完全部数据,从数据行中挑出订单金额的列,才能累加得到订单金额的汇总。
所以 OLAP 场景下,一般使用列式存储,这也是分析型数据库的做法。列式存储适用于分析型数据库,有两点原因。
- 分析型数据库一般都是批量写入数据,同一列数据一起批量写入,这一列的数据类型相同,所以具备更高的压缩率,可以加快数据的读写速度。
- OLAP 场景一般需要扫描大量数据行,但是基本是对一列或者多列进行统计分析、聚合等,列式存储可以只读取所需的列,从而避免加载整个行的数据,这大大减少了 I/O 操作,提高了查询效率。
OLTP 像单个业务执行者,快速的处理单个事务以及有限条数据,确保业务顺畅进行;而 OLAP 就像是战略分析家,深入剖析数据,为决策提供支持。
列式存储被提及越来越多主要还是大数据技术的发展,数据已经是企业数字化决策与战略方向制定的一个可靠参考。而这些决策的数据支撑都是通过采集企业内外部各个系统的数据,然后汇聚到基于列式存储的数据仓库,最后通过多维分析挖掘出来的。
分布式时代的数据库,基本都使用的是列式存储,比如 HBase、Cassandra、ClickHouse、StarRocks 等。HBase 是一个宽列存储,基本跟行式存储差不多了。 下表为这些数据库的存储模式和适用场景。
| 数据库 | 存储模式 | 描述 | 适用场景 |
|---|---|---|---|
| HBase | 宽列存储 | 按列族数据聚簇存储,不限定 schema,列族内的列可以动态添加。 | 按列族存储,基本上是一行数据存储在一起了,所以适合少量行的实时随机存取场景。 |
| ClickHouse | 列式存储 | 通过多种存储数据结构来平衡读写性能,号称能够支持大量的实时更新。支持 Parquet、ORC、Avro、RCFile 等格式的外部表。 | 在列式存储基础上做了很多优化,能够做到实时的数据处理和交互式查询,并且性能较高,可以为 OLTP 场景的应用提供一些实时的报表查询。 |
| StarRocks | 列式存储 | 纯列式存储的典范,自定义了一套内部使用和优化的专有格式。 | 建议用大宽表的模式,适合大规模数据分析并且对查询性能和数据压缩有较高要求的场景,但是对并发支持没那么好。 |
虽然 HBase 是宽列存储模式,但基本上还是一行数据存储在一起,所以能够在高并发、实时要求高的 OLTP 场景下使用,其他两个列式存储的数据库则都适用于数据分析的场景,不过在大量数据分析与实时性能上做了一些平衡取舍。
2. Parquet 存储格式
2.1 简介
列式存储是上述几种类型数据库的基石。支持很多种存储格式,有 Apache Parquet、Apache ORC 等等。
Apache Parquet 是列式存储中最流行的格式,主流数据库基本都支持,很多分析工具也能直接分析 Parquet 文件,工作中需要迁移数据、分析数据、实时计算等等,大多都会和这种格式打交道。
HBase 数据可以导出为 Parquet,然后用 Spark 等工具来进行批量分析。ClickHouse 与 StarRocks 都支持直接读取与写入 Parquet 数据。
Parquet 不单单是一个数据库的存储格式,它同样能够用于大规模的数据分析与处理,比如与 Spark、Flink 等集成,也支持直接用 Python、Java 等语言来读写,甚至用户可以将自己的数据写成一个 Parquet 文件,然后使用支持 Parquet 格式的引擎来分析。
除了依托于 Hadoop 生态体系的支持外,Parquet 也满足了一个优秀的存储格式设计各个方面的要求。
- 支持多种高效的编码与压缩算法,在减少存储空间的同时,仍然能够保持良好的读取性能。
- 兼容性方面不局限于 Hadoop 生态,不局限于语言,提供了跨平台的数据交换能力。
- 提供高性能支持,比如使用分区、索引、布隆过滤器等来支持过滤掉不需要扫描的数据等。
Parquet 文件格式的内容如下:
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1"
这里描述了一个 N 列的表,每一列又被分成 M 个行组(Row Group),也就是上面的“Chunk 1 到 M”。行组可以看作是 Parquet 文件内部的分区,存储着一定数量的数据行。文件内容中,列块旁边还存储着一个列的元数据,列的元数据包含了列的数据类型、编码压缩方式、数据的起始位置、统计值等。
再下面的位置,还有一个 File Metadata,是文件的元数据。文件元数据用来描述整个文件的版本信息、schema、行组信息等。文件的元数据的写入是在数据写入之后完成的。这样,一旦数据写入完成,对应的元数据也就确定了。这种方式可以一次性将数据和元数据一起写入文件,避免了需要进行更新的情况。数据读取的时候也能通过文件元数据快速找到需要读取的列块(Column Chunk)。
2.2 构建 Parquet 文件
Parquet 具备很好的兼容性,不局限于语言。比如使用 Python 提供的 PyArrow 库,就可以快速地将数据存储为 Parquet 文件。
在大规模的分布式数据系统中,同时处理大数据量的实时随机存取与批量分析是一个很复杂的问题,因为没有一个存储引擎能够同时精通实时随机存取与批量分析,所以诞生了一个叫做 Lambda 的架构。
Lambda 的核心思想是通过分层与管道来构建一个混合架构。比如采用 HBase 来满足实时随机存取的需求,然后将 HBase 的数据导出来,转成 Parquet 文件,接着将 Parquet 文件导入到像 HDFS 之类的文件存储中,最后通过 Spark、Impala 之类的分析引擎来查询数据,满足批量分析的需求。
这里用一个简单的例子来模拟写入数据生产 Parquet 文件,然后使用 PySpark 来分析这个文件。
安装依赖包:
pip install pyarrow
创建 parquet 文件:
import pyarrow as pa
import pyarrow.parquet as pq
# 创建一个员工表,包含员工ID、部门ID、薪资 3列
data = {
'employ_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'dep_no': [1, 1, 1, 2, 2, 2, 3, 3, 3, 3],
'salary': [1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000],
}
table = pa.table(data)
# 将员工表数据写入 Parquet 文件
pq.write_table(table, 'employee.parquet')
这段代码用一个 DataFrame 声明了一个表数据,然后基于表数据转化成一个 pa 的表,最后将表使用 PyArrow 引擎写入了 employee.parquet 文件,实际上还有很多事情可以处理,比如设置写入的 Parquet 文件列的压缩方式、编码方式等。
输出的 Parquet 文件是一个二进制文件,无法直接查看,但是可以通过 ParquetViewer 这类工具查看或者让程序读取。
2.3 读取分析 Parquet 文件
Parquet 文件的读取分析也很简单,常用的大数据分析引擎基本都能够支持,比如 Apache Spark、Apache Drill、Apache Impala、Presto 等。
安装依赖包:
pip install pyspark==3.5.7
下面的代码使用 Spark 读取 Parquet 文件,实现的按部门汇总薪资的统计分析。
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
# 创建一个SparkSession对象
spark = SparkSession.builder.appName("read_parquet_by_pyspark").getOrCreate()
# 读取Parquet文件
df = spark.read.parquet('employee.parquet')
# 显示DataFrame的内容
df.show()
# 计算DataFrame中的记录数
record_count = df.count()
print(f"Total records: {record_count}")
# 按部门编号分组统计薪资
grouped_data = df.groupBy("dep_no").agg(f.sum("salary").alias("total_salary"))
grouped_data.show()
# 关闭SparkSession
spark.stop()
输出:
+---------+------+------+
|employ_id|dep_no|salary|
+---------+------+------+
| 1| 1| 1000|
| 2| 1| 2000|
| 3| 1| 3000|
| 4| 2| 4000|
| 5| 2| 5000|
| 6| 2| 6000|
| 7| 3| 7000|
| 8| 3| 8000|
| 9| 3| 9000|
| 10| 3| 10000|
+---------+------+------+
Total records: 10
+------+------------+
|dep_no|total_salary|
+------+------------+
| 1| 6000|
| 3| 34000|
| 2| 15000|
+------+------------+
3. 总结
行式存储适用于 OLTP 系统针对单行读写较多的场景,而列式存储则适合在 OLAP 场景下,批量导入,多次查询。
一般高效的数据库,都会自行定义自有的一个数据存储格式,但是也都会提供对诸如 Parquet 之类格式文件的支持与集成。
Parquet 作为大数据时代下最流行的列式存储格式,很多分布式数据库都支持将 Parquet 文件作为外部表,比如 StarRocks、Hive 等,也有很多数据查询引擎与计算框架如 Spark、Presto、MapReduce 等都支持直接读取分析 Parquet 文件。
- 在列式存储下,列 C1 的数据在磁盘上聚簇地存储在数据块(或者页),但是一列可以由多个数据块或者数据文件存储。
- 在行式存储下,行 R1 的数据在磁盘上聚簇地存储在数据块上。
行式存储与列式存储的发展,与其对应的不同类型的数据库发展息息相关。
假设一个订单表有 40 个字段,包括订单编号、订单金额、订单状态、商品名称、会员信息等。
在 OLTP(联机事务处理)场景下,通常我们的需求是根据订单编号来更新订单状态,或者通过订单编号查询订单的细节信息(金额、商品名称等)来处理售后需求等。
在这些场景里,都需要用订单编号来把订单的详情,也就是这 40 个字段都查询、展示出来,更新某些字段后,再整行存储。
如果使用行式存储,这 40 个字段就会存储在磁盘的同一个数据块里,读取数据的时候能够一次性顺序读取出来。反之,如果使用列式存储,一行数据的这 40 个字段可能分布在 40 个数据块里,我们要遍历这 40 个数据块才能将这个订单的详情“凑”完整。
所以,OLTP 场景下,一般使用行式存储,这就是传统关系型数据库的做法。
虽然不是说关系型数据库就一定要用行式存储,但是关系型数据库的一些特性就决定了使用行式存储是一个较优的选择。
- 在 OLTP 场景,数据一般以行的形式进行处理与查询,一行数据通常被一起插入、一起查询、一起更新,这样,使用行式存储就能够以最少的磁盘读写代价处理一行业务数据的读写。
- 关系型数据库需要支持事务,一行数据或者多行数据需要能够一起持久化成功或者一起失败,按行存储能够简化读写的 I/O,提升性能。
MySQL 这种关系型数据库数据的写入并不是直接发生在磁盘上的。它的更新操作首先是将数据写入内存,并同时生成一条 Redo 日志记录。这种日志记录机制保证了数据的持久性和可恢复性,用于故障时重做来恢复数据。当达到特定的刷新阈值时,如事务提交或日志缓冲区满,内存中的数据才会被写入磁盘。
因此,即使在事务的上下文中,数据的写入或更新也不是立即映射到磁盘上的行式存储结构中的。这个过程是由 InnoDB 存储引擎内部的缓冲和日志刷新机制决定的,能够有效地提高事务处理的性能。
而到了 OLAP(联机分析处理)场景下,同样的订单表,我们关注的是销售额怎么样,哪些商品品类卖得比较好等。这时候通常是按日期统计一下订单金额字段的总和。
如果使用列式存储,同一列的值存储在一起,假设某天的销售额有 10000 个订单需要统计,那么可能 5000 个订单的订单金额列存储在一起,订单金额这一列就只占用 2 个数据块,这样只需要扫描这 2 个数据块,将扫描到的数据直接累加,就得到了销售额。
反之,如果使用行式存储,一个数据块即使能够存储 1000 行数据,那么也要扫描 10000/1000=10 个数据块,扫描完全部数据,从数据行中挑出订单金额的列,才能累加得到订单金额的汇总。
所以 OLAP 场景下,一般使用列式存储,这也是分析型数据库的做法。列式存储适用于分析型数据库,有两点原因。
- 分析型数据库一般都是批量写入数据,同一列数据一起批量写入,这一列的数据类型相同,所以具备更高的压缩率,可以加快数据的读写速度。
- OLAP 场景一般需要扫描大量数据行,但是基本是对一列或者多列进行统计分析、聚合等,列式存储可以只读取所需的列,从而避免加载整个行的数据,这大大减少了 I/O 操作,提高了查询效率。
OLTP 像单个业务执行者,快速的处理单个事务以及有限条数据,确保业务顺畅进行;而 OLAP 就像是战略分析家,深入剖析数据,为决策提供支持。
列式存储被提及越来越多主要还是大数据技术的发展,数据已经是企业数字化决策与战略方向制定的一个可靠参考。而这些决策的数据支撑都是通过采集企业内外部各个系统的数据,然后汇聚到基于列式存储的数据仓库,最后通过多维分析挖掘出来的。
分布式时代的数据库,基本都使用的是列式存储,比如 HBase、Cassandra、ClickHouse、StarRocks 等。HBase 是一个宽列存储,基本跟行式存储差不多了。 下表为这些数据库的存储模式和适用场景。
| 数据库 | 存储模式 | 描述 | 适用场景 |
|---|---|---|---|
| HBase | 宽列存储 | 按列族数据聚簇存储,不限定 schema,列族内的列可以动态添加。 | 按列族存储,基本上是一行数据存储在一起了,所以适合少量行的实时随机存取场景。 |
| ClickHouse | 列式存储 | 通过多种存储数据结构来平衡读写性能,号称能够支持大量的实时更新。支持 Parquet、ORC、Avro、RCFile 等格式的外部表。 | 在列式存储基础上做了很多优化,能够做到实时的数据处理和交互式查询,并且性能较高,可以为 OLTP 场景的应用提供一些实时的报表查询。 |
| StarRocks | 列式存储 | 纯列式存储的典范,自定义了一套内部使用和优化的专有格式。 | 建议用大宽表的模式,适合大规模数据分析并且对查询性能和数据压缩有较高要求的场景,但是对并发支持没那么好。 |
虽然 HBase 是宽列存储模式,但基本上还是一行数据存储在一起,所以能够在高并发、实时要求高的 OLTP 场景下使用,其他两个列式存储的数据库则都适用于数据分析的场景,不过在大量数据分析与实时性能上做了一些平衡取舍。
2. Parquet 存储格式
2.1 简介
列式存储是上述几种类型数据库的基石。支持很多种存储格式,有 Apache Parquet、Apache ORC 等等。
Apache Parquet 是列式存储中最流行的格式,主流数据库基本都支持,很多分析工具也能直接分析 Parquet 文件,工作中需要迁移数据、分析数据、实时计算等等,大多都会和这种格式打交道。
HBase 数据可以导出为 Parquet,然后用 Spark 等工具来进行批量分析。ClickHouse 与 StarRocks 都支持直接读取与写入 Parquet 数据。
Parquet 不单单是一个数据库的存储格式,它同样能够用于大规模的数据分析与处理,比如与 Spark、Flink 等集成,也支持直接用 Python、Java 等语言来读写,甚至用户可以将自己的数据写成一个 Parquet 文件,然后使用支持 Parquet 格式的引擎来分析。
除了依托于 Hadoop 生态体系的支持外,Parquet 也满足了一个优秀的存储格式设计各个方面的要求。
- 支持多种高效的编码与压缩算法,在减少存储空间的同时,仍然能够保持良好的读取性能。
- 兼容性方面不局限于 Hadoop 生态,不局限于语言,提供了跨平台的数据交换能力。
- 提供高性能支持,比如使用分区、索引、布隆过滤器等来支持过滤掉不需要扫描的数据等。
Parquet 文件格式的内容如下:
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1"
这里描述了一个 N 列的表,每一列又被分成 M 个行组(Row Group),也就是上面的“Chunk 1 到 M”。行组可以看作是 Parquet 文件内部的分区,存储着一定数量的数据行。文件内容中,列块旁边还存储着一个列的元数据,列的元数据包含了列的数据类型、编码压缩方式、数据的起始位置、统计值等。
再下面的位置,还有一个 File Metadata,是文件的元数据。文件元数据用来描述整个文件的版本信息、schema、行组信息等。文件的元数据的写入是在数据写入之后完成的。这样,一旦数据写入完成,对应的元数据也就确定了。这种方式可以一次性将数据和元数据一起写入文件,避免了需要进行更新的情况。数据读取的时候也能通过文件元数据快速找到需要读取的列块(Column Chunk)。
2.2 构建 Parquet 文件
Parquet 具备很好的兼容性,不局限于语言。比如使用 Python 提供的 PyArrow 库,就可以快速地将数据存储为 Parquet 文件。
在大规模的分布式数据系统中,同时处理大数据量的实时随机存取与批量分析是一个很复杂的问题,因为没有一个存储引擎能够同时精通实时随机存取与批量分析,所以诞生了一个叫做 Lambda 的架构。
Lambda 的核心思想是通过分层与管道来构建一个混合架构。比如采用 HBase 来满足实时随机存取的需求,然后将 HBase 的数据导出来,转成 Parquet 文件,接着将 Parquet 文件导入到像 HDFS 之类的文件存储中,最后通过 Spark、Impala 之类的分析引擎来查询数据,满足批量分析的需求。
这里用一个简单的例子来模拟写入数据生产 Parquet 文件,然后使用 PySpark 来分析这个文件。
安装依赖包:
pip install pyarrow
创建 parquet 文件:
import pyarrow as pa
import pyarrow.parquet as pq
# 创建一个员工表,包含员工ID、部门ID、薪资 3列
data = {
'employ_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'dep_no': [1, 1, 1, 2, 2, 2, 3, 3, 3, 3],
'salary': [1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 10000],
}
table = pa.table(data)
# 将员工表数据写入 Parquet 文件
pq.write_table(table, 'employee.parquet')
这段代码用一个 DataFrame 声明了一个表数据,然后基于表数据转化成一个 pa 的表,最后将表使用 PyArrow 引擎写入了 employee.parquet 文件,实际上还有很多事情可以处理,比如设置写入的 Parquet 文件列的压缩方式、编码方式等。
输出的 Parquet 文件是一个二进制文件,无法直接查看,但是可以通过 ParquetViewer 这类工具查看或者让程序读取。
2.3 读取分析 Parquet 文件
Parquet 文件的读取分析也很简单,常用的大数据分析引擎基本都能够支持,比如 Apache Spark、Apache Drill、Apache Impala、Presto 等。
安装依赖包:
pip install pyspark==3.5.7
下面的代码使用 Spark 读取 Parquet 文件,实现的按部门汇总薪资的统计分析。
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
# 创建一个SparkSession对象
spark = SparkSession.builder.appName("read_parquet_by_pyspark").getOrCreate()
# 读取Parquet文件
df = spark.read.parquet('employee.parquet')
# 显示DataFrame的内容
df.show()
# 计算DataFrame中的记录数
record_count = df.count()
print(f"Total records: {record_count}")
# 按部门编号分组统计薪资
grouped_data = df.groupBy("dep_no").agg(f.sum("salary").alias("total_salary"))
grouped_data.show()
# 关闭SparkSession
spark.stop()
输出:
+---------+------+------+
|employ_id|dep_no|salary|
+---------+------+------+
| 1| 1| 1000|
| 2| 1| 2000|
| 3| 1| 3000|
| 4| 2| 4000|
| 5| 2| 5000|
| 6| 2| 6000|
| 7| 3| 7000|
| 8| 3| 8000|
| 9| 3| 9000|
| 10| 3| 10000|
+---------+------+------+
Total records: 10
+------+------------+
|dep_no|total_salary|
+------+------------+
| 1| 6000|
| 3| 34000|
| 2| 15000|
+------+------------+
3. 总结
行式存储适用于 OLTP 系统针对单行读写较多的场景,而列式存储则适合在 OLAP 场景下,批量导入,多次查询。
一般高效的数据库,都会自行定义自有的一个数据存储格式,但是也都会提供对诸如 Parquet 之类格式文件的支持与集成。
Parquet 作为大数据时代下最流行的列式存储格式,很多分布式数据库都支持将 Parquet 文件作为外部表,比如 StarRocks、Hive 等,也有很多数据查询引擎与计算框架如 Spark、Presto、MapReduce 等都支持直接读取分析 Parquet 文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号