摘要:
RDD任务切分中间分为:Application、Job、Stage和Task Application:初始化一个SparkContext即生成一个Application; Job:一个Action算子就会生成一个Job; Stage:Stage等于宽依赖(ShuffleDependency)的 阅读全文
posted @ 2022-01-08 13:28
爱吃麻辣烫呀
阅读(367)
评论(0)
推荐(0)
摘要:
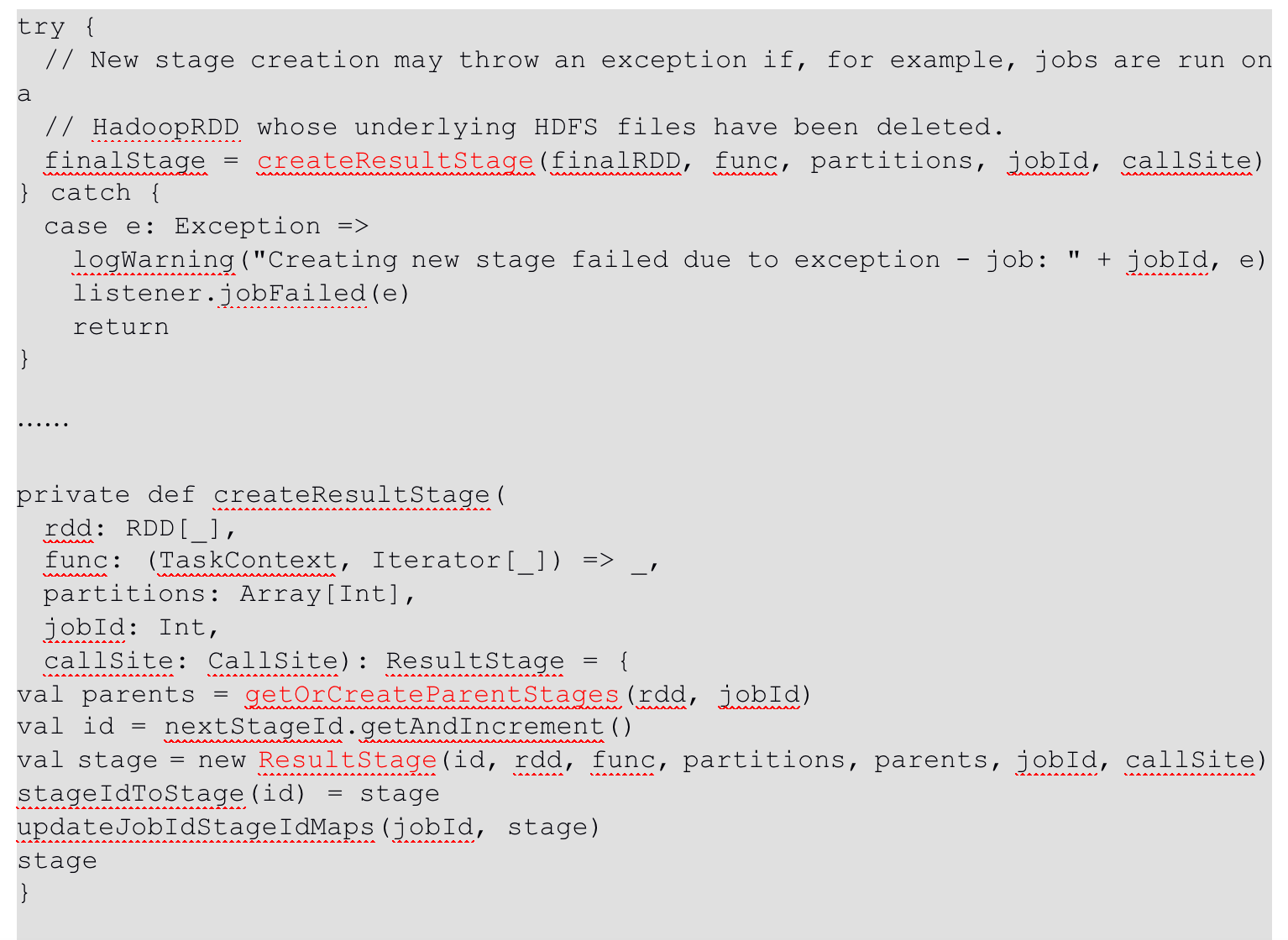 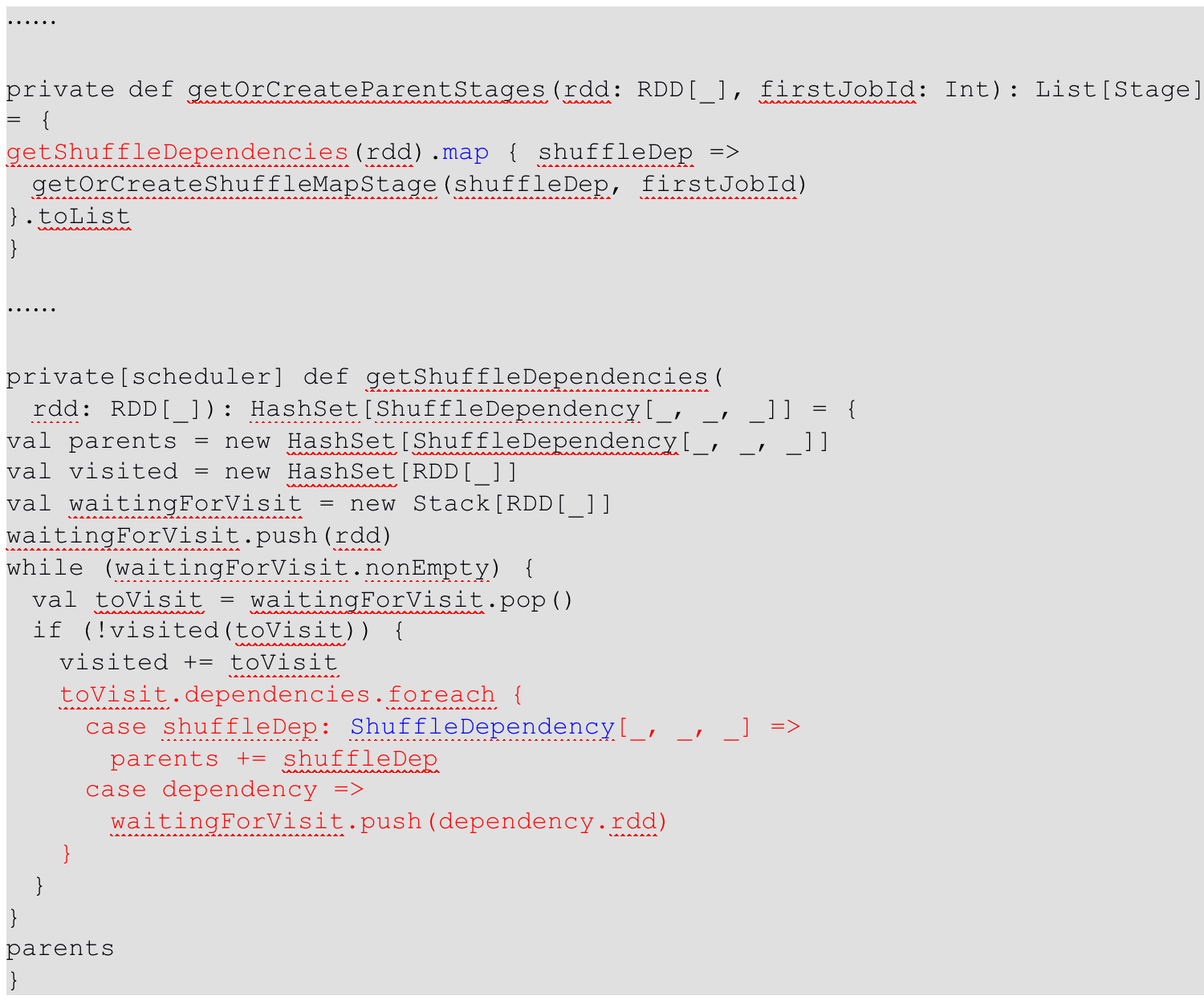 阅读全文
posted @ 2022-01-08 12:17
爱吃麻辣烫呀
阅读(49)
评论(0)
推荐(0)
摘要:
这里所谓的依赖关系,其实就是两个相邻RDD之间的关系 1、窄依赖表示每一个父(上游)RDD的Partition最多被子(下游)RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。 2、宽依赖表示同一个父(上游)RDD的Partition被多个子(下游)RDD的Partition依赖, 阅读全文
posted @ 2022-01-08 11:49
爱吃麻辣烫呀
阅读(101)
评论(0)
推荐(0)
摘要:
1.RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。 阅读全文
posted @ 2022-01-08 11:31
爱吃麻辣烫呀
阅读(88)
评论(0)
推荐(0)
摘要:
1.从计算的角度, 算子以外的代码都是在Driver端执行, 算子里面的代码都是在Executor端执行。那么在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误,所以需要在 阅读全文
posted @ 2022-01-06 19:20
爱吃麻辣烫呀
阅读(70)
评论(0)
推荐(0)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号