3.2 一种内存抽象:地址空间 A Memory Abstraction: Address Spaces
直接使用物理内存的缺点:
- 多个进程直接会互相篡改,甚至影响到系统内核
- 无法实现多进程同时运行
3.2.1 地址空间的概念 The Notion of an Address Space
地址空间是在一个进程所使用的所有地址的集合。
每个进程都有自己独立的地址空间。
如何将抽象的地址空间和实际的物理地址联系起来?
基址和界限寄存器 Base and Limit Registers
通过基址寄存器保存程序在内存中的开始位置(物理内存地址),界限寄存器保存程序的长度,将地址空间完整地、线性地映射到物理内存上。
物理地址 = 抽象地址 + 基址地址
进程在引用内存、取指令或者读写数据时,都会通过上述方式,将地址空间映射为真实地物理地址。
3.2.2 交换 Swapping
如果系统中存在大量进程,需要的内存总量超过主存的容量,如何处理?
通过 交换(swap) 将一部分被空闲的进程交换到磁盘中,等到需要执行时,再从磁盘中加载整个内存。
如果某个进程所需要的内存超过了主存的容量,如何执行这个进程?
借助 虚拟内存(virtual memory),即使内存中只有进程一部分内容,也可以正常运行。
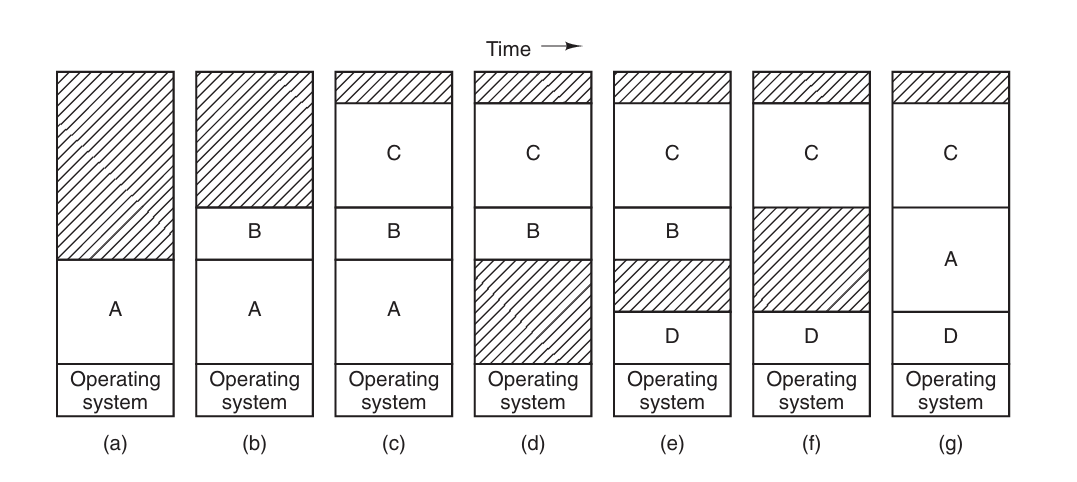
进程在交换前后,在内存中的位置(物理地址)可能不一样,那么就需要通过 重定向(relocation) 来调整进程的内存地址。
例如:基址和界限寄存器。
在进程交换的过程中,可能会出现内存碎片(空洞)。较大的内存碎片可以使用其他进程来填充,较小的内存碎片无法被其他进程再利用,如果不加以管理的话,会导致这部分内存浪费。操作系统通过 内存压缩(memory compaction) 回收再利用内存碎片。
通过交换进程的位置,将小内存碎片整理为较大的内存空间。这种方式会消耗大量的 CPU 时间,所以一般不做此操作。
如果进程的内存大小不会改变,只需要分配给这个进程一块足够的内存即可,但是如果进程内存会不断增长(在堆上动态分配内存),那么操作系统也需要适当的调整进程的位置或者内存空间来满足进程的内存需求。
简单地说,当连续的空间不够时,将进程移动到另一个足够大的内存空间中,或者交换其他进程拼凑出一块内存。但是当系统内存不够而且磁盘上的交换区也被占满时,那么进程将被挂起等待内存释放,或者触发 oom 导致进程被杀掉。
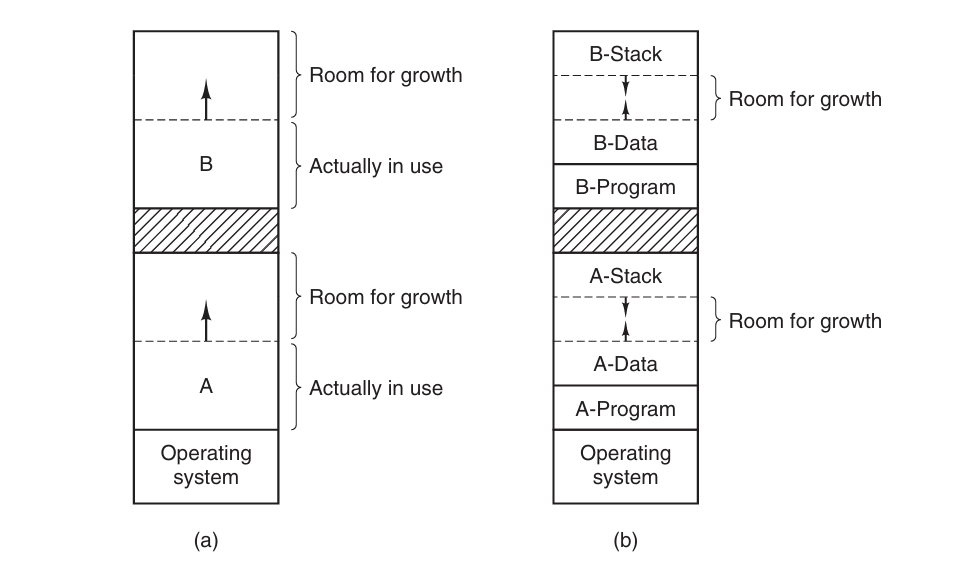
在给进程分配内存时,可以多分配一些额外的空间,进程的内存向这个方向增长。有一些进程有两个段需要增长,比如堆和栈。一般将栈放在高地址向低地址增长,而堆在低地址向高地址增长,二者相向增长。不过这些(额外的)内存用完后,还是需要移动进程。
3.2.3 空闲内存管理 Managing Free Memory
操作系统通过 位图(bitmap) 或者 可用空间表(free lists) 来跟踪内存,以此管理动态分配的内存。
使用位图的内存管理 Memory Management with Bitmap
以几字节到几千字节为单位分割内存,每个单元映射为位图中的一个比特位,0 表示这个内存单元空闲,1 表示被使用。
需要权衡单元的大小,太小会导致位图过大,太大会导致内存空间浪费(一个位对应的内存空间只是用了很少一部分)。
当要寻找一个连续 K 字节的内存空间时,位图的搜索效率很低。
使用链表的内存管理 Memory Management with Linked List
链表的每个节点表示一个进程或者一个内存碎片,由四部分组成:
- 标志位,P(进程),H(内存碎片)
- 开始地址
- 长度
- 指向其他节点的指针
当一个进程终止后,它的内存空间被系统回收,形成一个内存碎片,任意两个相邻的内存碎片节点合并为一个新的节点。使用双向链表更方便找到前驱节点。
一般来说,链表的节点以地址迅速排序,可以使用如下内存分配算法:
first fit:每次从头开始寻找一个空闲节点,直到找到一个适合内存碎片节点。
- 效率高,只需要搜索部分链表,时间复杂度往往小于 \(O(n)\);
- 实现简单。
next fit:和 first fit 算法基本一样,不过每次搜索后记录这次搜索到的位置,下一次搜索时,从上次记录的位置开始(而不是从头开始)。
- 效率高,性能只比 first fit 略差,时间复杂度往往小于 \(O(n)\);
- 实现简单。
best fit:遍历整个链表,找到所有不小于指定大小的内存碎片,选取其中最小的一个。
- 效率低,需要遍历整个链表,时间复杂度 \(O(n)\);
- 空间利用率更低,best fit 算法会产生大量无法使用的内存碎片,而 first fit 和 next fit 则可以产生更大的内存碎片,便于再次使用。
worst fit: 和 best fit 相反,worst fit 总是选择可用内存碎片中最大的一个,便于产生更大的内存碎片。
- 效率低,需要遍历整个链表,时间复杂度 \(O(n)\);
- 从模拟实验来看,worst fit 的效果并不好。
上述四种内存分配算法,都需要遍历(部分)链表,内存分配时,操作系统只关心内存碎片,没必要检索进程节点,所以按照节点的种类,将链表分离为进程链表和内存碎片链表,可以提高内存分配的速度。
那么,古尔丹,代价是什么?
当一个进程退出时,操作系统需要合并相邻的内存碎片节点,显然,这种数据结构寻找相邻节点的时间复杂度比单独一个链表高出一个数量级.
单一链表可以直接找到相邻的节点,时间复杂度是 \(O(1)\),而分离链表的场景下,需要遍历内存碎片链表,时间复杂度是 \(O(n)\)。
在 best fit 和 worst fit 中,如果维护一个有序的链表,按照内存碎片的大小排序,就可以提高 best fit 和 worst fit 的效率。此时,由于节点的顺序和内存地址的顺序无关,也就不需要双向链表来维护邻居,可以简单的使用单链表。
根据链表的升降顺序的不同,first fit 自动退化为 best fit(升序)或者 worst fit(降序)。而 next first 就完全没有使用价值了。
对于内存碎片链表,不需要使用额外的空间来维护链表结构,完全可以将链表节点的信息写入每个内存碎片中,而且也不需要标志位。
quick fit:将内存碎片分割为一系列大小不同的链表。比如,4KB 一组,8KB 一组,12KB 一组,等等。举例:21KB大小的内存碎片,可以添加到 20KB 的链表,或者其他特殊的链表中。
- 优点:查找合适的内存碎片时特别快。
- 缺点:合并内存碎片困难,不合并的话又会导致大量不可用的内存碎片。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号