
(原)GAN之pix2pix
转载请注明出处:
https://www.cnblogs.com/darkknightzh/p/9175281.html
论文:
Image-to-Image Translation with Conditional Adversarial Networks
https://arxiv.org/pdf/1611.07004v1.pdf
代码:
官方project:https://phillipi.github.io/pix2pix/
官方torch代码:https://github.com/phillipi/pix2pix
官方pytorch代码(CycleGAN、pix2pix):https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
第三方的tensorflow版本:https://github.com/yenchenlin/pix2pix-tensorflow
pix2pix使用的是Conditional GAN(cGAN)。传统的GAN通过随机向量z学习到图像y:$G:z\to y$;cGAN则是通过输入图像x及随机向量z学到图像y:$G:\{x,z\}\to y$。其目标函数是
${{L}_{cGAN}}(G,D)={{E}_{x,y\sim {{p}_{data}}(x,y)}}\left[ \log D(x,y) \right]+{{E}_{x\sim {{p}_{data}}(x),z\sim {{p}_{z}}(z)}}\left[ \log (1-D(x,G(x,z))) \right]$
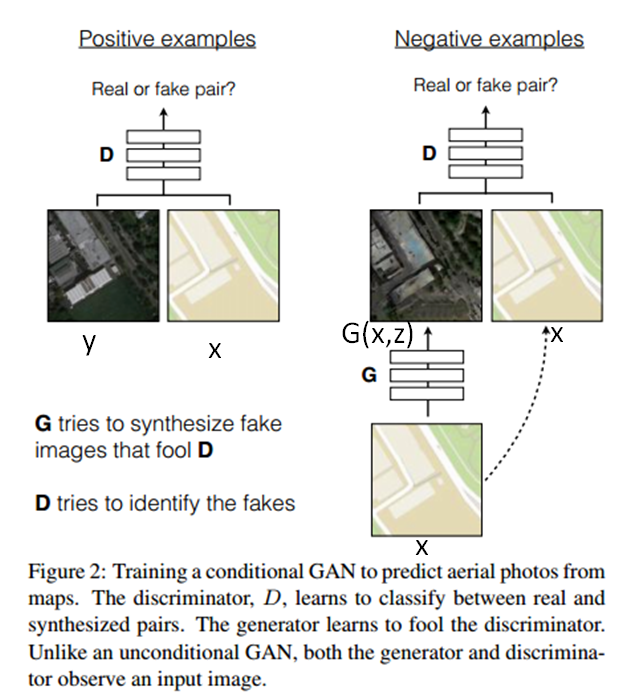
如下图所示,左侧为正样本,右侧为负样本。其中真实图像为y,真是图像对应的航空图像为x,这两张图像通过判别器,得到正样本。右图中将航空图像x通过生成器G,得到重建的图像G(x,z),而后将重构图像及真实航空图像输入判别器D,作为负样本。
由于以前的研究中发现,对于cGAN,增加一个额外的损失,如L2距离(真实图像和生成图像),效果更好。此时判别器的损失不变,生成器的损失变了。该论文中使用L1距离,原因是相比于L2距离,L1距离产生的模糊更小。
${{L}_{L1}}(G)={{E}_{x,y\sim {{p}_{data}}(x,y),z\sim {{p}_{z}}(z)}}\left[ {{\left\| y-G(x,z) \right\|}_{1}} \right]$
因而,pix2pix最终的目标函数是:
${{G}^{*}}=\arg \underset{G}{\mathop{\min }}\,\underset{D}{\mathop{\max }}\,{{L}_{cGAN}}(G,D)+\lambda {{L}_{L1}}(G)$
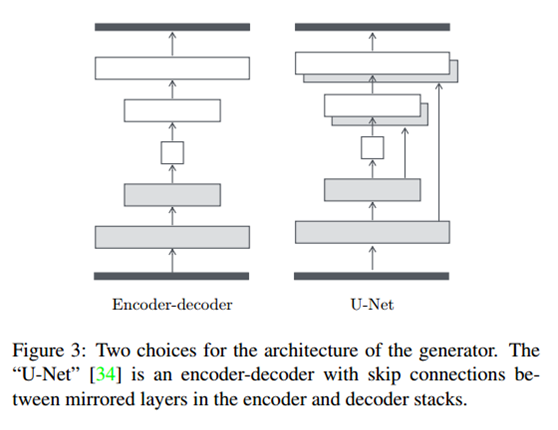
pix2pix未使用传统的encoder-decoder的模式(下图左侧),而是使用了U-Net(下图右侧)网络。U-Net论文为:U-net: Convolutional networks for biomedical image segmentation。U-net在decoder部分,每个conv层之前将输入和decoder对应的镜像层进行了拼接,因而输入的通道数增加了1倍,但是不严谨的说,输入的通道数不会影响卷积的输出维度,因而网络不会出问题。
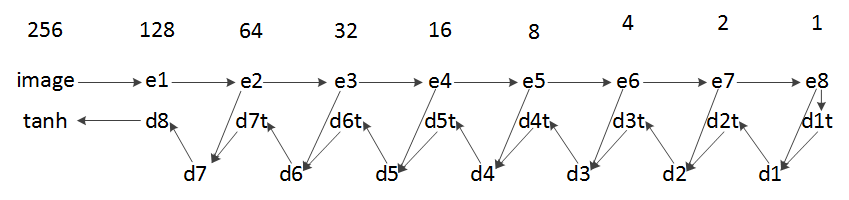
网络中的判别器结构比较容易理解,生成器按照上面U-Net理解之后,也比较容易理解(开始没有理解U-Net,导致对生成器中encoder的理解有困难)。具体网络结构如下图所示(对应于第三方的tensorflow代码)。当输入为256*256的图像时,第一行为图像宽高(未考虑batchsize及channel),第二行中e1…e8和第三行d1…d8为generator函数中对应的变量。第三行d1t…d7t为generator函数中encoder的临时变量。其和e8…e2在channel维度进行concat后得到最终的d1…d7。最终d8经过tanh后,得到输入范围为[-1,1]之内的生成图像。
posted on 2018-06-12 22:07 darkknightzh 阅读(18155) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号