

python爬虫
import requests
from bs4 import BeautifulSoup
import time
import random
import jieba
from collections import Counter
import re
更完善的请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Referer': 'https://www.douban.com/',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
豆瓣书籍ID映射(直接使用ID避免搜索失败)
BOOK_IDS = {
'平凡的世界': '1084165',
'活着': '1082154',
'白夜行': '10554308'
}
def get_comments(book_name, sort='hot', page_limit=3):
"""获取豆瓣图书评论"""
book_id = BOOK_IDS.get(book_name)
if not book_id:
print(f"未找到书籍《{book_name}》的ID")
return []
base_url = f'https://book.douban.com/subject/{book_id}/comments'
comments = []
for page in range(page_limit):
try:
# 添加随机延迟
time.sleep(random.uniform(3, 6))
params = {
'sort': 'new_score' if sort == 'hot' else 'time',
'start': page * 20
}
response = requests.get(base_url, headers=headers, params=params, timeout=15)
response.encoding = 'utf-8'
# 检查是否被重定向到登录页
if 'accounts.douban.com' in response.url:
print("需要登录才能查看评论,请添加cookie")
return []
soup = BeautifulSoup(response.text, 'html.parser')
# 新版豆瓣评论选择器
comment_items = soup.select('div.comment-item')
if not comment_items:
comment_items = soup.select('li.comment-item') # 备用选择器
for item in comment_items:
try:
user = item.select_one('.comment-info a').get_text(strip=True)
rating = item.select_one('.rating')['title'] if item.select_one('.rating') else '无评分'
comment_time = item.select_one('.comment-time').get_text(strip=True)
content = item.select_one('.short').get_text(strip=True)
votes = item.select_one('.vote-count').get_text(strip=True) if item.select_one(
'.vote-count') else '0'
comments.append({
'用户名': user,
'评分': rating,
'评论时间': comment_time,
'短评内容': content,
'点赞数': int(votes)
})
except Exception as e:
continue
print(f"已获取《{book_name}》第{page + 1}页评论({sort})")
except Exception as e:
print(f"获取第{page + 1}页评论时出错: {str(e)}")
continue
return comments
def display_comments(comments, title):
"""显示评论信息"""
if not comments:
print(f"{title}: 无数据")
return
print(f"\n{title}:")
print("-" * 120)
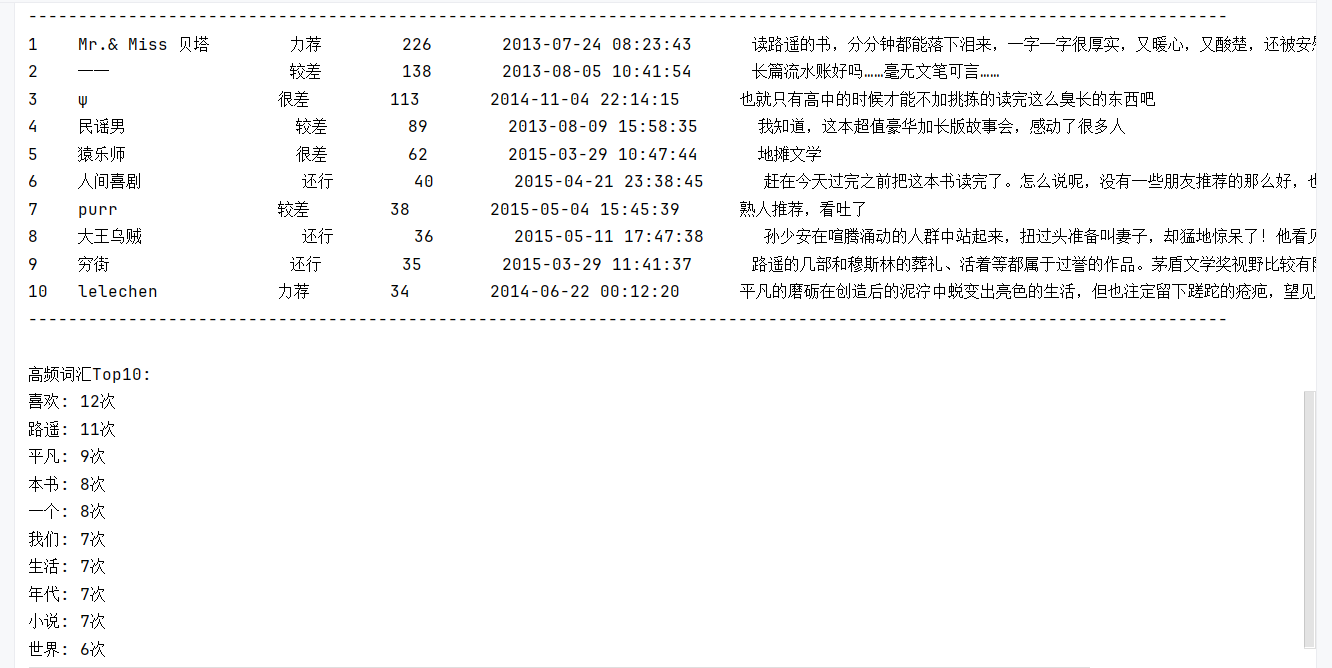
print(f"{'序号':<5}{'用户名':<20}{'评分':<10}{'点赞数':<10}{'评论时间':<25}{'短评内容':<50}")
print("-" * 120)
for i, comment in enumerate(comments[:10], 1):
print(f"{i:<5}{comment['用户名'][:18]:<20}{comment['评分']:<10}{comment['点赞数']:<10}"
f"{comment['评论时间'][:24]:<25}{comment['短评内容'][:48]:<50}")
print("-" * 120)
def analyze_comments(comments):
"""分析评论内容"""
if not comments:
return
# 合并所有评论内容
text = ' '.join([c['短评内容'] for c in comments])
# 使用jieba分词
words = jieba.lcut(text)
# 过滤停用词
stop_words = ['的', '了', '和', '是', '在', '我', '有', '也', '都', '这', '就', '要', '不', '人', '会']
words = [w for w in words if len(w) > 1 and w not in stop_words]
# 统计词频
word_counts = Counter(words).most_common(10)
print("\n高频词汇Top10:")
for word, count in word_counts:
print(f"{word}: {count}次")
def main():
print("请选择要分析的书籍:")
books = list(BOOK_IDS.keys())
for i, book in enumerate(books, 1):
print(f"{i}. {book}")
try:
choice = int(input("请输入选择(1-3): ")) - 1
book_name = books[choice]
except:
book_name = '平凡的世界'
# 获取热门评论
print(f"\n开始获取《{book_name}》热门评论...")
hot_comments = get_comments(book_name, 'hot')
display_comments(hot_comments, "热门评论Top10")
# 获取最新评论
print(f"\n开始获取《{book_name}》最新评论...")
new_comments = get_comments(book_name, 'new')
display_comments(new_comments, "最新评论Top10")
# 分析评论
all_comments = hot_comments + new_comments
if all_comments:
# 按点赞数排序
top_voted = sorted(all_comments, key=lambda x: x['点赞数'], reverse=True)[:10]
display_comments(top_voted, "点赞数Top10")
# 文本分析
analyze_comments(all_comments)
else:
print("\n未能获取任何评论数据,可能原因:")
print("1. 豆瓣反爬机制限制,请稍后再试")
print("2. 需要登录才能查看(请添加cookie)")
print("3. 网络连接问题")
if name == "main":
# 设置jieba分词
jieba.setLogLevel(jieba.logging.INFO)
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号