zookeeper在Hadoop集群中的作用(一)
一、什么是Zookeeper
ZooKeeper 顾名思义 动物园管理员,他是拿来管大象(Hadoop) 、 蜜蜂(Hive) 、 小猪(Pig) 的管理员, Apache Hbase和 Apache Solr 以及LinkedIn sensei 等项目中都采用到了 Zookeeper。ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,ZooKeeper是以Fast Paxos算法为基础,实现同步服务,配置维护和命名服务等分布式应用。
HDFS HA原理
单NameNode的缺陷存在单点故障的问题,如果NameNode不可用,则会导致整个HDFS文件系统不可用。所以需要设计高可用的HDFS(Hadoop HA)来解决NameNode单点故障的问题。解决的方法是在HDFS集群中设置多个NameNode节点。但是一旦引入多个NameNode,就有一些问题需要解决。
· HDFS HA需要保证的四个问题:
- 保证NameNode内存中元数据数据一致,并保证编辑日志文件的安全性。
- 多个NameNode如何协作
- 客户端如何能正确地访问到可用的那个NameNode。
- 怎么保证任意时刻只能有一个NameNode处于对外服务状态。
· 解决方法 - 对于保证NameNode元数据的一致性和编辑日志的安全性,采用Zookeeper来存储编辑日志文件。
-
两个NameNode一个是Active状态的,一个是Standby状态的,一个时间点只能有一个Active状态的
NameNode提供服务,两个NameNode上存储的元数据是实时同步的,当Active的NameNode出现问题时,通过Zookeeper实时切换到Standby的NameNode上,并将Standby改为Active状态。
o 客户端通过连接一个Zookeeper的代理来确定当时哪个NameNode处于服务状态
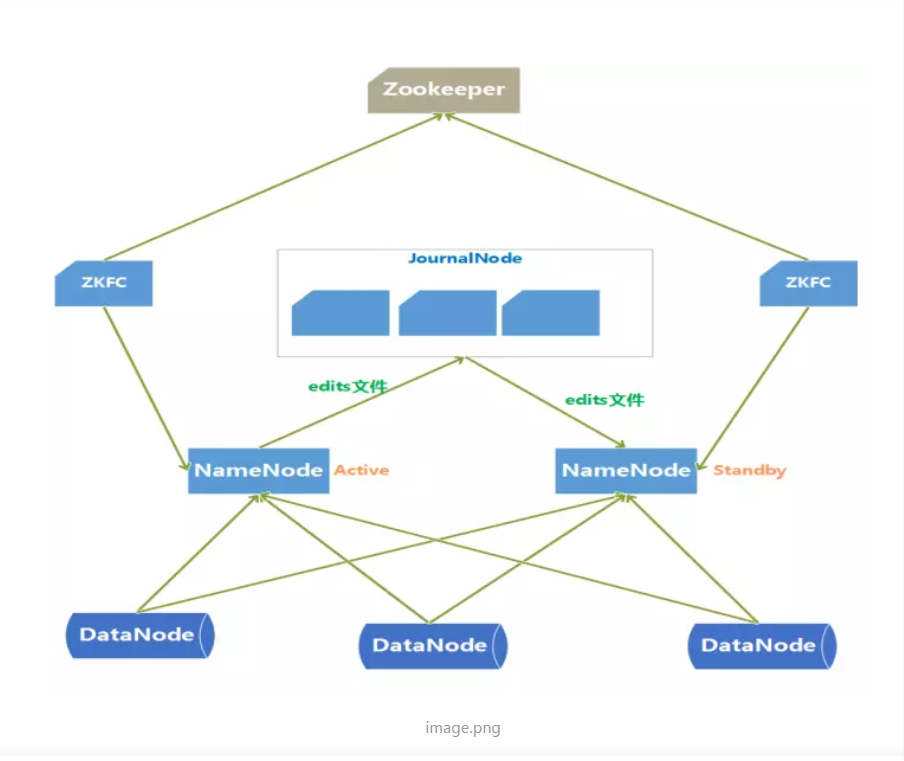
a· HDFS HA架构中有两台NameNode节点,一台是处于活动状态(Active)为客户端提供服务,另外一台处于热备份状态(Standby)。
b· 元数据文件有两个文件:fsimage和edits,备份元数据就是备份这两个文件。JournalNode用来实时从Active NameNode上拷贝edits文件,JournalNode有三台也是为了实现高可用。
c· Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode上拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的元数据信息和Active NameNode上的元数据信息一致,以实现热备份。
d· Zookeeper来保证在Active NameNode失效时及时将Standby NameNode修改为Active状态。
e· ZKFC(失效检测控制)是Hadoop里的一个Zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个Znode节点,节点里保存了NameNode状态信息。当NameNode失效后,ZKFC检测到报告给Zookeeper,Zookeeper把对应的Znode删除掉,Standby ZKFC发现没有Active状态的NameNode时,就会用shell命令将自己监控的NameNode改为Active状态,并修改Znode上的数据。
Znode是个临时的节点,临时节点特征是客户端的连接断了后就会把znode删除,所以当ZKFC失效时,也会导致切换NameNode。
f· DataNode会将心跳信息和Block汇报信息同时发给两台NameNode,DataNode只接受Active NameNode发来的文件读写操作指令。
b· 元数据文件有两个文件:fsimage和edits,备份元数据就是备份这两个文件。JournalNode用来实时从Active NameNode上拷贝edits文件,JournalNode有三台也是为了实现高可用。
c· Standby NameNode不对外提供元数据的访问,它从Active NameNode上拷贝fsimage文件,从JournalNode上拷贝edits文件,然后负责合并fsimage和edits文件,相当于SecondaryNameNode的作用。最终目的是保证Standby NameNode上的元数据信息和Active NameNode上的元数据信息一致,以实现热备份。
d· Zookeeper来保证在Active NameNode失效时及时将Standby NameNode修改为Active状态。
e· ZKFC(失效检测控制)是Hadoop里的一个Zookeeper客户端,在每一个NameNode节点上都启动一个ZKFC进程,来监控NameNode的状态,并把NameNode的状态信息汇报给Zookeeper集群,其实就是在Zookeeper上创建了一个Znode节点,节点里保存了NameNode状态信息。当NameNode失效后,ZKFC检测到报告给Zookeeper,Zookeeper把对应的Znode删除掉,Standby ZKFC发现没有Active状态的NameNode时,就会用shell命令将自己监控的NameNode改为Active状态,并修改Znode上的数据。
Znode是个临时的节点,临时节点特征是客户端的连接断了后就会把znode删除,所以当ZKFC失效时,也会导致切换NameNode。
f· DataNode会将心跳信息和Block汇报信息同时发给两台NameNode,DataNode只接受Active NameNode发来的文件读写操作指令。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号