第一次个人编程作业
GitHub:GITHUB
代码设计
代码思路:
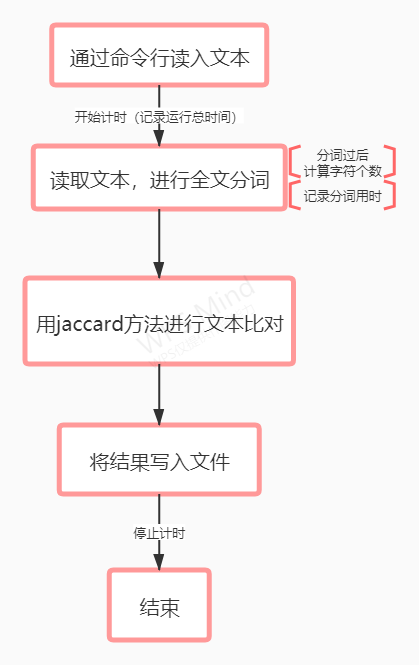
具体设计(主要函数)
1.使用jieba分词库进行分词,用lcut_for_search直接分词生成列表,全文分词,建立停用词列表(感觉上用一些助词什么的就够用了),只取中文字符
def msplit(txts):#jieba分词然后去掉符号
txts_ch = []
txt_word = jieba.lcut_for_search(txts)
stop_word=['啊','吧','呀','呢','的','得','她','它','他']
for i in range(0,len(txt_word)):
if is_Chinese(txt_word[i]):
if txts[i] in stop_word:
continue
elif txt_word[i]:
txts_ch += txt_word[i]
return txts_ch
2.读取文件,调用分词函数(showInfo函数是多加的计算中文字符个数)
def readTXT(txtfile):
print('*' * 80)
print('文件', '加载中……')
t1 = datetime.datetime.now()
texts = open(txtfile,encoding='UTF-8').read()
ms = msplit(texts)
t2 = datetime.datetime.now()
print('加载完成并分词完成,用时: ', t2 - t1)
showInfo(texts,txtfile)
return ms
3.jaccard方法进行相似度对比,这个方法我觉得就是就是对比两个字符串这种形式进行相似度的对比,里面的核心我觉得是取交集和并集再进行计算,这个的准确率我觉得在大多情况结果还是看的过去的,但是并不精确
def jaccard_similarity(txt1, txt2):
def add_space(txt):
return ' '.join(list(txt))
txt1, txt2 = add_space(txt1), add_space(txt2)
vectorizer = CountVectorizer(tokenizer=lambda txt: txt.split())
corpus = [txt1, txt2]
vectors = vectorizer.fit_transform(corpus).toarray()
numerator = np.sum(np.min(vectors, axis=0))
denominator = np.sum(np.max(vectors, axis=0))
return 1.0 * numerator / denominator
4.在这个代码通过了以后还尝试了TF-IDF模型,输出了结果,但是结果非常不理想555
运行结果
两个文件对比的结果,用的是给出的orig系列文件,结果看起来还行hhhhh
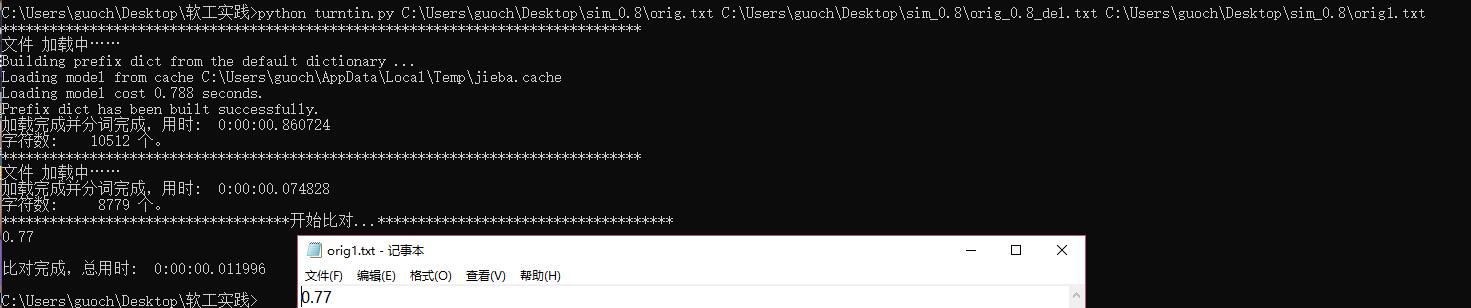
特别的地方
就是加了一些计数器,记录分词时间,还有整个代码运行时间,还有进行字符个数统计,都是一些小动作
总感觉这个计算方法感觉简单一些,不踏实hhhh
性能分析
使用的是pycharm自带的性能分析
从程序运行总时间来看,程序还是过得去的

单元测试
测试代码
使用了unittest模块进行测试,用了以后感觉就是好厉害的样子hhhh,这是新的尝试,很有意思
封装
def start_solve(position):
start = open(position, 'r', encoding='UTF-8')
start_text = start.read()
start.close()
start_items = msplit(start_text)
return start_items
def test_solve(position):
test = open(position, 'r', encoding='UTF-8')
txt_test = test.read()
test.close()
test_items = msplit(txt_test)
return test_items
def write_dir(ans,ans_position):
str1 = str('0.2f' %ans)
ans_text = open(ans_position,'w',encoding='UTF-8')
ans_text.write(str1)
ans_text.close()
def solveok(start_position,test_position,ans_position):
start_items = start_solve(start_position)
test_items = test_solve(test_position)
ans = jaccard_similarity(start_items,test_items)
write_dir(ans,ans_position)
print('%.2f' %ans)
def is_Chinese(word):
for ch in word:
if '\u4e00' <= ch <= '\u9fff':
return True
return False
def msplit(txts):#jieba分词然后去掉符号
txts_ch = []
txt_word = jieba.lcut_for_search(txts)
stop_word=['啊','吧','呀','呢','的','得','她','它','他']
for i in range(0,len(txt_word)):
if is_Chinese(txt_word[i]):
if txts[i] in stop_word:
continue
elif txt_word[i]:
txts_ch += txt_word[i]
return txts_ch
def jaccard_similarity(txt1, txt2):
def add_space(txt):
return ' '.join(list(txt))
txt1, txt2 = add_space(txt1), add_space(txt2)
vectorizer = CountVectorizer(tokenizer=lambda txt: txt.split())
corpus = [txt1, txt2]
vectors = vectorizer.fit_transform(corpus).toarray()
numerator = np.sum(np.min(vectors, axis=0))
denominator = np.sum(np.max(vectors, axis=0))
return 1.0 * numerator / denominator
测试
代码示例是用给出的实例
class TEST_turntin(unittest.TestCase):
def orig_self(self):
print("start..")
print("测试文本为orig.txt")
encapsulation.solveok('orig.txt', 'orig.txt', 'ans.txt')
def orig_add(self):
print("测试文本为orig_0.8_add.txt")
encapsulation.solveok('orig.txt','orig_0.8_add.txt','ans.txt')
def orig_del(self):
print("测试文本为orig_0.8_del.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_del.txt', 'ans.txt')
def orig_dis_1(self):
print("测试文本为orig_0.8_dis_1.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_dis_1.txt', 'ans.txt')
def orig_dis_3(self):
print("测试文本为orig_0.8_dis_3.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_dis_3.txt', 'ans.txt')
def orig_dis_7(self):
print("测试文本为orig_0.8_dis_7.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_dis_7.txt', 'ans.txt')
def orig_dis_10(self):
print("测试文本为orig_0.8_dis_10.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_dis_10.txt', 'ans.txt')
def orig_dis_15(self):
print("测试文本为orig_0.8_dis_15.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_dis_15.txt', 'ans.txt')
def orig_mix(self):
print("测试文本为orig_0.8_mix.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_mix.txt', 'ans.txt')
def orig_rep(self):
print("测试文本为orig_0.8_rep.txt")
encapsulation.solveok('orig.txt', 'orig_0.8_rep.txt', 'ans.txt')
print("Finally!!!")
if __name__ == '__main__':
print("let's beginning")
suite = unittest.TestSuite()
suite.addTest(TEST_turntin('orig_self'))
suite.addTest(TEST_turntin('orig_add'))
suite.addTest(TEST_turntin('orig_del'))
suite.addTest(TEST_turntin('orig_dis_1'))
suite.addTest(TEST_turntin('orig_dis_3'))
suite.addTest(TEST_turntin('orig_dis_7'))
suite.addTest(TEST_turntin('orig_dis_10'))
suite.addTest(TEST_turntin('orig_dis_15'))
suite.addTest(TEST_turntin('orig_mix'))
suite.addTest(TEST_turntin('orig_rep'))
runner = BeautifulReport(suite)
runner.report(
description='论文查重报告',
filename='finally.html',
log_path='C:/Users/guoch/Desktop/sim_0.8'
)
测试已给出的文本数据
结果

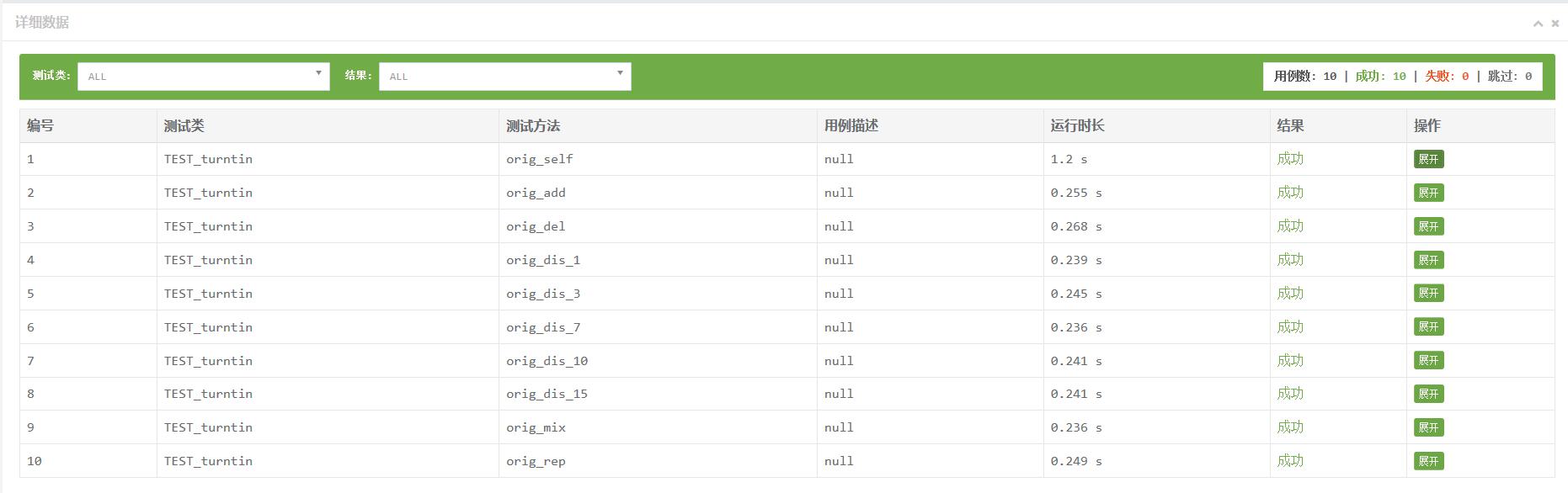
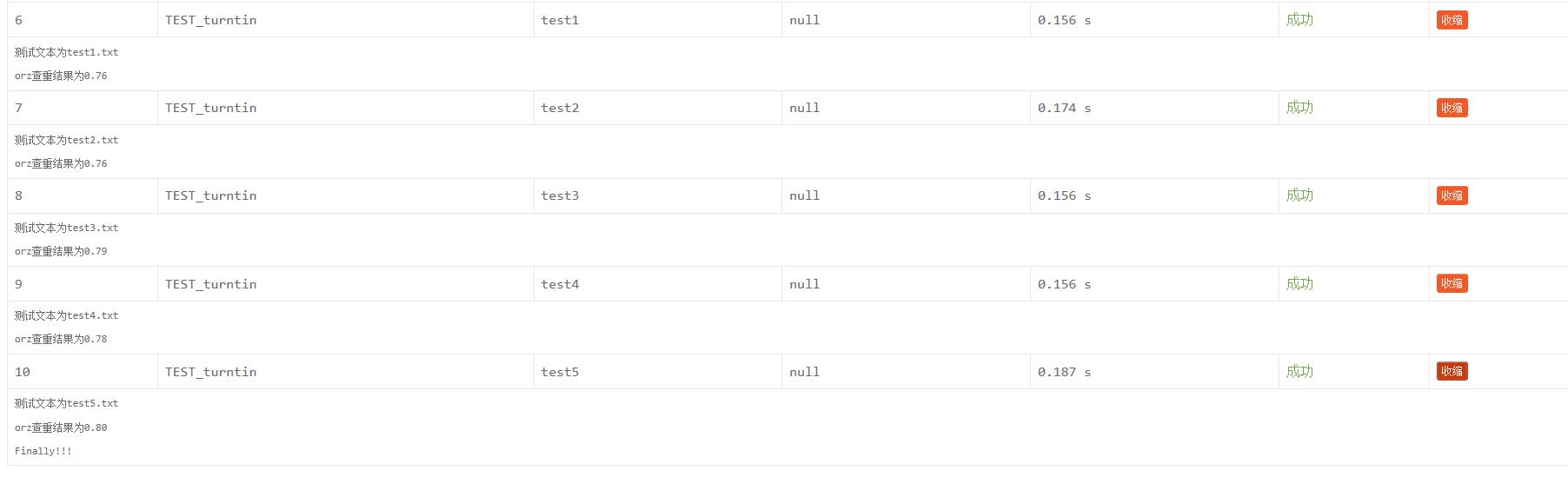
测试自己给出的文本数据
使用形策论文作为原文本改出的测试文本hhhhhh
计算得出测试文本的代码有借鉴大佬的嘿嘿,就直接放在仓库里啦(我太菜了)
结果
结果上因为改动在各个方面比较小,所以结果上差距不多,可以接受
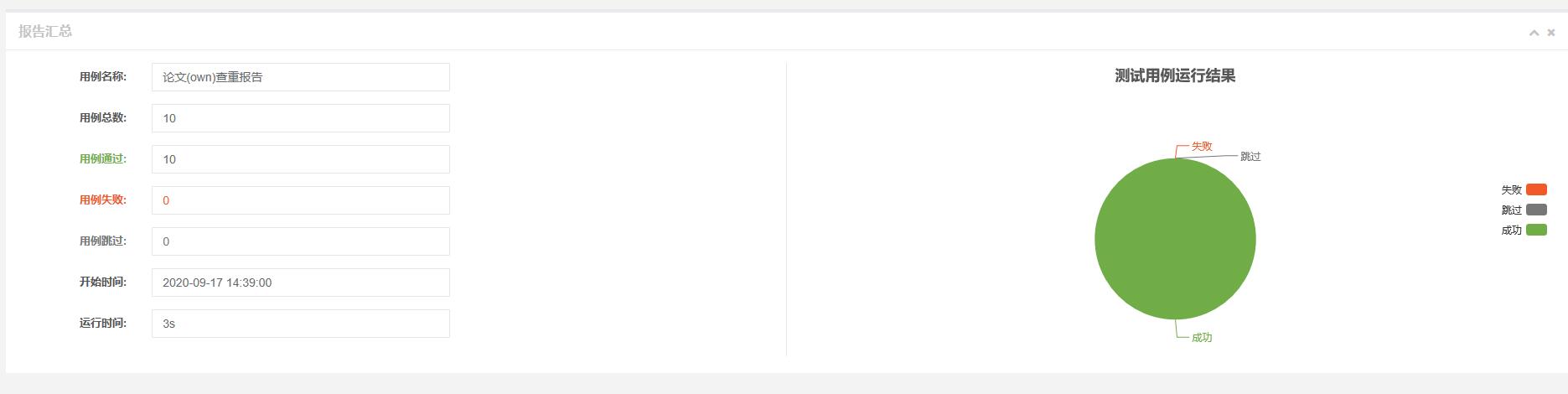

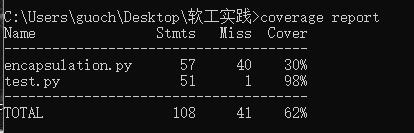
代码覆盖率
进行封装的代码覆盖率30%哈哈哈,感觉是因为把查重代码放进去了叭
进行单元测试的代码98%感觉就蛮有用的
计算模块异常
有五个方面:增加,删减,打乱,混合,代表
1.增加,在文本里加词,只需要设置每几个词后加几个字符,就可以满足了
2.删减,跟增加差不多,反向进行
3.打乱,这个打乱代码不太懂,参考了大佬
4.混合,这个是将增减混合
5.代表,增删加乱序(感觉前面三个就是基础的说)
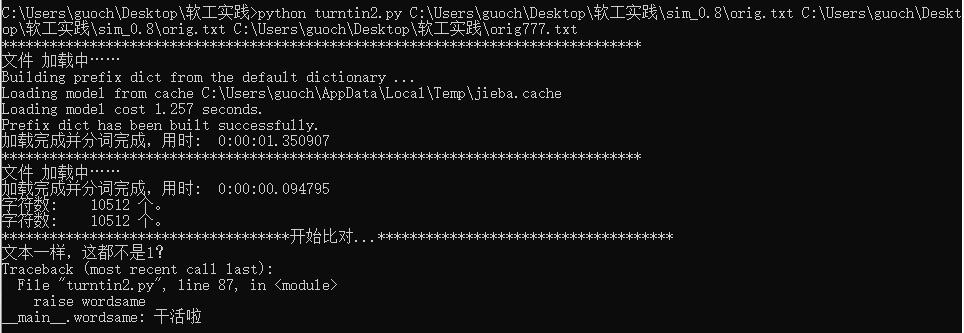
异常处理:
1.文本不一样,但是相似度为1
2.文本一样,但是相似度为1
class worddifferent(Exception):
def __init__(self):
print("文本不一样咋还为1呢?")
def __str__(self, *args):
return "GoGoGo"
class wordsame(Exception):
def __init__(self):
print("文本一样,这都不是1?")
def __str__(self, *args):
return "干活啦"
程序由原先修改如下
if num1 != num2:
flag=1
else:
flag=0
print('开始比对...'.center(80, '*'))
t1 = datetime.datetime.now()
result = compareParagraph(txt1_handle,txt2_handle)
if flag == 1 and result == 1.00:
raise worddifferent
elif flag == 0 and result != 1.00:
raise wordsame
else:
print(round(result,2))
result_final = str(round(result,2))
writeTXT(txt3,result_final)
t2 = datetime.datetime.now()
print('\n比对完成,总用时: ', t2 - t1)
结果:

PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 180 | 173 |
| · Estimate | · 估计这个任务需要多少时间 | 180 | 150 |
| Development | 开发 | 2000 | 2150 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 362 |
| · Design Spec | · 生成设计文档 | 60 | 44 |
| · Design Review | · 设计复审 | 120 | 110 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 44 |
| · Design | · 具体设计 | 120 | 131 |
| · Coding | · 具体编码 | 1500 | 1321 |
| · Code Review | · 代码复审 | 300 | 229 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 401 |
| Reporting | 报告 | 180 | 217 |
| · Test Repor | · 测试报告 | 90 | 153 |
| · Size Measurement | · 计算工作量 | 30 | 61 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 44 |
| · 合计 | 5460 | 5590 |
总结
啊,这,就感觉自己是个小白,但是在做作业的过程中收获到很多东西,不管是花了很多尝试了一个到最后也没运行出来的代码,还是不停的百度,做完作业都感觉,好像自己也可以做到,就算自己的代码跟水平还是很差的,但是还是超有有成就感的,不过也是秃头的hhhh



 浙公网安备 33010602011771号
浙公网安备 33010602011771号