
3.3 虚拟内存 Virtual Memory
我们通过 base and limit registers 实现 address spaces,但是还有新的问题需要解决:管理臃肿的软件(mamaging bloatware)。
部分程序过大而无法加载到内存,或者需要同时运行的程序,它们每一个所需要的内存都小于物理内存,但是总和又超过物理内存。而 swap 又受到磁盘吞吐量的制约。
早期的解决方案是覆盖层(overlays),程序员手动将程序划分为不同的 overlay,通过 overlays manager 管理。
当程序启动时,先将 overlays manager 加载进内存并执行,由 overlays manager 加载 overlay 0,当 overlay 0 执行完成后,再加载 overlay 1 到内存。如果此时还有内存的话,overlay 1 会被加载到 overlay 0 之上,如果没有足够的内存的话,就会覆盖 overlay 0。
需要程序员手动划分 overlay 并编写 overlays manager,对程序员而言繁琐且容易出错。所以不妨将这个工作交给计算机,于是就有了虚拟内存(virtual memory)。
虚拟内存的基本思想是,将程序的地址空间分割为一个个页(page),即每个页就是一段连续的地址空间,页可以被映射到真实的物理内存上。
为什么程序不完全加载到内存就无法执行?
实际上,与是否使用了虚拟内存无关。只要程序不完全进入内存中,就无法完整地运行。
假设程序只有一部分加载到了内存,当 CPU 执行到这部分的最后一条指令时,PC 寄存器指向下一条指令的地址,但是由于程序的下半部分没有加载到内存,此时 PC 寄存器指向的地址对应的指令说不定是哪个野鸡程序的某一段指令,显然这样无法正常运行程序。
虚拟内存当然也存在这个问题。但是在虚拟内存中,当执行到未加载到内存中的地址时,虚拟内存会将这个地址所在的页加载到内存中,然后再执行这个地址对应的指令。
虚拟内存在多任务系统上表现优异。当一个程序等待页交换时,CPU 可以调度给其他进程使用。
3.3.1 分页 Paging
地址可以由索引、基址寄存器、段寄存器或者其他方式生成。这些由程序生成的地址被称为虚拟地址(virtaul address),并且组成虚拟地址空间(virtaul address space)。
在没有虚拟内存的机器中,虚拟地址被直接当作物理地址使用。而在虚拟内存中,虚拟地址被内存管理单元(memory management unit)翻译为物理地址。
虚拟地址控件由多个固定大小的单元(页)组成,与之对应的物理内存块称为页帧(page frame)。页和页帧一般大小一致,一般是 4KB,但在实际应用中,从 512 Bytes 到几 GB 不等。
假设一个 16 位的机器,那么可用虚拟地址就有 64KB,但是这台机器只有 32KB 的物理内存。页的大小为 4KB,那么虚拟内存可以被划分为 16 个页面,物理内存划分为 8 个页帧。虚拟内存页被映射在不同的物理页帧中。
页面映射如下:
当程序访问某个虚拟地址时,比如 1528,位于虚拟页面 0 (起始虚拟地址为 1528 ),对应物理页帧 2(起始物理地址为 8192),那么将虚拟地址转为物理地址 = 1528 - 0 + 8192 = 9720
使用一个存在位来标记当前页是否存在在内存中。当访问的地址对应的页面不在内存中时,触发缺页中断(page fault),中断处理程序(操作系统)将需要访问的页加载到内存,如果空闲的页帧不够,那么就会选择其中一个物理页进行交换。
3.3.2 页表 Page Table
页表:存储虚拟地址和物理地址信息的结构,能够实现虚拟地址到物理地址的映射。
虚拟地址映射为物理地址:高位地址表征为页编号(索引),低位地址表征为页偏移。
通过页索引在页表中找到对应的页帧编号,将虚拟地址的高位地址替换为页帧的高位地址,即完成了虚拟地址到物理地址的转换。
页表项的结构 Structure of a Page Table Entry
| 表项 | 作用 |
|---|---|
| page frame number | 页帧编号,用于索引物理页帧 |
| present/absent | 存在位(有效位):是否有对应的物理页 |
| protection | 保护位,限制页面的访问权限,只读/读写。更复杂权限控制 rwx 三位 |
| modified | 标记页面内容是否被修改过(dirty bit),决定了在页面交换时,抛弃这个页,还是写回磁盘 |
| referenced | 当前页面是否正在被引用,正在被引用的页,不应当被替换出去 |
| caching disabled | 禁用缓存,指示这个页面是否可以被缓存(可参考 c++ volatile) |
页表仅管理内存中的页,换出页的磁盘地址由操作系统自行维护。
3.3.3 加速分页 Speeding Up Paging
两个问题:
- 从虚拟地址到物理地址的映射必须足够快
- 每次引用内存地址时,都需要将虚拟地址映射为物理地址;
- 所有的指令都需要从内存中加载;
- 大多数指令都需要操作内存地址;
- 每个指令可能涉及到一个或多个内存地址的引用。
- 当虚拟地址空间很大时,页表也会很大
- 现代操作系统中,页表一般是 4KB,而地址位数是 32 位甚至 64 位,如果要将一个进程的地址空间全部分页,需要大量的内存来存放页表;
- 每个进程都有自己独立的页表。
最简单的设计方案,使用特殊的硬件寄存器组成页表缓存,将进程的所有页表项都加载到寄存器中。
优点:从虚拟地址到物理地址的映射过程不需要访问内存,加快了映射的速度
缺点:
- 每次上下文切换时,都需要从内存中加载完整的页表,导致性能下降
- 当页表很大时,成本特别高
快表 Translation Lookaside Buffers
在实践中发现,程序中只有很少一部分页面会被大量读取。基于这一特性,使用名为 TLB(Translation Lookaside Buffers) 的硬件设备,存储虚拟内存到物理内存的映射。TLB 一般位于 MMU 内部,可以存储少量的页表项。
本质上 TLB 是页表的缓存。TLB 命中时,直接从 TLB 中读取 page,否则从页表读取并替换 TLB 条目。
软件 TLB 管理 Software TLB Management
主要在 MIPS RISC 架构的机器上使用,这些机器缺少 TLB 硬件,需要操作系统参与 TLB 管理。
当 TLB 不命中时:
- 硬件 TLB:MMU 硬件从页表中寻找需要的页面
- 软件 TLB:产生 TLB 不命中中断,由操作系统处理中断,找到需要的页面
当 TLB 的容量足够大时,可以有效降低 TLB 不命中概率,提高软件 TLB 的管理效率。
可以降低 TLB 不命中率和处理 TLB 不命中的处理耗时的方法:
- TLB 项预取:预测接下来将要使用的 TLB 项
- TLB 软件缓存:
当 TLB 未命中时,需要在页表中检索目标页。操作系统需要访问页表,如果页表对应的页不在 TLB 中,操作系统需要从页表中找到这个页,如果页表页不在 TLB 中就会导致额外的 TLB 不命中。
可以在 TLB 的固定位置维护一个页表页的缓存,其中的页面不会被替换。
TLB 不命中的分类:
- soft miss: 页不在 TLB 中,但是在内存中。
- hard miss: 也不在 TLB 中也不在内存中,需要从磁盘加载页面。
hard miss 的开销远远大于 soft miss。
page fault 的分类:
- minor page fault: 页表中没有页,但是内存中有页。可能是这个页面被其他进程从磁盘带到了内存中,操作系统仅仅需要做一下映射。
进程首次访问共享库的页面时,需要操作系统做一次映射。
- major page fault: 内存中没有页面,需要从磁盘读取。
- segmentation fault: 进程访问了无效或者非法的地址。
3.3.4 大内存的页表 Page Tables for Lager Memories
多级页表 Mutlilevel Page Table
以 32 位地址为例,高 10 位是 PT1,中间 10 位是 PT2,低 12 位作为偏移量。
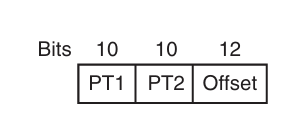
页表被组组织为树形结构:
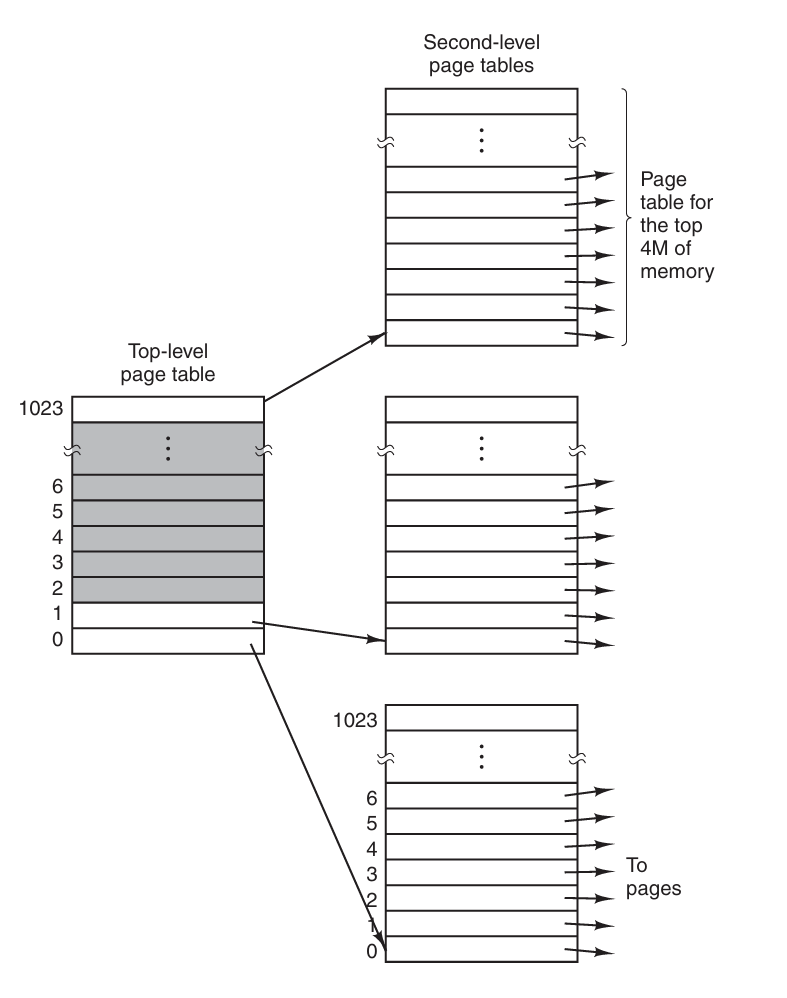
当 CPU 访问一个地址时,以 PT1 作为索引在一级页表中找到一个页表项,这个页表项指向二级页表中的一个页表,然后通过 PT2 找到二级页表项,最后根据偏移量在物理页中找到需要访问的内存。
多级的页表的优势在于不需要所有的页表都处于内存中,当一个进程的地址空间特别大时,可以节省出大量的内存空间。
32 位内存地址对应 4GB 地址空间, 一般情况下,进程的内存只有几 MB 到几百 MB,剩余的地址空间全都对应未分配的页面。
如果只使用一级页表,那么页表将包含 1M 个页表项,其中大部分的有效位都是0,表示未分配的页面。如果使用二级页表,只需要将一级页表中页表项的有效位置 0 就可以表示 1024 个未分配页面。
反转页表 Inverted Page Table
-
传统页表:每个进程都有一个自己的页表,将进程的地址空间映射到物理内存上
-
反转页表:整个系统中只存在一个页表,将物理内存页映射到虚拟页
在反转页表中,每个页表项都包含这个页面对应的进程 n 和虚拟页 p 。当进程 n 需要访问虚拟页 p 时,无法通过虚拟页 p 索引到物理页,必须遍历所有的页表项,找到对应的 (n, p)。
每次内存访问都需要遍历页表,这就导致地址翻译的效率大大降低。
可以在 TLB 中缓存常用的页面,提高地址翻译的效率,但是 TLB 不命中的代价还是很高,可以通过哈希表对虚拟页(n, p)进行散列操作,使用链地址法解决哈希冲突问题,将时间复杂度降低到 O(1)。
简单给出一个反转页表的哈希数据结构,虚拟页号和进程 id 作为参与哈希计算。
struct hash_entry {
uint64_t vpn; // 虚拟页号
uint32_t pid; // 进程ID或ASID
uint32_t pfn; // 物理页帧号
uint8_t flags; // 状态标志(有效位、脏位等)
struct hash_entry *next; // 冲突链表的下一项
};

 浙公网安备 33010602011771号
浙公网安备 33010602011771号