
json模块、re模块
json模块
JSON全称是(JavaScript Object Notation)是一种轻量级的数据格式,一般用于前后台,数据的交互。
import json
print(json.__all__) 输出json的方法;常用的方法:dumps、loads、dump、load
序列化: 把一个Python对象转化成json字符串;
反序列化: 把json字符串转化成python
dumps :indent实现缩进, sort_keys 实现排序
下面简述json四种方法的案例:
先在python中建立一个字典:
user = {
'name':'dc',
'age':18,
'kl':3.6,
'tuple':('python','java'),
'li': [1,2,3],
'kong':None,
'True':True
}
dumps()方法:返回一个str,内容就是标准的JSON。
a = json.dumps(user) print(a) print(type(a)) print(user)
输出:

loads方法:反序列化:
b = json.loads(a) 将Json数据转化为python的数据类型字典;
打印:print(type(b)) print(b) print(type(b['kl']))
输出:

dump方法:针对文件
with open ('test.json','w+') as f:
json.dump(user, f, indent = 2, sort_keys = True, ensure_ascii=False)
运行之后会自动在当前文件夹下生成一个test.json的文件用于存储json数据!
indent表示缩进,sorts_keys表示排序
load方法:针对文件,将json数据文件转化为python数据
with open('test.json','r+', encoding="utf-8") as f:
data = json.load(f) #反序列化
运行之后会打开文件test.json将json数据反序列化,输出data: print(data):
![]()
re模块
正则表达式是计算机科学的一个概念,正则表通常被用来检索、替换那些符合某个模式(规则)的文本。也就是说使用正则表达式
可以在字符串中匹配出你需要的字符或者字符串,甚至可以替换你不需要的字符或者字符串。
元字符:类似于python中的关键字
. ^ $ * + ? {} [] \ | ()
符合说明:
. 点符号可以匹配除换行符之外所有的字符;换行符:‘\n’;
\d 反斜杠加d可以匹配数字;后边加数字{3}可以指定3个数字一起匹配;
\s 匹配空白符的;包括空格,制表符(Tab),换行符等;
\w 匹配字母或数字或下划线或汉字等;
\b 表示单词的边界; b = re.findall(r'read\b','read app')#加r是取消字符串的转义
\. 匹配点号本身,取消字符串的转义用r,取消正则的转义用 \ 来取消
\D 匹配数字以外的;
\D、\S、\W、\B 是与小写的相反的作用
^ 匹配开头的;
$ 匹配结尾的;
{} 指定匹配数字;{2}指定两个两个数字进行匹配;{2,5}匹配2到5个数字,先满足5,没有就看有没有4个...
{,5}匹配5个数字以下,遇到不是数字就相当于遇到0个数字;

* 匹配前面的子表达式零次或多次,等价于{0,},如 '\d*'可以匹配任意个数字
'.*'可以匹配任意多个非换行符,如果不加*,则会输出为一个一个的,有则满足最大的(贪婪模式)
+ 匹配前面的子表达式一次或多次,等价于{1,} ,如'\d+'匹配任意个数字,0个除外!
? 匹配前面的子表达式零次或一次,等价于{0,1}
#贪婪模式 满足要求,选最大的
tan = re.findall('a.*t','amount at about')
这里会把整个字符串都匹配到
#懒惰模式 满足要求就结束
lan = re.findall('a.*?t','amount at about')
这里只会匹配到amount;
子组匹配:
[ ] 字符类,将要匹配的一类字符集放在[]里面
如:
[ . ? * ( ) {} ] # 匹配里面的这些符号
[0-9] # 匹配0到9的数字相当于\d
[^\d] # 匹配除数字以外的字符,相当于\D
[a-z] # 匹配所有的小写字母
[^a-z] # 匹配非小写字母 ^相对于取反
| # 相当于或(or)分支条件;A | B # 匹配字母A或者B 与[AB]是一样的
分组:将要匹配的一类字符集放在()组成一个小组
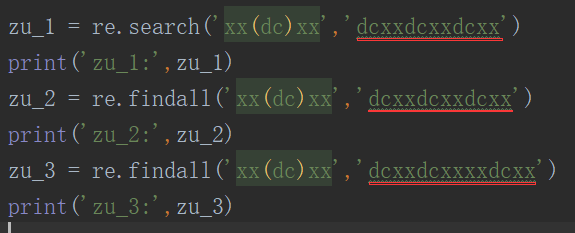

re模块常用方法
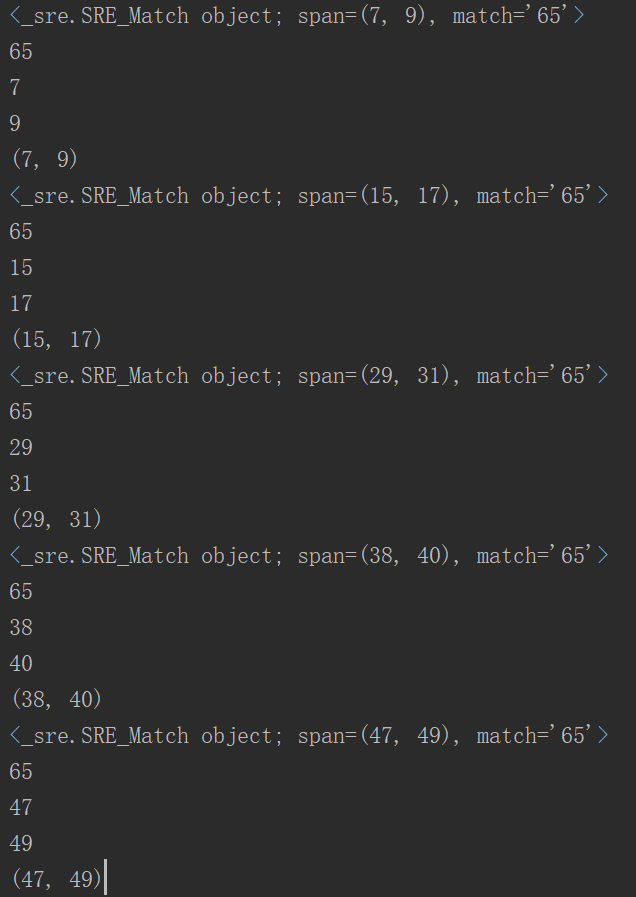
search() # 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象
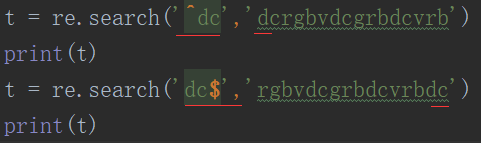
输出:span=(0,2)表示在0,1号索引位置,match为匹配的内容

finditer() # 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象
#获取 match对象 中的信息
group() # 返回匹配到的字符串
star() # 返回匹配的开始位置
end() # 返回匹配的结束位置
span() # 返回一个元组表示匹配位置(开始,结束)

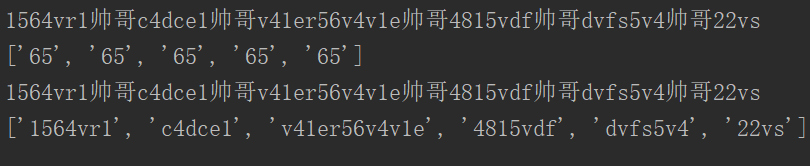
findall() # 搜索字符串,以列表类型返回全部能匹配的子串
sub() # 替换 类似于字符串中 replace() 方法
compile() # 编译正则表达式为模式对象
re.split() # 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型

输出结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号