
(原)MobileNetV2
转载请注明出处:
https://www.cnblogs.com/darkknightzh/p/9410574.html
论文:
MobileNetV2: Inverted Residuals and Linear Bottlenecks
网址:
https://arxiv.org/abs/1801.04381
代码:
官方的tensorflow代码:
https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
非官方的pytorch代码:
https://github.com/tonylins/pytorch-mobilenet-v2
参考网址:
https://blog.csdn.net/u011995719/article/details/79135818
https://github.com/Randl/MobileNetV2-pytorch/blob/master/model.py#L54
1. 深度可分离卷积
2. 线性瓶颈层(linear bottlenecks)
mobileNetV2使用了线性瓶颈层。原因是,当使用ReLU等激活函数时,会导致信息丢失。如下图所示,低维(2维)的信息嵌入到n维的空间中,并通过随机矩阵T对特征进行变换,之后再加上ReLU激活函数,之后在通过T-1进行反变换。当n=2,3时,会导致比较严重的信息丢失,部分特征重叠到一起了;当n=15到30时,信息丢失程度降低,但是变换矩阵已经是高度非凸的了。
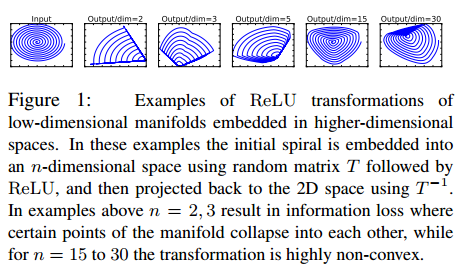
由于非线性层会毁掉一部分信息,因而非常有必要使用线性瓶颈层。且线性瓶颈层包含所有的必要信息,扩张层则是供非线性层丰富信息使用。
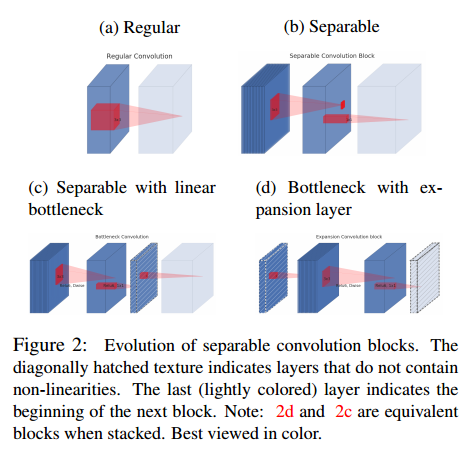
下图对比了不同的卷积方式,其中颜色最浅的代表下一个块(本块输出,下块输入)。带斜杠的为不包含ReLU等非线性激活函数的层。传统的卷积如(a)所示,输入和输出维度不一样,且卷积核直接对输入的红色立方体进行滤波。(b)为可分离卷积,左侧3*3卷积的每个卷积核只对输入的对应层进行滤波,此时特征维度不变;右边的1*1的卷积对特征进行升维或者降维(图中为升维)。(c)中为带线性瓶颈层的可分离卷积,输入通过3*3 depthwise卷积+ReLU6,得到中间相同维度的特征。之后在通过1*1conv+ReLU6,得到降维后的特征(带斜线立方体)。之后在通过1*1卷积(无ReLU)进行升维。(d)中则是维度比较低的特征,先通过1*1conv(无ReLU)升维,而后通过3*3 depthwise卷积+ReLU6保持特征数量不变,再通过1*1conv+ReLU6得到降维后的下一层特征(下一层特征在升维时,无ReLU,因而图中最右边立方体带斜线)。
说明:(b)不太确定,因为如果左侧3*3的卷积为depthwise convolution的话,左侧红色矩形映射到中间应该是一个点,和(c)一样,但是(b)中出现了一个方框,不太懂。。。
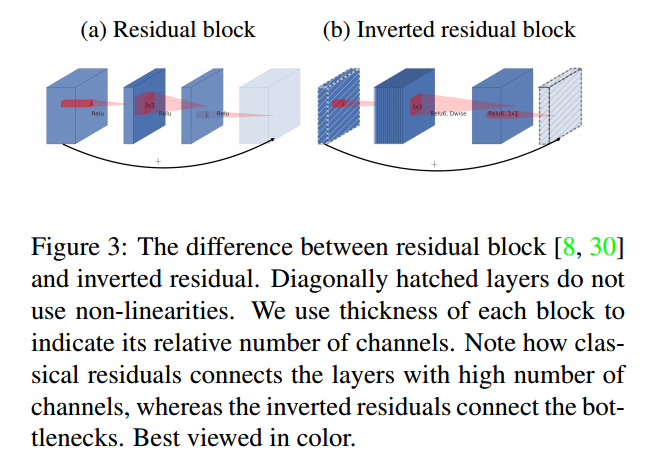
文中提出了反转残差块(inverted residual block)的概念。下图显示了传统的残差块和反转残差块的区别。传统的残差块如(a)将高维特征先使用1*1conv降维,然后在使用3*3conv进行滤波,并使用1*1conv进行升维(这些卷积中均包含ReLU),得到输出特征(下一层的输入),并进行element wise的相加。反转残差块则是将低维特征使用1*1conv升维(不含ReLU),而后使用3*3conv+ReLU对特征进行滤波,并使用1*1conv+ReLU对特征再降维,得到本层特征的输出(即下一层特征的输入,由于下一层的输入在使用1*1conv升维时,无ReLU,因而最右边的立方体带斜线),并进行element wise的相加。
反转的原因,上面已经提到,瓶颈层的输入包含了所有的必要信息,因而右侧最左边的层后面不加ReLU,防止信息丢失。升维后,信息更加丰富,此时加上ReLU,之后在降维,理论上可以保持所有的必要信息不丢失。
为何使用ReLU?使用ReLU可以增加模型的稀疏性。过于稀疏了,信息就丢失了。。。
那瓶颈层内部为何需要升维呢?原因是为了增加模型的表达能力(不确定这样理解是否正确):当使用ReLU对某通道的信息进行处理后,该通道会不可避免的丢失信息;然而如果有足够多的通道的话,某通道丢失的信息,可能仍旧保留在其他通道中,因而才会在瓶颈层内部对特征进行升维。文中附录证明了,瓶颈层内部升维足够大时,能够抵消ReLU造成的信息丢失(如文中将特征维度扩大了6倍)。
瓶颈层的具体结构如下表所示。输入通过1*1的conv+ReLU层将维度从k维增加到tk维,之后通过3*3conv+ReLU可分离卷积对图像进行降采样(stride>1时),此时特征维度已经为tk维度,最后通过1*1conv(无ReLU)进行降维,维度从tk降低到k’维。
需要注意的是,除了整个模型中的第一个瓶颈层的t=1之外,其他瓶颈层t=6(论文中Table 2),即第一个瓶颈层内部并不对特征进行升维。

另外,对于瓶颈层,当stride=1时,才会使用elementwise 的sum将输入和输出特征连接(如下图左侧);stride=2时,无short cut连接输入和输出特征(下图右侧)。

3. 网络模型
MobileNetV2的模型如下图所示,其中t为瓶颈层内部升维的倍数,c为特征的维数,n为该瓶颈层重复的次数,s为瓶颈层第一个conv的步幅。
需要注意的是:
1) 当n>1时(即该瓶颈层重复的次数>1),只在第一个瓶颈层stride为对应的s,其他重复的瓶颈层stride均为1
2) 只在stride=1时,输出特征尺寸和输入特征尺寸一致,才会使用elementwise sum将输出与输入相加
3) 当n>1时,只在第一个瓶颈层特征维度为c,其他时候channel不变。
例如,对于该图中562*24的那层,共有3个该瓶颈层,只在第一个瓶颈层使用stride=2,后两个瓶颈层stride=1;第一个瓶颈层由于输入和输出尺寸不一致,因而无short cut连接,后两个由于stride=1,输入输出特征尺寸一致,会使用short cut将输入和输出特征进行elementwise的sum;只在第一个瓶颈层最后的1*1conv对特征进行升维,后两个瓶颈层输出维度不变(不要和瓶颈层内部的升维弄混了)。
该层输入特征为56*56*24,第一个瓶颈层输出为28*28*32(特征尺寸降低,特征维度增加,无short cut),第二个、第三个瓶颈层输入和输出均为28*28*32(此时c=32,s=1,有short cut)。
另外,下表中还有一个k。MobileNetV1中提出了宽度缩放因子,其作用是在整体上对网络的每一层维度(特征数量)进行瘦身。MobileNetV2中,当该因子<1时,最后的那个1*1conv不进行宽度缩放;否则进行宽度缩放。

4. pytorch代码
1 import torch.nn as nn 2 import math 3 4 5 def conv_bn(inp, oup, stride): 6 return nn.Sequential( 7 nn.Conv2d(inp, oup, 3, stride, 1, bias=False), 8 nn.BatchNorm2d(oup), 9 nn.ReLU6(inplace=True) 10 ) 11 12 13 def conv_1x1_bn(inp, oup): 14 return nn.Sequential( 15 nn.Conv2d(inp, oup, 1, 1, 0, bias=False), 16 nn.BatchNorm2d(oup), 17 nn.ReLU6(inplace=True) 18 ) 19 20 21 class InvertedResidual(nn.Module): 22 def __init__(self, inp, oup, stride, expand_ratio): 23 super(InvertedResidual, self).__init__() 24 self.stride = stride 25 assert stride in [1, 2] 26 27 self.use_res_connect = self.stride == 1 and inp == oup 28 29 self.conv = nn.Sequential( 30 # pw 31 nn.Conv2d(inp, inp * expand_ratio, 1, 1, 0, bias=False), 32 nn.BatchNorm2d(inp * expand_ratio), 33 nn.ReLU6(inplace=True), 34 # dw 35 nn.Conv2d(inp * expand_ratio, inp * expand_ratio, 3, stride, 1, groups=inp * expand_ratio, bias=False), 36 nn.BatchNorm2d(inp * expand_ratio), 37 nn.ReLU6(inplace=True), 38 # pw-linear 39 nn.Conv2d(inp * expand_ratio, oup, 1, 1, 0, bias=False), 40 nn.BatchNorm2d(oup), 41 ) 42 43 def forward(self, x): 44 if self.use_res_connect: 45 return x + self.conv(x) 46 else: 47 return self.conv(x) 48 49 50 class MobileNetV2(nn.Module): 51 def __init__(self, n_class=1000, input_size=224, width_mult=1.): 52 super(MobileNetV2, self).__init__() 53 # setting of inverted residual blocks 54 self.interverted_residual_setting = [ 55 # t, c, n, s 56 [1, 16, 1, 1], 57 [6, 24, 2, 2], 58 [6, 32, 3, 2], 59 [6, 64, 4, 2], 60 [6, 96, 3, 1], 61 [6, 160, 3, 2], 62 [6, 320, 1, 1], 63 ] 64 65 # building first layer 66 assert input_size % 32 == 0 67 input_channel = int(32 * width_mult) 68 self.last_channel = int(1280 * width_mult) if width_mult > 1.0 else 1280 69 self.features = [conv_bn(3, input_channel, 2)] 70 # building inverted residual blocks 71 for t, c, n, s in self.interverted_residual_setting: 72 output_channel = int(c * width_mult) 73 for i in range(n): 74 if i == 0: 75 self.features.append(InvertedResidual(input_channel, output_channel, s, t)) 76 else: 77 self.features.append(InvertedResidual(input_channel, output_channel, 1, t)) 78 input_channel = output_channel 79 # building last several layers 80 self.features.append(conv_1x1_bn(input_channel, self.last_channel)) 81 self.features.append(nn.AvgPool2d(input_size/32)) 82 # make it nn.Sequential 83 self.features = nn.Sequential(*self.features) 84 85 # building classifier 86 self.classifier = nn.Sequential( 87 nn.Dropout(), 88 nn.Linear(self.last_channel, n_class), 89 ) 90 91 self._initialize_weights() 92 93 def forward(self, x): 94 x = self.features(x) 95 x = x.view(-1, self.last_channel) 96 x = self.classifier(x) 97 return x 98 99 def _initialize_weights(self): 100 for m in self.modules(): 101 if isinstance(m, nn.Conv2d): 102 n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels 103 m.weight.data.normal_(0, math.sqrt(2. / n)) 104 if m.bias is not None: 105 m.bias.data.zero_() 106 elif isinstance(m, nn.BatchNorm2d): 107 m.weight.data.fill_(1) 108 m.bias.data.zero_() 109 elif isinstance(m, nn.Linear): 110 n = m.weight.size(1) 111 m.weight.data.normal_(0, 0.01) 112 m.bias.data.zero_()
posted on 2018-08-02 22:20 darkknightzh 阅读(10550) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号