
Kudu专注于大规模数据快速读写,同时进行快速分析的利器
注:由于文章篇幅有限,获取资料可直接扫二维码,更有深受好评的大数据实战精英+架构师好课等着你。
大数据技术交流QQ群:207540827

速点链接加入高手战队:http://www.dajiangtai.com/course/112.do

Kudu是什么
Kudu是一个分布式列式存储引擎/系统,由Cloudera开源后捐献给Apache基金会很快成为顶级项目。用于对大规模数据快速读写的同时进行快速分析。

官网:https://kudu.apache.org/
Kudu运行在一般的商用硬件上,支持水平扩展和高可用,集HDFS的顺序读和HBase的随机读于一身,同时具备高性能的随机写,以及很强大的可用性(单行事务,一致性协议),支持与Impala/spark计算引擎。

近年来Kudu的应用越来越广泛,在阿里、小米、网易等公司的大数据架构中,Kudu 都有着不可替代的地位。
Kudu出现的背景
Kudu给人的感觉是HDFS+HBase的杂合体,为什么会出现呢?
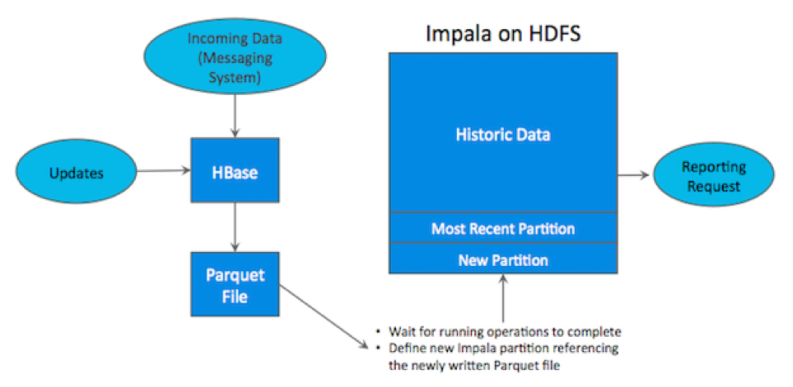
在Kudu出现之前,需要为不同形态的数据需要分别存储以适应不同场景:
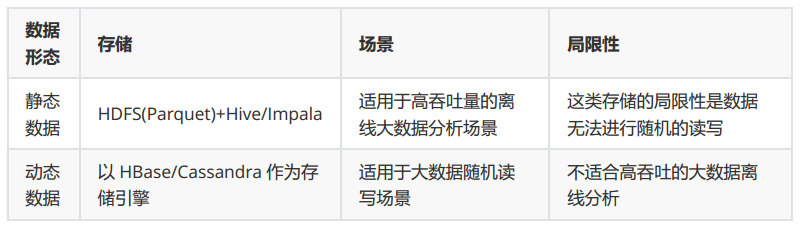
最终导致几个问题:
(1)数据过度冗余
数据需要存储多份以支撑多个应用,这样造成了存储等资源的浪费。
(2)架构复杂导致开发、运维、测试成本高
同时维护多套存储系统,架构复杂,开发、运维、测试成本相对较高。
(3)数据不一致容易误解
多套数据由于程序bug或者其他原因很容易出现数据不一致的情况,往往会造成业务方的误解。
为了解决上述问题业界做了很多尝试,例如HBase+Hive整合:
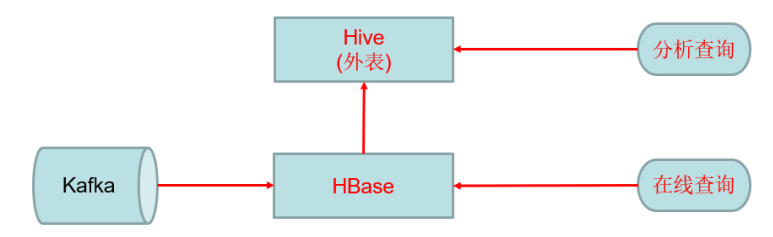
上述方案虽然在一定程度上起到了作用,但是依然改变不了HBase不适合高吞吐量离线大数据分析的事实。
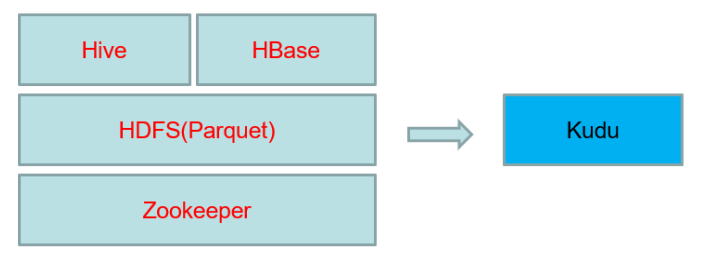
所以Kudu一出现定位就是Fast Analytics on Fast Data,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎:

从上图可以看出,Kudu 是一个折中的产品,它平衡了随机读写和批量分析的性能。从 KUDU 的诞生可以说明一个观点:底层的技术发展很多时候都是上层的业务推动的,脱离业务的技术很可能是空中楼阁。
当然Kudu身上还有很多概念或者标签,有分布式文件系统(好比HDFS),有一致性算法(好比Zookeeper),有Table(好比Hive Table),有Tablet(好比Hive Table Partition),有列式存储(好比Parquet),有顺序和随机读取(好比HBase),所以看起来kudu是一个轻量级的 HDFS +Zookeeper + Hive + Parquet + HBase,除此之外,kudu还有自己的特点,快速写入+读取,使得kudu+impala非常适合OLAP场景,尤其是Time-series场景。
由于文章篇幅有限,获取资料可直接扫二维码。
大数据技术交流QQ群:207540827


 浙公网安备 33010602011771号
浙公网安备 33010602011771号