scrapy框架爬取蜂鸟网的人像图片
今天有点无聊,本来打算去蜂鸟网爬点图片存起来显得自己有点内涵,但是当我点开人像的时候就被里面的小姐姐所吸引了,下面就是整个爬图片的思路和过程了
第一步:先创建一个爬虫项目
scrapy startproject Feng

然后进入目录里面 创建爬虫

好了 爬虫项目创建完成了,接下来该去网页分析数据了
首先进入蜂鸟网 找到人像摄影页面的网址添加到爬虫的start_urls里面
然后利用开发者工具分析网页页面的图片数据
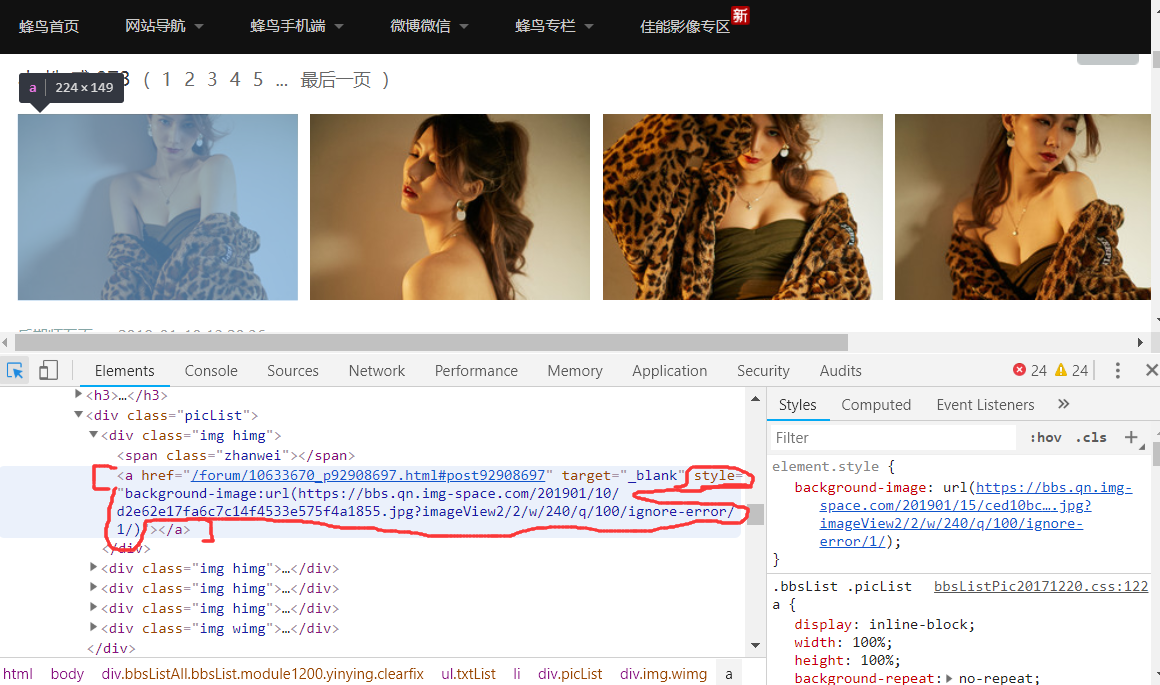
发现图片的地址是在a标签里面的style属性里面的background-image:url,然后根据xpath找到该页面的所有人像图片的a标签里的style属性,获得的属性值有多余的background-image:url(),利用字符串的切片将这些去除掉,就可以获得完整的图片url
这样我就获取到了该页面所有的人像图片的url
然后在settings.py文件里面配置反爬机制
然后再引用scrapy.pipelines.images.ImagesPipeline
并给图片一个存储地址 IMAGE_STORE='./images' 即在当前目录下的images文件夹里面
然后再items.py文件里面设置对象
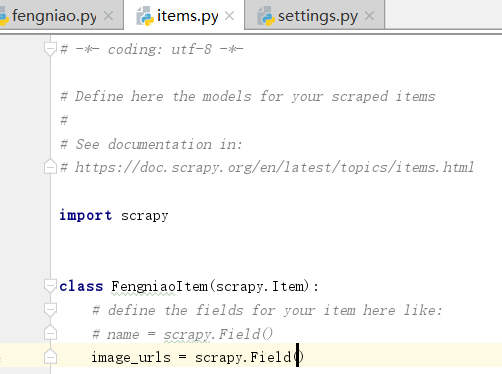
在parse里面导入items,然后创建item对象,然后将取到的图片地址赋给item对象在yield item
这样就可以下载当前页面的图片了
下面的翻页就是获取下一页的链接的xpath,用scrapy中的Request方法访问下一页,callback到parse就能循环翻页并下载
# -*- coding: utf-8 -*- import scrapy from ..items import FengniaoItem class FengniaoSpider(scrapy.Spider): name = 'fengniao' allowed_domains = ['fengniao.com'] start_urls = ['http://bbs.fengniao.com/forum/forum_101.html'] def parse(self, response): image = response.xpath('//li/div/div/a/@style').extract() for i in image: item = FengniaoItem() img = i[21:-1] item['image_urls'] = [img] yield item nextpage = response.xpath('//a[text()="下一页"]/@href') .extract_first() yield scrapy.Request(url=nextpage,callback=self.parse,method='GET',dont_filter=True)
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class FengniaoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() image_urls = scrapy.Field()
# -*- coding: utf-8 -*- # Scrapy settings for Fengniao project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'Fengniao' SPIDER_MODULES = ['Fengniao.spiders'] NEWSPIDER_MODULE = 'Fengniao.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Fengniao (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) COOKIES_ENABLED = True # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'Fengniao.middlewares.FengniaoSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # 'Fengniao.middlewares.FengniaoDownloaderMiddleware': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'Fengniao.pipelines.FengniaoPipeline': 300, 'scrapy.pipelines.images.ImagesPipeline':1, } IMAGES_STORE = './images' # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' LOG_FILE = 'test.log' FEED_EXPORT_ENCODING='utf-8'
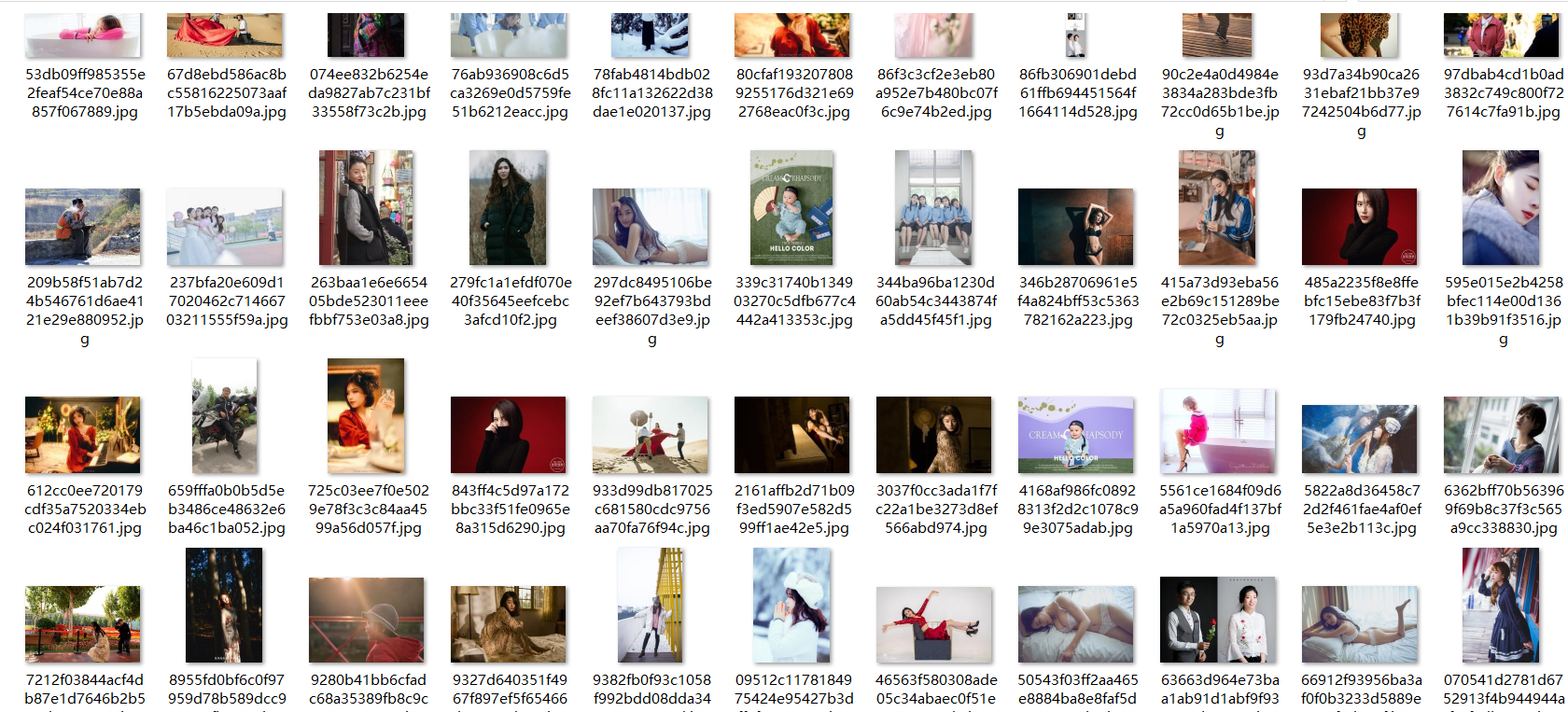
然后下面就是抓下来的部分图片

 浙公网安备 33010602011771号
浙公网安备 33010602011771号