
(原)人体姿态识别alphapose
转载请注明出处:
https://www.cnblogs.com/darkknightzh/p/12150171.html
论文
RMPE: Regional Multi-Person Pose Estimation
https://arxiv.org/abs/1612.00137
官方代码:
https://github.com/MVIG-SJTU/AlphaPose
官方pytorch代码:
https://github.com/MVIG-SJTU/AlphaPose/tree/pytorch
1. 简介
该论文指出,定位和识别中不可避免的会出现错误,这些错误会引起单人姿态估计(single-person pose estimator,SPPE)的错误,特别是完全依赖人体检测的姿态估计算法。因而该论文提出了区域姿态估计(Regional Multi-Person Pose Estimation,RMPE)框架。主要包括symmetric spatial transformer network (SSTN)、Parametric Pose Non- Maximum-Suppression (NMS), 和Pose-Guided Proposals Generator (PGPG)。并且使用symmetric spatial transformer network (SSTN)、deep proposals generator (DPG) 、parametric pose nonmaximum suppression (p-NMS) 三个技术来解决野外场景下多人姿态估计问题。
2. 之前算法的问题
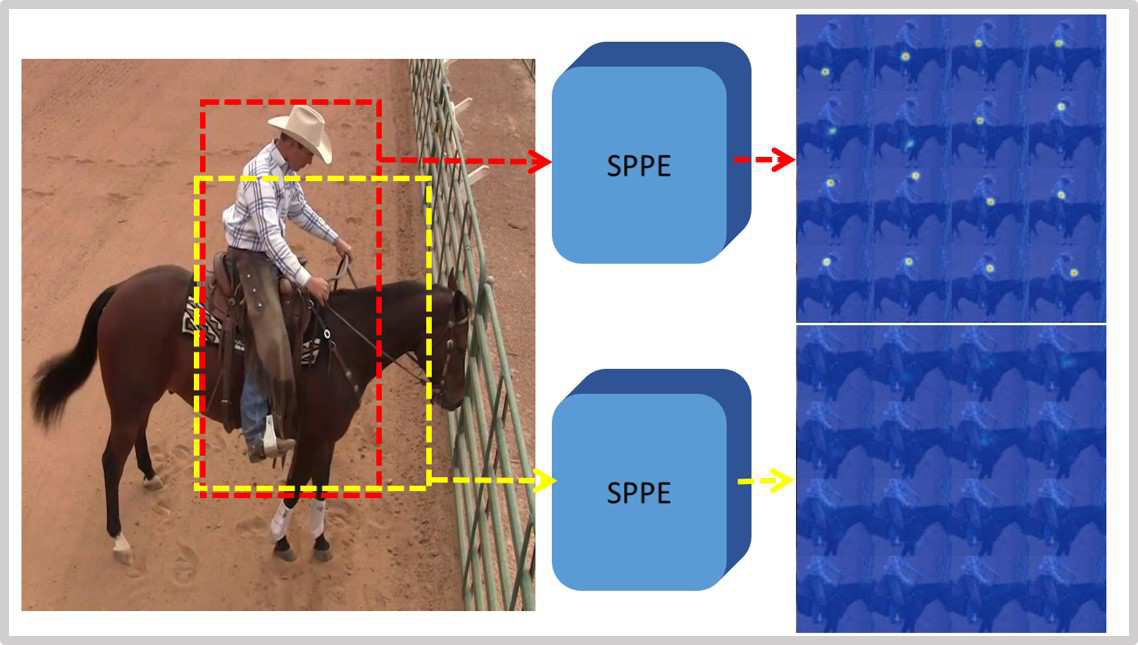
2.1检测框定位错误
如下图所示。红框为真实框,黄框为检测到的框(IoU>0.5)。由于定位错误,黄框得到的热图无法检测到关节点
解决方法:增大训练时的框(框增大0.2-0.3倍)
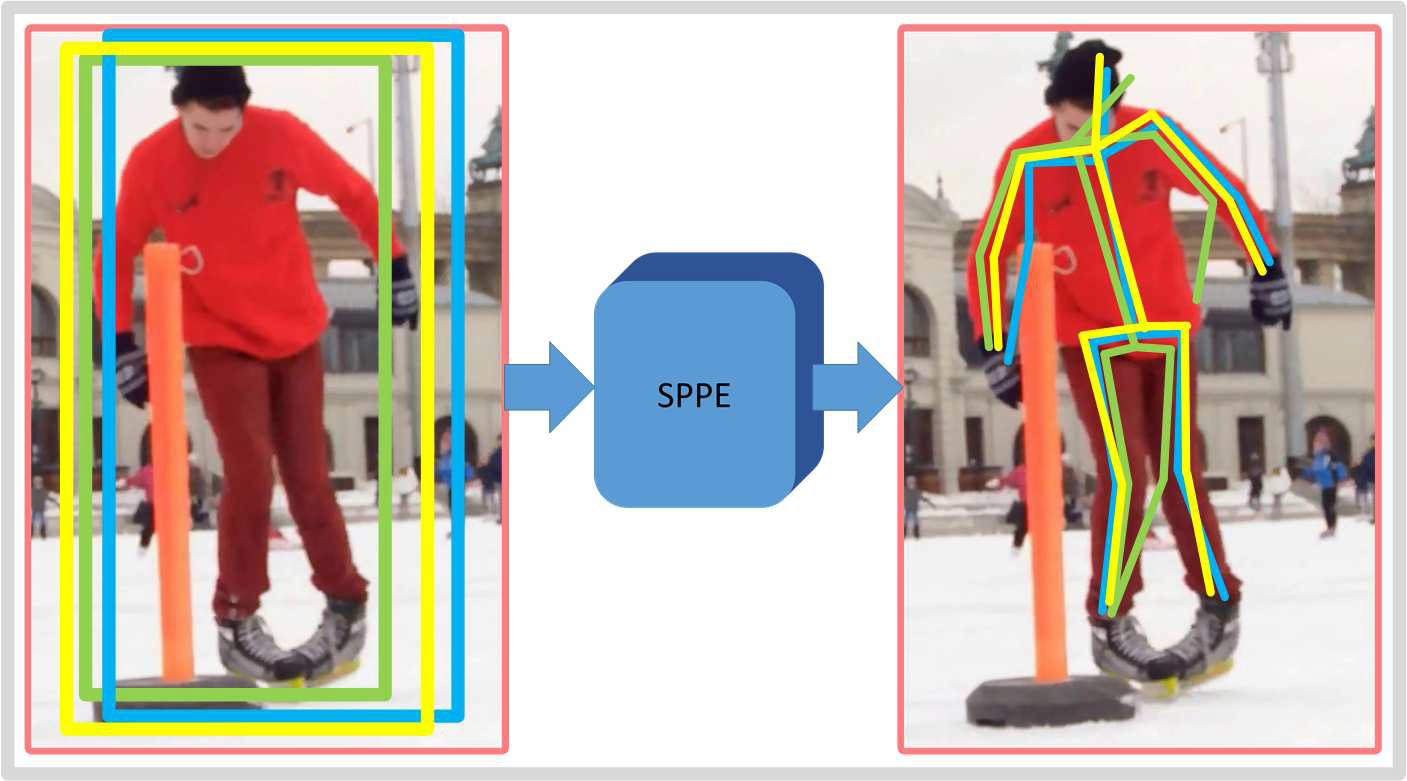
2.2 检测框冗余
如下图所示。同一个人可能检测到多个框。
解决方法:使用p-NMS来解决人体检测框不准确时的姿态估计问题。
3. 网络结构
3.1 总体结构
总体网络结构如下图:
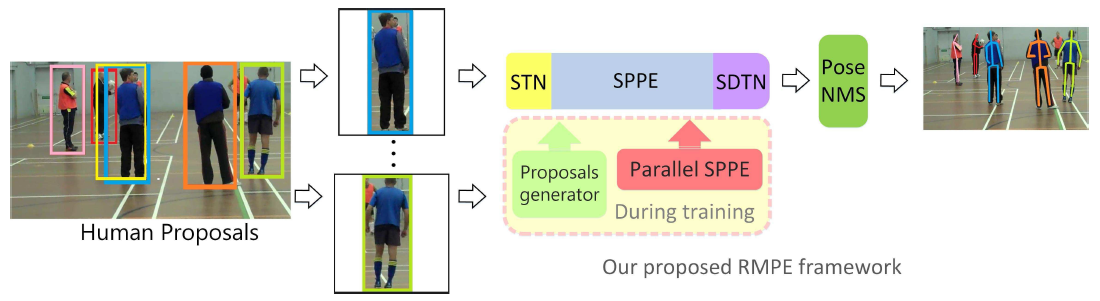
Symmetric STN=STN+SPPE+SDTN
STN:空间变换网络,对于不准确的输入,得到准确的人的框。输入候选区域,用于获取高质量的候选区域。
SPPE:得到估计的姿态。
SDTN:空间逆变换网络,将估计的姿态映射回原始的图像坐标。
Pose-NMS:消除额外的估计到的姿态
Parallel SPPE:训练阶段作为额外的正则项,避免陷入局部最优,并进一步提升SSTN的效果。包含相同的STN及SPPE(所有参数均被冻结),无SDTN。测试阶段无此模块。
PGPG(Pose-guided Proposals Generator):通过PGPG网络得到训练图像,用来训练SSTN+SPPE模块。
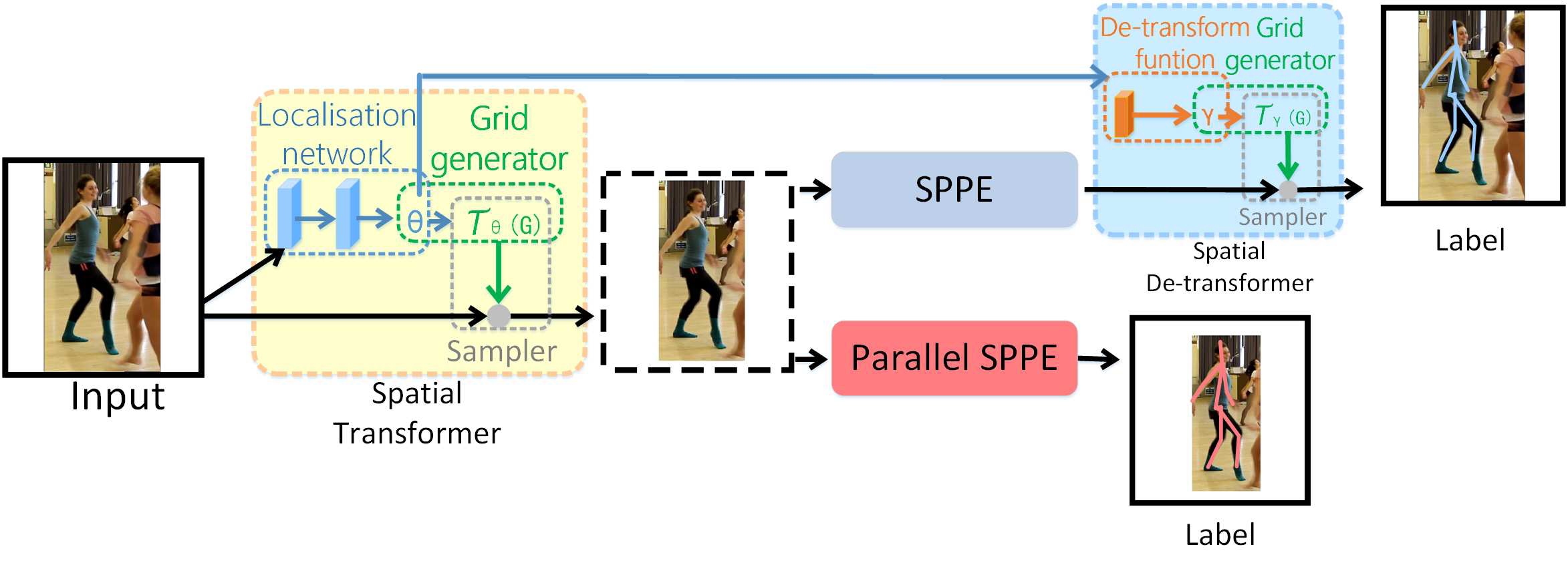
3.2 SSTN
SSTN如下图所示。不准确的输入(下图左侧input)经过STN+SPPE+SDTN,先姿态估计,把估计结果映射到原图,以此来调整原本的框,使框变的精准。其中中间黑色虚线的框认为是准确的输入(即中心化的输入,将姿态对齐到图像中心)。
3.3 STN和SDTN
STN为2D的仿射变换,定义如下:

SDTN定义如下:

其中 为变换后坐标,
为变换后坐标,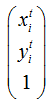 为变换前坐标。${{\theta }_{1}}$,${{\theta }_{2}}$,${{\theta }_{3}}$,${{\gamma }_{1}}$,${{\gamma }_{2}}$,${{\gamma }_{3}}$为变换参数关系如下:
为变换前坐标。${{\theta }_{1}}$,${{\theta }_{2}}$,${{\theta }_{3}}$,${{\gamma }_{1}}$,${{\gamma }_{2}}$,${{\gamma }_{3}}$为变换参数关系如下:

(使用SDTN进行反向传播的公式请见论文)
3.4 Parallel SPPE(PSPPE)
PSPPE模块和原始的SPPE共享相同的STN参数,但是无SDTN模块。此分支的人体姿态已经中心化,和中心化后的真知标签直接比较。训练阶段,PSPPE所有层的参数均被冻结,目的是反传中心化的姿态误差到STN模块。因而若STN得到的姿态未中心化,会产生较大的误差,使得STN集中于正确的区域。
可以讲PSPPE作为训练阶段额外的正则项。
3.5 P-NMS
定义:令第i个姿态由m个关节点组成,定义为$\left\{ \left\langle k_{i}^{1},c_{i}^{1} \right\rangle ,\cdots ,\left\langle k_{i}^{m},c_{i}^{m} \right\rangle \right\}$,其中k为location,c为socre。
消除过程:score最高的姿态作为基准,重复消除接近基准姿态的姿态,直到剩下单一的姿态。
消除准则:消除标准用于重复消除剩余姿态,为:
$f({{P}_{i}},{{P}_{j}}|\Lambda ,\eta )=\mathbf{1}(d({{P}_{i}},{{P}_{j}}|\Lambda ,\lambda )\le \eta )$
其中,距离函数$d(\centerdot )$包括姿态距离和空间距离,若$d(\centerdot )$不大于$\eta $,则上面$f(\centerdot )$的输出为1,表明由于${{P}_{i}}$和基准姿态${{P}_{j}}$过于相似,因而${{P}_{i}}$需要被消除。其定义如下:
$d({{P}_{i}},{{P}_{j}}|\Lambda )\text{=}{{K}_{Sim}}({{P}_{i}},{{P}_{j}}|{{\sigma }_{1}})+\lambda {{H}_{sim}}({{P}_{i}},{{P}_{j}}|{{\sigma }_{2}})$
其中,$\Lambda =\{{{\sigma }_{1}},{{\sigma }_{2}},\lambda \}$。
姿态距离用于消除和其他姿态太近且太相似的姿态,假定${{P}_{i}}$的bbox是${{B}_{i}}$,其定义为如下的soft matching公式(不同特征之间score的相似度):

其中$B(k_{i}^{n})$为中心在$k_{i}^{n}$的box,并且每个坐标$B(k_{i}^{n})$为原始坐标${{B}_{i}}$的1/10。
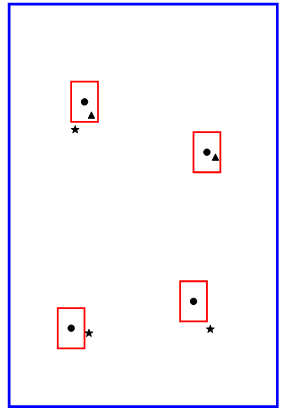
如下图所示。其中蓝框为关节点${{P}_{i}}$的框,各黑点为蓝框${{P}_{i}}$各个关节点位置$k_{i}^{n}$(为了方便,只显示了4个),各红框为宽高为蓝框1/10的子框,其中心为相应的关节点$k_{i}^{n}$,三角为姿态${{P}_{j}}$在红框内的关节点$k_{j}^{n}$,五星为姿态${{P}_{j}}$在红框外关节点$k_{j}^{n}$。进行消除时,对三角使用上式的if进行消除,因该点在子框内;对五星使用otherwise,因该点在子框外(左上角既有三角,又有五星。实际上对于一个检测到的姿态${{P}_{j}}$,是不会出现这种情况的,因为一个姿态的某个特定关节点只有一个,不会出现三角和五星两个关节点。此处只是显示使用)。
空间距离用于衡量不同特征之间空间距离的相似度,令$k_{i}^{n}$和$k_{j}^{n}$为不同特征中心,其定义如下:
${{H}_{sim}}({{P}_{i}},{{P}_{j}}|{{\sigma }_{2}})=\sum\limits_{n}{\exp [-\frac{{{(k_{i}^{n}-k_{j}^{n})}^{2}}}{{{\sigma }_{2}}}]}$
$\lambda $为平衡姿态距离和空间距离的权重。$\eta $为阈值。上式共四个参数${{\sigma }_{1}}$,${{\sigma }_{2}}$,$\lambda $,$\eta $,论文中说交替固定2个,训练另外两个。但是pytorch代码中全部固定了。
3.6 PGPG
步骤:
1 归一化姿态,使得所有躯干有归一化长度。
2 使用kmeans聚类对齐的姿态,并且聚类得到的中心形成atomic poses。
3 对有相同atomic poses的人,计算gt bbox和detected bbox的偏移。
4 偏移使用gt bbox进行归一化。
5 此时,偏移作为频率的分布,且固定数据为高斯混合分布。对于不同的atomic poses,有不同的高斯混合分布的参数。
注:没看此部分对应的代码
4. 代码
4.1 前向推断
网络前向推断使用InferenNet_fast函数,其中输入图像x为通过yolo V3检测到的单张人体。
输出为热图。out.narrow原因是,训练时使用了COCO和MPII,因而特征维数维33,前17层为COCO特征。代码中只测试COCO上性能,因而只取前17层热图。


1 class InferenNet_fast(nn.Module): 2 def __init__(self, kernel_size, dataset): 3 super(InferenNet_fast, self).__init__() 4 5 model = createModel().cuda() 6 print('Loading pose model from {}'.format('./models/sppe/duc_se.pth')) 7 model.load_state_dict(torch.load('./models/sppe/duc_se.pth')) 8 model.eval() 9 self.pyranet = model # 图像得到33维热图 10 self.dataset = dataset 11 12 def forward(self, x): 13 out = self.pyranet(x) # 得到b*33*h*w的矩阵 14 # https://github.com/MVIG-SJTU/AlphaPose/issues/187#issuecomment-441416429 指出,代码联合训练COCO和MPII,前17个为COCO,后16个为MPII,故此处取前17层 15 out = out.narrow(1, 0, 17) # data = tensor:narrow(dim, index, size)取出tensor中第dim维上索引从index开始到index+size-1的所有元素存放在data中 16 17 return out # 图像得到33维热图,取出channel上0—16维特征 18 19 20 def createModel(): 21 return FastPose() 22 23 24 class FastPose(nn.Module): 25 DIM = 128 26 27 def __init__(self): 28 super(FastPose, self).__init__() 29 self.preact = SEResnet('resnet101') # 101层SE_ResNet 30 self.suffle1 = nn.PixelShuffle(2) #将Input: (N, C∗upscale_factor * upscale_factor2, H, W)转换成输出Output: (N, C, H∗upscale_factor, W∗upscale_factor),此处upscale_factor=2 31 self.duc1 = DUC(512, 1024, upscale_factor=2) # conv+BN+ReLU+PixelShuffle, PixelShuffle将1024维降低到256维 32 self.duc2 = DUC(256, 512, upscale_factor=2) # conv+BN+ReLU+PixelShuffle, PixelShuffle将512维降低到128维 33 self.conv_out = nn.Conv2d(self.DIM, opt.nClasses, kernel_size=3, stride=1, padding=1) # 128维降低到33维 34 35 def forward(self, x: Variable): 36 out = self.preact(x) 37 out = self.suffle1(out) 38 out = self.duc1(out) 39 out = self.duc2(out) 40 41 out = self.conv_out(out) 42 return out 43 44 45 class DUC(nn.Module): 46 ''' 47 INPUT: inplanes, planes, upscale_factor 48 OUTPUT: (planes // 4)* ht * wd 49 ''' 50 def __init__(self, inplanes, planes, upscale_factor=2): 51 super(DUC, self).__init__() 52 self.conv = nn.Conv2d(inplanes, planes, kernel_size=3, padding=1, bias=False) 53 self.bn = nn.BatchNorm2d(planes) 54 self.relu = nn.ReLU() 55 56 self.pixel_shuffle = nn.PixelShuffle(upscale_factor) #将Input: (N, C∗upscale_factor * upscale_factor2, H, W)转换成输出Output: (N, C, H∗upscale_factor, W∗upscale_factor) 57 58 def forward(self, x): 59 x = self.conv(x) 60 x = self.bn(x) 61 x = self.relu(x) 62 x = self.pixel_shuffle(x) 63 return x
4.2 预测
预测代码如下:
1 def getPrediction(hms, pt1, pt2, inpH, inpW, resH, resW): # 由于对人体检测后裁剪的图像进行预测,后6个参数为裁剪图像的相关信息 2 '''Get keypoint location from heatmaps''' 3 assert hms.dim() == 4, 'Score maps should be 4-dim' 4 # 每个通道最大值作为关节点,因为是自顶向下,前提就是每张图只有一个人,因而每个通道只有一个关节点 5 maxval, idx = torch.max(hms.view(hms.size(0), hms.size(1), -1), 2) # hms.size(0)为batchsize,hms.size(1)为channels,热图中h*w变成一维后的最大值及索引 6 7 maxval = maxval.view(hms.size(0), hms.size(1), 1) # b*c*1的矩阵 8 idx = idx.view(hms.size(0), hms.size(1), 1) + 1 # b*c*1的矩阵,+1是用于防止计算xy坐标时错误 9 10 preds = idx.repeat(1, 1, 2).float() # b*c*2的矩阵,将第2维重复一遍 11 12 preds[:, :, 0] = (preds[:, :, 0] - 1) % hms.size(3) # 得到x坐标 13 preds[:, :, 1] = torch.floor((preds[:, :, 1] - 1) / hms.size(3)) # 得到y坐标 14 15 pred_mask = maxval.gt(0).repeat(1, 1, 2).float() # 最大值中大于0的第2维重复一遍 16 preds *= pred_mask # 去掉maxval小于0对应的坐标 17 18 # Very simple post-processing step to improve performance at tight PCK thresholds 19 for i in range(preds.size(0)): # 遍历batchsize中每个输入的预测 20 for j in range(preds.size(1)): # 遍历每个channels 21 hm = hms[i][j] # 当前热图 22 pX, pY = int(round(float(preds[i][j][0]))), int(round(float(preds[i][j][1]))) # 当前坐标 23 # 得到热图每个关节点的坐标后,进一步结合上下左右四个点,优化坐标(论文中没有提到) 24 if 0 < pX < opt.outputResW - 1 and 0 < pY < opt.outputResH - 1: # 当前坐标在特征图内 25 diff = torch.Tensor((hm[pY][pX + 1] - hm[pY][pX - 1], hm[pY + 1][pX] - hm[pY - 1][pX])) # 当前热图点右侧减左侧值,当前点热图下边减上边值 26 preds[i][j] += diff.sign() * 0.25 # diff.sign()得到diff每个元素的正负;此处将preds进行偏移 27 preds += 0.2 # preds进一步偏移?? 28 29 preds_tf = torch.zeros(preds.size()) 30 preds_tf = transformBoxInvert_batch(preds, pt1, pt2, inpH, inpW, resH, resW) # 热图中关节点坐标映射回原始图像上的坐标 31 32 return preds, preds_tf, maxval # 返回关节点在原始图像裁剪后图像上的坐标,在原始图像上的坐标,热图最大值
4.3 P-NMS
p _poseNMS.py配置参数如下(固定的参数,并未体现出通过训练得到):
1 delta1 = 1 2 mu = 1.7 3 delta2 = 2.65 4 gamma = 22.48 5 scoreThreds = 0.3 6 matchThreds = 5 7 areaThres = 0#40 * 40.5 8 alpha = 0.1 9 10 pose_nms如下: 11 def pose_nms(bboxes, bbox_scores, pose_preds, pose_scores): 12 ''' 13 Parametric Pose NMS algorithm 14 bboxes: bbox locations list (n, 4) 15 bbox_scores: bbox scores list (n,) # 各个框为人的score 16 pose_preds: pose locations list (n, 17, 2) 各关节点的坐标 17 pose_scores: pose scores list (n, 17, 1) 各个关节点的score 18 ''' 19 #global ori_pose_preds, ori_pose_scores, ref_dists 20 21 pose_scores[pose_scores == 0] = 1e-5 22 final_result = [] 23 24 ori_bbox_scores = bbox_scores.clone() # 各个框为人的score,下面要删除,此处先备份 25 ori_pose_preds = pose_preds.clone() # 各关节点的坐标,下面要删除,此处先备份 26 ori_pose_scores = pose_scores.clone() # 各个关节点的score,下面要删除,此处先备份 [n, 17, 1] 27 28 xmax = bboxes[:, 2] # 检测到的人在原始图像上的坐标 29 xmin = bboxes[:, 0] 30 ymax = bboxes[:, 3] 31 ymin = bboxes[:, 1] 32 33 widths = xmax - xmin # 检测到的人的宽高 34 heights = ymax - ymin 35 ref_dists = alpha * np.maximum(widths, heights) # alpha=0.1,为论文中的1/10,此处为NMS中当前batch各个人子框的阈值[n,] 36 37 nsamples = bboxes.shape[0] 38 human_scores = pose_scores.mean(dim=1) # 当前batch各个人姿态的均值 [n, 1] 39 human_ids = np.arange(nsamples) 40 pick = [] # Do pPose-NMS 41 merge_ids = [] 42 while(human_scores.shape[0] != 0): 43 pick_id = torch.argmax(human_scores) # Pick the one with highest score 找出分值最高的姿态的索引 44 pick.append(human_ids[pick_id]) # 由于后面要delete array的部分值,因而此处保存索引 45 # num_visPart = torch.sum(pose_scores[pick_id] > 0.2) 46 47 ref_dist = ref_dists[human_ids[pick_id]] # Get numbers of match keypoints by calling PCK_match 当前人NMS子框的阈值 48 simi = get_parametric_distance(pick_id, pose_preds, pose_scores, ref_dist) # 公式(10)的距离,[n],由于每次均会删除id,因而n递减 49 num_match_keypoints = PCK_match(pose_preds[pick_id], pose_preds, ref_dist) # 返回满足条件的点的数量,[n],由于每次均会删除id,因而n递减 50 51 # Delete humans who have more than matchThreds keypoints overlap and high similarity # gamma = 22.48,matchThreds = 5, 52 delete_ids = torch.from_numpy(np.arange(human_scores.shape[0]))[(simi > gamma) | (num_match_keypoints >= matchThreds)] # 迭代删除的索引 53 54 if delete_ids.shape[0] == 0: 55 delete_ids = pick_id 56 #else: 57 # delete_ids = torch.from_numpy(delete_ids) 58 59 merge_ids.append(human_ids[delete_ids]) # 每次筛选出来的人的索引,如果没有近距离的人,merge_ids==pick 60 pose_preds = np.delete(pose_preds, delete_ids, axis=0) 61 pose_scores = np.delete(pose_scores, delete_ids, axis=0) 62 human_ids = np.delete(human_ids, delete_ids) 63 human_scores = np.delete(human_scores, delete_ids, axis=0) 64 bbox_scores = np.delete(bbox_scores, delete_ids, axis=0) 65 66 assert len(merge_ids) == len(pick) 67 preds_pick = ori_pose_preds[pick] # 根据pick重新映射后的不同人各关节点的坐标 68 scores_pick = ori_pose_scores[pick] 69 bbox_scores_pick = ori_bbox_scores[pick] 70 #final_result = pool.map(filter_result, zip(scores_pick, merge_ids, preds_pick, pick, bbox_scores_pick)) 71 #final_result = [item for item in final_result if item is not None] 72 73 for j in range(len(pick)): # 人的数量。此处是当人体检测器检测的不好,同一个人检测到了2个以上的框,这些框比较接近的情况 74 ids = np.arange(17) 75 max_score = torch.max(scores_pick[j, ids, 0]) 76 77 if max_score < scoreThreds: 78 continue 79 80 merge_id = merge_ids[j] # Merge poses 81 # 返回冗余关节点位置和这些关节点对应的score。无冗余姿态的情况下,merge_pose==preds_pick[j]==ori_pose_preds[merge_id],merge_score==ori_pose_scores[merge_id] 82 merge_pose, merge_score = p_merge_fast(preds_pick[j], ori_pose_preds[merge_id], ori_pose_scores[merge_id], ref_dists[pick[j]]) 83 84 max_score = torch.max(merge_score[ids]) 85 if max_score < scoreThreds: 86 continue 87 88 xmax = max(merge_pose[:, 0]) 89 xmin = min(merge_pose[:, 0]) 90 ymax = max(merge_pose[:, 1]) 91 ymin = min(merge_pose[:, 1]) 92 93 if (1.5 ** 2 * (xmax - xmin) * (ymax - ymin) < areaThres): 94 continue 95 96 final_result.append({ 97 'keypoints': merge_pose - 0.3, 98 'kp_score': merge_score, 99 'proposal_score': torch.mean(merge_score) + bbox_scores_pick[j] + 1.25 * max(merge_score) 100 }) 101 102 return final_result 103 104 105 106 def PCK_match(pick_pred, all_preds, ref_dist): 107 dist = torch.sqrt(torch.sum(torch.pow(pick_pred[np.newaxis, :] - all_preds, 2), dim=2 )) # 当前点和其他所有点的距离 [n, 17] 108 ref_dist = min(ref_dist, 7) 109 num_match_keypoints = torch.sum(dist / ref_dist <= 1, dim=1) # 得到满足条件的点的数量 [n] 110 return num_match_keypoints # 返回满足条件的点的数量 111 112 113 114 def get_parametric_distance(i, all_preds, keypoint_scores, ref_dist): 115 pick_preds = all_preds[i] # 当前预测关节点的坐标 116 pred_scores = keypoint_scores[i] # 当前预测关节点的分值 117 dist = torch.sqrt(torch.sum(torch.pow(pick_preds[np.newaxis, :] - all_preds, 2), dim=2)) # 当前人关节点和所有人关节点的距离 [n, 17] 118 mask = (dist <= 1) # 当前人关节点和所有人关节点的mask,此处指如果两套关节点距离太小(因是二维矩阵,不会出现某人部分关节点mask=1),则mask=1,一般来说,只是本人关节点mask=1 [n, 17] 119 120 score_dists = torch.zeros(all_preds.shape[0], 17) # Define a keypoints distance 121 keypoint_scores.squeeze_() 122 if keypoint_scores.dim() == 1: 123 keypoint_scores.unsqueeze_(0) # 增加维度 124 if pred_scores.dim() == 1: 125 pred_scores.unsqueeze_(1) # 增加维度 126 pred_scores = pred_scores.repeat(1, all_preds.shape[0]).transpose(0, 1) # The predicted scores are repeated up to do broadcast。 [n, 1] 127 128 # 由于broadcast,pred_scores!=keypoint_scores,但是pred_scores[mask] == keypoint_scores[mask] 129 score_dists[mask] = torch.tanh(pred_scores[mask] / delta1) * torch.tanh(keypoint_scores[mask] / delta1) # delta1 = 1,当前点和近距离点的score的相似度,公式(8) 130 131 point_dist = torch.exp((-1) * dist / delta2) # delta2 = 2.65,当前点和近距离点的距离的相似度,公式(9) 132 final_dist = torch.sum(score_dists, dim=1) + mu * torch.sum(point_dist, dim=1) # mu = 1.7,最终的距离 [n] 133 134 return final_dist # 返回最终的距离 135 136 137 # 如果人体检测器效果很好,无冗余检测,则此函数无效 138 def p_merge_fast(ref_pose, cluster_preds, cluster_scores, ref_dist): 139 ''' 140 Score-weighted pose merging 141 INPUT: 142 ref_pose: reference pose -- [17, 2] ref_pose # 根据pick重新映射后的当前人各关节点的坐标 143 cluster_preds: redundant poses -- [n, 17, 2] cluster_preds # 筛选出来的当前人各关节点的坐标 144 cluster_scores: redundant poses score -- [n, 17, 1] cluster_scores # 筛选出来的当前人各个关节点的score 145 ref_dist: reference scale -- Constant ref_dist # 根据pick重新映射后当前人NMS子框的阈值 146 OUTPUT: 147 final_pose: merged pose -- [17, 2] 148 final_score: merged score -- [17] 149 ''' 150 # 无冗余姿态的情况下,ref_pose==cluster_preds==final_pose,dist=[[0....0]] 17个 151 dist = torch.sqrt(torch.sum(torch.pow(ref_pose[np.newaxis, :] - cluster_preds, 2), dim=2)) 152 153 kp_num = 17 154 ref_dist = min(ref_dist, 15) 155 156 mask = (dist <= ref_dist) 157 final_pose = torch.zeros(kp_num, 2) 158 final_score = torch.zeros(kp_num) 159 160 if cluster_preds.dim() == 2: 161 cluster_preds.unsqueeze_(0) # [17,2] ==> [1, 17, 2] 162 cluster_scores.unsqueeze_(0) # [17,1] ==> [1, 17, 1] 163 if mask.dim() == 1: 164 mask.unsqueeze_(0) # [1,17] ==> [1, 17] 不变 165 166 # Weighted Merge 167 masked_scores = cluster_scores.mul(mask.float().unsqueeze(-1)) # [1, 17, 1] 冗余score乘以mask,并进行归一化 168 normed_scores = masked_scores / torch.sum(masked_scores, dim=0) # [1, 17, 1] 的全1矩阵 169 170 # 冗余关节点位置乘归一化分数,得到冗余关节点位置。无冗余姿态的情况下,无冗余姿态的情况下,ref_pose==cluster_preds==final_pose 171 final_pose = torch.mul(cluster_preds, normed_scores.repeat(1, 1, 2)).sum(dim=0) 172 # 归一化之前的冗余关节点分数 final_score==cluster_scores==masked_scores 173 final_score = torch.mul(masked_scores, normed_scores).sum(dim=0) 174 175 return final_pose, final_score # 返回冗余关节点位置和这些关节点对应的score
posted on 2020-01-04 19:51 darkknightzh 阅读(25925) 评论(2) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号