

2023数据采集与融合技术实践作业一
作业①
(1)实验内容
o要求:用requests和BeautifulSoup库方法定向爬取给定网址( http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
o输出信息:
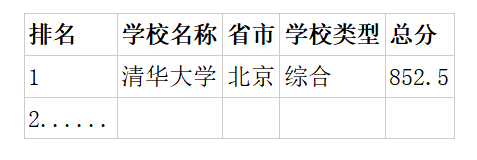
o网页内容爬取基本步骤:
①查看网页源代码,找到所需信息所在标签,如下所示,可以看到每个学校的信息都在一行中tr标签中,每个信息在td中。
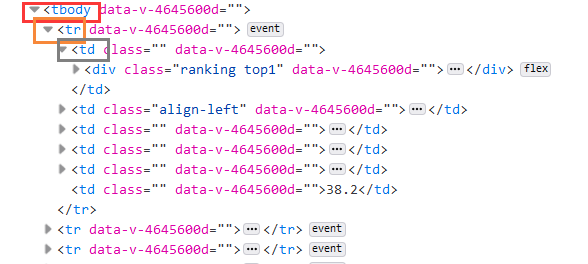
②在每个学校所在tr的标签中寻找所需信息所在td标签,如下所示:
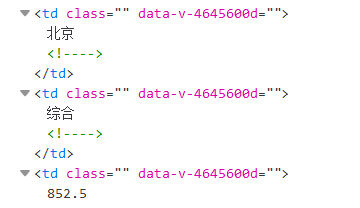
③通过设计代码抓取相关td标签内容,并打印可视化。
o具体代码实现:
code
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def get_html(url,headers):#获取HTML
try:
re=urllib.request.Request(url,headers=headers)
except Exception as err:
print("获取失败")
print(err)
return re
def get_data(req):#获取内容数据
l=[] #设置列表存放内容
data=urllib.request.urlopen(req)
data=data.read()
#解决不同编码问题
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
trs=soup.find('tbody')
for tr in trs:
tds=tr.find_all('td')#获取td标签里的内容
#这里通过tds标签内容直接获取到排名,学校名称,省份,学校类型,总分,并将其加入列表进行后续打印可视化
#strip() 忽略两边空格
l.append([tds[0].get_text().strip(),tds[1]('a')[0].get_text().strip(),
tds[2].get_text().strip(),tds[3].get_text().strip(),tds[4].get_text().strip()])
return l
def get_print(l,num):#打印所需内容
print("{0:^10}\t{1:<10}\t{2:<10}\t{3:<10}\t{4:<10}".format("排名", "学校名称", "省份", "学校类型", "总分"))
for i in range(num):
print("{0:^10}\t{1:<10}\t{2:<10}\t{3:<10}\t\t{4:<10}".format(l[i][0],l[i][1],l[i][2],l[i][3],l[i][4]))
num=eval(input("请输入学号后两位:")) #获取num位排名
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
req=get_html(url,headers)
lis=get_data(req)
get_print(lis,num)
o运行结果:

(2)心得体会
通过此次实验,熟悉了HTML总体架构,为后续深度网页内容抓取奠定了基础。掌握了urllib.request和BeautifulSoup库的基本操作。总体难度不算大,但是如果想要实现多页数据的爬取就有一定难度。
作业②
(1)实验内容
o要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
o输出信息:
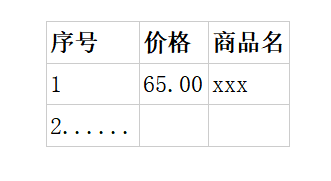
o不同网页内容爬取基本步骤相差无几,这里不再赘述,直接上代码!
o具体代码实现:
code
from bs4 import UnicodeDammit
import urllib.request
from bs4 import BeautifulSoup
import urllib.parse
#读取便签内价格及商品名称,并将其加入列表进行后续打印
def get_Html_data(url,headers,number):
try:
data_list = []
#http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=2
#http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=3
#翻页后只修改了一个参数page_index,于是要实现翻页只需要修改url中的page_index即可。
for i in range(number):
if i==0:
url=url
else:
url=url+'&page_index={}'.format(i+1)
headers=headers
re=urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(re)
data = data.read()
# 解决不同编码问题
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
li_list = soup.select("ul[class='bigimg cloth_shoplist'] li")
print(li_list)
for li in li_list:
name = li.a.attrs['title']
price = li.select('p[class="price"]')[0].text
data_list.append((name, price))
except Exception as err:
print("获取失败")
print(err)
return data_list
def get_print(data_list):#按顺序打印列表内容
print(len(data_list))
print("{0:^10}\t\t {1:<10}\t\t\t{2:<10}".format("序号", "价格","商品名"))
for i in range(len(data_list)):
print("{0:^10}\t\t{1:<10}\t\t{2:<10}".format(i+1,data_list[i][1],data_list[i][0]))
url='http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/117.0"}
number=eval(input("请输入爬取页面数:")) #获取爬取页数
lis=get_Html_data(url,headers,number)
get_print(lis)
o运行结果:

(2)心得体会
此次实验最大的问题是大型网页商城如淘宝,京东等存在反爬技术,爬取内容的时候返回的都是空列表,最后选择爬取当当网。由于网页源码特点,使用re库进行爬取反而使问题复杂化,这里仅使用bs4的css语法即可快速爬取所需内容。该实验还有一个难点在于翻页爬取内容。通过观察多个页面url,发现翻页后只修改了一个参数page_index,于是要实现翻页爬取只需要修改url中的page_index即可。
作业③
(1)实验内容
o要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm )或者自选网页的所有JPEG和JPG格式文件
o输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
o网页内容的下载基本步骤:
①查看网页源代码,找到所要下载文件所在标签,如下所示,可以看到图片所在标签及其格式。

②使用re库获得图片src属性内容。
③通过设计代码获取图片网址,下载并存放在特定文件夹。
o具体代码实现:
code
import urllib.request
import urllib.parse
import re
url="https://xcb.fzu.edu.cn/info/1071/4481.htm"
req=urllib.request.urlopen(url)
data=req.read()
mydata=data.decode("utf-8")
#下载图片函数 strtxt指示图像格式,网页内存在许多种不同格式图片,需要按需提取
def getPhoto(strtxt):
list_urls = re.findall(r'src=.+e=\.' + strtxt, mydata)
for i in range(len(list_urls)):
list_urls[i] = re.sub(r'src="', '', list_urls[i])
i = 0
for list_url in list_urls:
#指定图片下载存放文件夹
f = open('C:/Users/86180/Desktop/Python/pythonProject/project/' + str(i) + '.'+strtxt, 'wb+')
req = urllib.request.urlopen("https://xcb.fzu.edu.cn" + list_url)
buf = req.read()#获取文件数据
print("正在下载图片:" + list_urls[i])
f.write(buf)
f.close()
i += 1
getPhoto("jpg")
getPhoto("jpeg")
o运行结果:
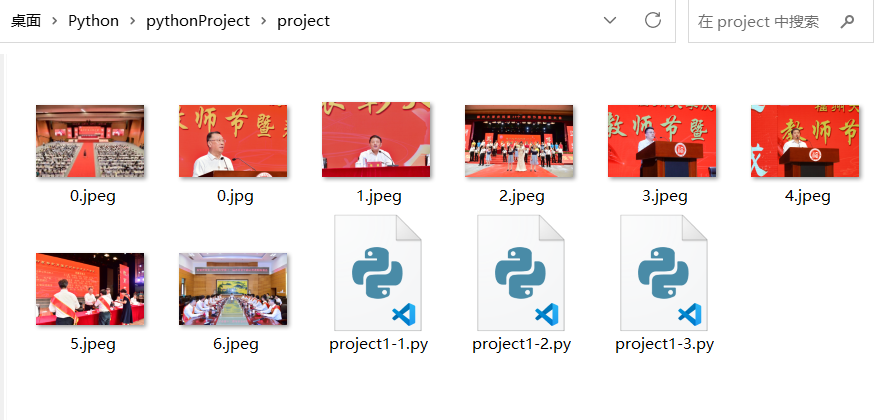
(2)心得体会
此次实验的难点在于如何使用re库获取图片网址。还有一处细节需要特别注意的是网站中的图片具有不同的格式,如jpg、jpeg、png等等,在设计代码爬取时需要特别注意,不然会导致出错,图片无法下载成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号