

CDH集群spark-shell执行过程分析
目的
刚入门spark,安装的是CDH的版本,版本号spark-core_2.11-2.4.0-cdh6.2.1,部署了cdh客户端(非集群节点),本文主要以spark-shell为例子,对在cdh客户端上提交spark作业原理进行简单分析,加深理解
spark-shell执行
启动spark-shell后,可以发下yarn集群上启动了一个作业,实际上,cdh-spark默认提交作业模式为yarn-client模式,即在本地运行Driver,作业在yarn集群上执行
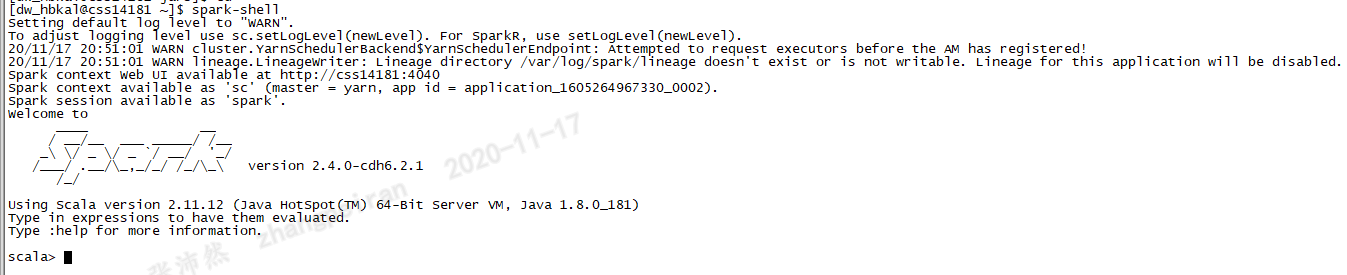
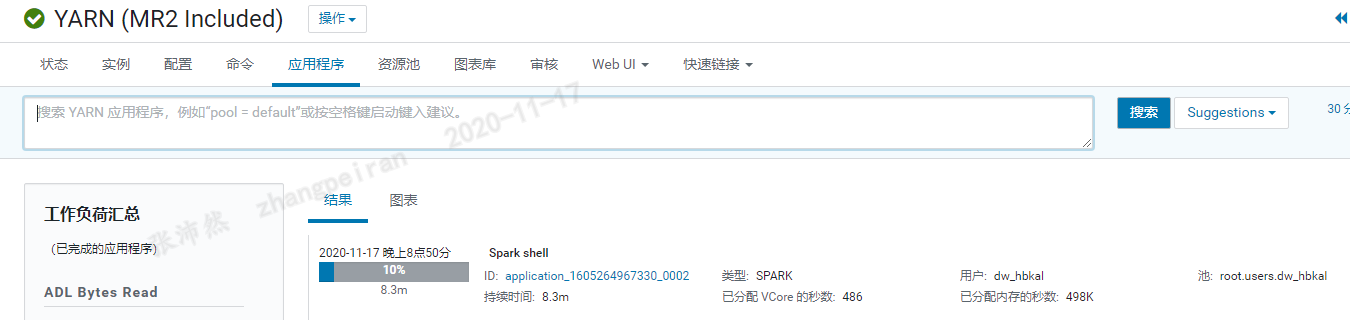
spark-shell启动过程分析
查看spark-shell路径及内容,$LIB_DIR值为/opt/cloudera/parcels/CDH/lib,所以执行的是/opt/cloudera/parcels/CDH/lib/spark/bin/spark-shell
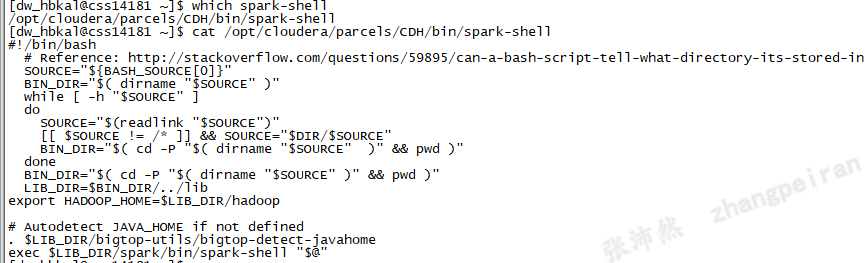
继续查看/opt/cloudera/parcels/CDH/lib/spark/bin/spark-shell,脚本关键的内容如下:
#!/usr/bin/env bash
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
export _SPARK_CMD_USAGE="Usage: ./bin/spark-shell [options]"
SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Dscala.usejavacp=true"
function main() {
export SPARK_SUBMIT_OPTS
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
fi
}
main "$@"
上述脚本中首先判断是否存在SPARK_HOME变量,如果不存在的话就执行同一目录下的find-spark-home脚本,改脚本中如果存在SPARK_HOME存在,则直接返回。如果不返回,则查看当前目录下,是否有find_spark_home.py文件。如果存在find_spark_home.py文件,则调用python执行获取结果。如果不存在,则使用当前bin目录的上一级为SPARK_HOME,在本环境中SPARK_HOME被设置为/opt/cloudera/parcels/CDH/lib/spark,设置好SPARK_HOME之后,调用了spark-submit脚本。
查看spark-submit脚本,发现其调用的是${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit,继续查看spark-class脚本,主要内容如下:
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
. "${SPARK_HOME}"/bin/load-spark-env.sh
# Find the java binary
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# Turn off posix mode since it does not allow process substitution
set +o posix
CMD=()
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
spark-class中,首先设置了spark-home,然后执行load-spark-env.sh,并添加${SPARK_HOME}/jars目录下的spark依赖,最后执行的是org.apache.spark.launcher.Main类,继续查看load-spark-env.sh
,改脚本主要是设置一些环境变量,关键内容如下:首先是设置spark_home,然后设置${SPARK_CONF_DIR},并执行该目录下的spark-env.sh,SPARK_CONF_DIR默认为spark-home下的的conf目录,本环境为/opt/cloudera/parcels/CDH/lib/spark/conf
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# Save SPARK_HOME in case the user's spark-env.sh overwrites it.
ORIGINAL_SPARK_HOME="$SPARK_HOME"
if [ -z "$SPARK_ENV_LOADED" ]; then
export SPARK_ENV_LOADED=1
export SPARK_CONF_DIR="${SPARK_CONF_DIR:-"${SPARK_HOME}"/conf}"
if [ -f "${SPARK_CONF_DIR}/spark-env.sh" ]; then
# Promote all variable declarations to environment (exported) variables
set -a
. "${SPARK_CONF_DIR}/spark-env.sh"
set +a
fi
fi
继续查看spark-env.sh内容,改脚本中直接设置了spark_home和hadoop_home目录,另外比较重要的是HADOOP_CONF_DIR和HIVE_CONF_DIR,如果没有设置的话,默认为cdh中提供配置文件,否则为用户设置的值,我们的环境bashrc中都设置了这两个变量,因此运行spark-shell时,会知道yarn集群的信息,建议使用spark-sql以及yarn模式运行作业是设置这两个变量
#!/usr/bin/env bash
SELF="$(cd $(dirname $BASH_SOURCE) && pwd)"
if [ -z "$SPARK_CONF_DIR" ]; then
export SPARK_CONF_DIR="$SELF"
fi
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/spark
SPARK_PYTHON_PATH=""
if [ -n "$SPARK_PYTHON_PATH" ]; then
export PYTHONPATH="$PYTHONPATH:$SPARK_PYTHON_PATH"
fi
export HADOOP_HOME=/opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop
export HADOOP_COMMON_HOME="$HADOOP_HOME"
if [ -n "$HADOOP_HOME" ]; then
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
SPARK_EXTRA_LIB_PATH=""
if [ -n "$SPARK_EXTRA_LIB_PATH" ]; then
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SPARK_EXTRA_LIB_PATH
fi
export LD_LIBRARY_PATH
HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-$SPARK_CONF_DIR/yarn-conf}
HIVE_CONF_DIR=${HIVE_CONF_DIR:-/etc/hive/conf}
if [ -d "$HIVE_CONF_DIR" ]; then
HADOOP_CONF_DIR="$HADOOP_CONF_DIR:$HIVE_CONF_DIR"
fi
export HADOOP_CONF_DIR
PYLIB="$SPARK_HOME/python/lib"
if [ -f "$PYLIB/pyspark.zip" ]; then
PYSPARK_ARCHIVES_PATH=
for lib in "$PYLIB"/*.zip; do
if [ -n "$PYSPARK_ARCHIVES_PATH" ]; then
PYSPARK_ARCHIVES_PATH="$PYSPARK_ARCHIVES_PATH,local:$lib"
else
PYSPARK_ARCHIVES_PATH="local:$lib"
fi
done
export PYSPARK_ARCHIVES_PATH
fi
if [ -f "$SELF/classpath.txt" ]; then
export SPARK_DIST_CLASSPATH=$(paste -sd: "$SELF/classpath.txt")
fi

 浙公网安备 33010602011771号
浙公网安备 33010602011771号