
OO-2022-Unit4-BeihangCSE
单元设计架构
这个单元主要是要实现一个UML结构,并且按照指导书的要求实现一些查找和检查指令。
在第一次作业中,只涉及到UmlClass和UmlInterface以及的UmlOperation的查询。在理清其继承关系、所属关系后,完成这样的建模是很快的。
这里大部分的指令的具体需求还是放在具体的类中实现的,MyImplementation做的只是调用相应的接口。实现了较好的接口分离。代码复杂度也控制的较好。所有的类都只和其直接朋友交流,比如MyOperation和UmlAttribute
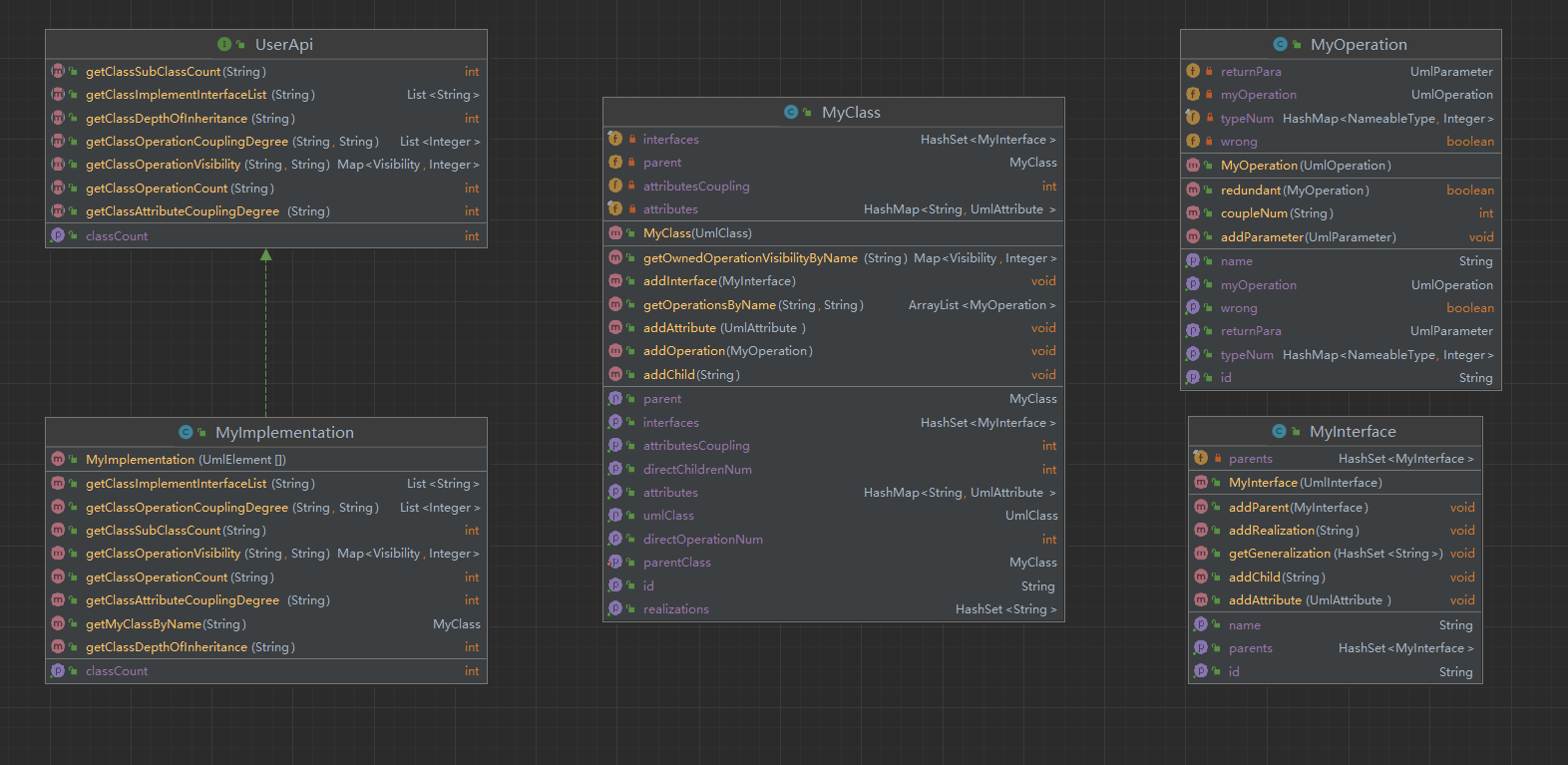
第二次作业新增加了UmlStateMachine和UmlInteraction,但仍然是延续第一次作业的思路:根据指令需求从输入信息中提取有用的部分来建模一个Uml模型,在此基础上进行查询。
比如在UmlInteraction中,我们并不需要从UmlMessage中获取额外的信息,只需要能读到其类型即可,因此不需要对它做额外的建模,使用package即可。但对于UmlLifeline,我们就需要知道它保存了哪些UmlMessage(事实上我们只关心LostMessage、FoundMessage和CreateMessage),只使用package中提供的UmlLifeline是不能够支持频繁的查询操作的。
在UmlStateMachine中也是类似的(由于StateMachine和Region的一一对应关系,我建模的对象是UmlRegion)。这里有一点需要注意的是,纵观全局,对于State的需求其实只是它有哪些迁出状态(判定关键状态即dfs、判断直接可达),添加迁入transition是多余的。
本次作业中稍显的复杂的即使判断关键状态。我的策略是,当模型建构完毕后,自动调用dfs算法对每个Region判断其可达性并保存结果。之后当需要判断关键状态时,首先看Region的可达性,再把这个状态加入visited[](使得dfs过程中不会再访问这个State,变项地删除了它)后进行dfs判断可达性。
总而言之,我仍然是将大部分指令的具体实现放在了我建模的对象类中,MyImplementation显得非常简单。
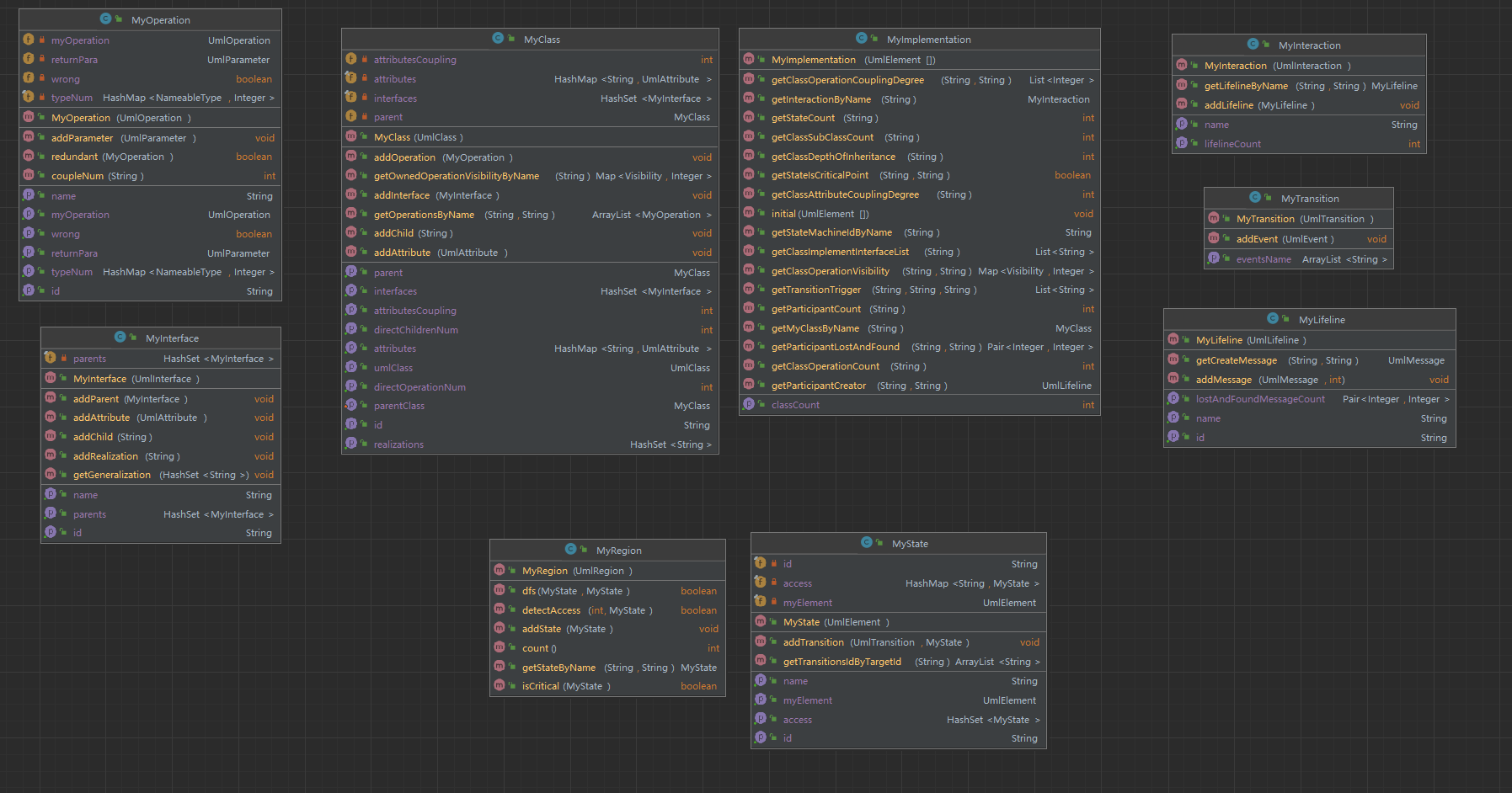
第三次作业,需要我们对模型的合法性做出检查。其中最麻烦的地方在于判断循环继承和重复继承。
从算法上将,我还是选择了dfs遍历的方式(因为UmlClass只能单继承,可与直接循环不需要递归);从实现的角度,我将其放在了MyImplementation中,现在想起来非常后悔。因为这非常严重地影响了我的CheckStyle,一直和500行的要求斗争。最重要的是,这也不符合OO设计模式原则的要求。理想的状态应该是MyImplementation作为一个类似适配器的角色,一方面提供向用户调用的接口,一方面使用其他类已实现方法来实现这些借口,而不是要在自己的代码中实现某一个类自己就可以完成的功能、算法。
设计思维与OO方法
个人认为在历次作业中,从类的设计上来说,最需要面向对象、OO思维的是第一单元第二次作业。犹记得第一单元每次开始之前漫长的思考过程,现在还记忆犹新。后续的作业,更多地是要考虑如何合理地设计接口,减小方法的复杂度,再功利地说是如何避免CheckStyle Warning。
先说第一单元。表达式、因子、三角函数等嵌套的形式,使得我们需要设计比较复杂的继承、接口实现机制才能既模拟出和形式化定义一一对应的对象、又方便类、接口的管理调用。好在有研讨课的讨论,让我和同学们分享了我周四时的一些思路。在讨论中,我的有些思路和大家是一致的,有些思路相较之下又显得太复杂或太简单。吸取了许多同学的经验,我最后实现了一个基于toString()来保存、比较因子的化简方式。其实这个方法显得有些取巧,但也可以说是充分利用了java提供的工具: )。
第二单元,主要考验的就是接口设计和对设计模式的运用了。很显然地,在多线程模式上,大家普遍的选择了生产者消费者。但在第三次作业中,由于要实现流水线的请求处理,很自然的就出现了责任链模式和观察者模式供我们选择。从电梯的创建的角度,还有工厂模式和单例模式(单例模式要注意多线程问题)。总体而言,有一个类功能单一化、接口隔离的架构,能很快帮我们理清思路,专注于我们要做的事情(比如在电梯类中实现一个Look算法、比如让调度器实现请求拆分等等)
第三单元,由于JML规范已经为我们定义了许多接口。大部分非Network的接口的实现都比较简单,大部分Network的接口都可以通过调用其聚合的接口很方便的实现。个别涉及到图算法的操作,需要单独设计算法和类(比如Link)来处理。这个单元更重要的是,对数据的管理方式。JML定义中只有“[]”,这并不意味我们只能使用数组。在频繁插入删除、频繁查询的应用场景下,使用HashMap显然是更优的选择。不过仍然需要注意到的是,在JML的定义中,有些“数组”需要按顺序插入、按顺序输出,这种情况由于HashMap是无序的(至少一般和插入顺序无关),这时候使用ArrayList才能保证不出错。
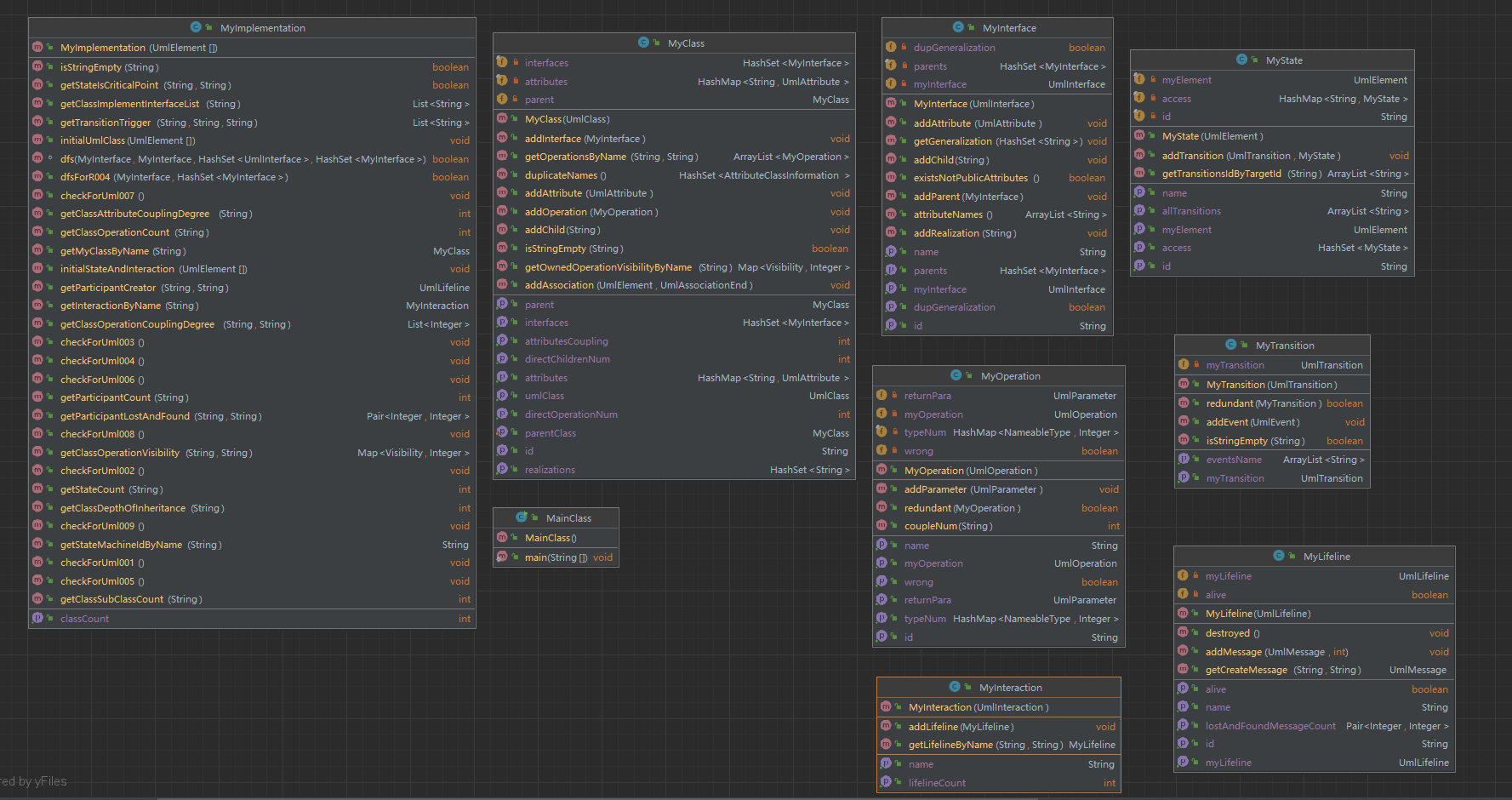
第四单元,MyImplementation作为一个庞大的、要提供诸多上层调用的接口的类,必然意味着它不能有太多具体的实现。我们当然可以遍历UmlAttribute来获得其所属关系,但者未免太过复杂。建立一套UmlClass->UmlOperation->UmlAttribute的树状模型来快速访问显然是更优解。从架构上说,将功能的具体实现(或者说算法上的实现)放在另外一个具体的类中,能有效的降低提供接口的这个“适配器”类的复杂度。MyImplementation要做的就是调用工具类提供的方法快速实现需求就好。
测试
在作业的开始,我其实并没有做太多的测试。随着后续作业的展开,中测的强度似乎越来越弱,尤其是第三单元的中测,于是我才开始写数据生成与朋友们对拍。
在第一单元,我主要测试了许多组边界数据,并通过自己计算的方式来验证正确性。
- 在第一次作业中,主要需要考虑的边界数据是±1、0、±x等等(常常是因为+1优化出现了奇怪的输出)。
- 第二次作业则是需要测试sin的正确合并和化简,例如sin(0)\sin(x**2)\ -sin(-4)等等。另外值得注意的是函数替换中,需要对xy的位置进行充分测试,例如f(x,y) = x**2+2*y,f(x,2x)\f(y,x) = x**2+2*y,f(x,2x)等等
- 第三次作业时,许多同学都应该在之前完成了括号嵌套、函数替换等功能。不需要做太多的测试。
当然,在这之前我还做了非常多小测试,比如深浅克隆相关、我自己实现的函数替换功能等等。这些测试是放在别的类中实现的,主要是为了学习java的机制,构造了一些简单的数据,在此就不多言。
第二单元的测试包括性能和正确性两个方面。但因为我的策略基本上固定,所以性能测试其实没有太大的意义,我也没办法继续优化。在正确性测试方面,
这个单元可以不和同学对拍,只需要对输入输出进行判定即可。保存每个输入的乘客,初始状态设置为等待,然后开始判定其状态。
- 乘客的状态只能是“等待<->乘坐电梯”,即不能连续进入两次电梯。
- 乘客的出入电梯前必须有“OPEN”,并且注意检查楼层楼座位置一致
- 乘客最终的状态需要为等待,并且位置信息需要和请求的目的地一致
- 电梯的状态包括“OPEN-CLOSE—MOVING”三者循环,不能出现顺序问题
- 电梯内的乘客不能超过容量
- 电梯的移动距离需要与间隔时间和速度相一致
- 电梯最终需要停下来,过长时间的运行应该认为是出现了异常
第三单元测试的主要压力点在于性能测试。hw9中涉及到isCircle和queryBlockSum,hw10中涉及到query_least_connection以及query_group_value_sum,最后一次作业则是sendIndirectmessage。这些内容几乎都是图相关的。由于指导书对ic、qbs、qlc、sim做了数据限制,所以O(n2)的复杂度都是可以接受的。重要的是query_group_value_sum这个完全不受限制的指令,如果单纯的查询,毫无疑问的是O(n2)的复杂度。为了化简它,将group_value的计算分散到别的指令中,对其进行动态维护。
从性能测试的角度,需要构造一些极端数据,比如只由ap、atg、dfg和qgvs组成的数据。从正确性测试的角度,需要充分考虑到数据的覆盖性。一方面是指令要测全,一方面是覆盖异常行为。这里分享测试机的部分代码。利用随机数+switch完成指令选择,利用随机数+求余数完成id的异常的覆盖。
while (totalnum--) {
//op = rand() % 6; // only person & relation
//op = rand() % 12; // group
op = rand() % 16; // message
id1 = rand() % (max_person_id * 10 / 9);
id2 = rand() % (max_person_id * 10 / 9);
idg = rand() % (max_group_id * 10 / 9);
idm = rand() % (max_message_id * 10 / 9);
if (totalnum > 10000 - 100) { // 一定要先加人和group,让max_id加上去
op = 0;
}
//printf("totalnum = %d , op = %d\n", totalnum, op);
switch (op) {
//PERSON & RELATION
case 0:
max_person_id++;
str = "name_" + to_string(max_person_id);
fprintf(out, "ap %d %s %d\n", max_person_id, str.c_str(), rand() % 201 );
//printf("ap %d %s %d\n", max_person_id, str.c_str(), rand() % 201 );
break;
case 1:
value = rand() % 1001;
fprintf(out, "ar %d %d %d\n", id1, id2, value);
break;
case 2:
fprintf(out, "qci %d %d\n", id1, id2);
break;
...
}
第四单元的测试主要是正确性相关,通过和同学对拍验证正确性。数据构造仍然需要保证其覆盖性。这个单元的测试我并没有做很多,尤其是第三次作业,简单对拍之后就提交了。后面才发现自己对R2的理解还有问题,但完全没测出来,非常后悔。
测试中遇到的问题如下:
- 对Parameter WrongType的判定错误
- 对继承情况的判定出错
- dfs时忘记标记visited数组
- Class单继承循环判断时忘记标记visted导致死循环
- R2的理解错误,输出AssociationEnd时认为输出它的parentClass
总而言之,整个课程中的测试,主要是围绕正确性和性能。对我而言又主要是正确性测试。测试方法主要是和同学们对拍,或者利用指导书的规则对输出进行检查。构造数据主要是用的边界数据构造和随机全覆盖测试。
课程收获
非常感谢OO课程,让我在这么多次的大作业中,第一次感受到了一些编程的乐趣,让我认识到编程不只是苦思算法,还有精妙的架构设计。
在课程中,我也自主的去了解设计模式及其原则,并且越来越熟练且自觉的运用这些原则。比如最常用的接口隔离、依赖倒置等等。在设计时,一方面是考虑到怎么管理数据才能做到较好的性能和简单的读写操作,另一方面我也越来越期望能使用尽可能简单的接口来实现某一个单一的功能,而不是期望只用几个复杂的方法就实现类的全部功能。
在测试方面,一开始是自己手搓数据,到后面尝试自己写数据构造并且和同学们对拍。还记得二单元的时候,同学发给我了一个自动化测评机,但我运行起来总是报错。于是我非常认真地阅读了他的代码,进行了调试。这是我第一次接触到自动测评机,让我对其有了比较深入的了解。不过那已经是最后一次作业了。从三单元开始,我开始尝试自己写测评机。结果在第一次作业的时候就出了大bug,这才认识到三单元所需要的数据覆盖性不是依靠二单元那样的随机数据生成就能完成的,于是又写了极端数据的生成器spe.cpp。在后续的两次作业中体验都非常好。
课程建议
我认为当前的OO课程已经做的非常好了。每次作业、指导书、强测中测都应该是助教和老师们齐心努力的结果。不过从学生的角度出发,我认为还有几点可以优化一下:
- 合理设置中测强度。中测作为能否进强测的标准之一,我理解助教们是希望给大家进入强测的机会,但个别作业的中测实在是太弱了。有一次我作业,我的异常输出出现了拼写错误,但中测也没测出来,强测寄的一塌糊涂……希望之后的中测能又基本的覆盖性,至少要出现所有指令和所有可能的输出吧。
- 研讨课的时间和内容还需要再优化。研讨课一开始是我很喜欢的部分,在第一单元中,在和同学们的讨论中我收获了许多,比如深浅克隆相关知识、架构设计的方案等等。不过到后续的研讨课中,一方面是似乎时间有些错开,研讨课进行的时候针对作业似乎已经没有什么可讨论的了,另一方面是确实作业中供自己发挥的余地不多,大家的架构普遍地趋同。这个时候设置别的讨论内容我感觉大家的参与热情度也不高。有一两次研讨课,讨论主题和代码都是前一晚上才发出来,非常仓促。
- 实验课的参与感不强。前期的实验课非常简单,半小时走人,后期的实验课(尤其是JML)变成了大阅读题,基本是踩着点交的(当然这个提交的冷却也稍显不合理,既然只做编译测试的话,为什么不再减少冷却甚至取消冷却呢?)个人认为可以把单元的training部分挪一些到实验中来。
