Lambda architecture and Kappa architecture
https://blog.csdn.net/hjw199089/article/details/84713095
Lambda architecture and kappa architecture.
From
- Mastering Azure Analytics by Zoiner Tejada
- Getting Started with Kudu
Lambda Architecture
Lambda architecture was originally proposed by the creator of Apache Storm, Nathan Marz. In his book, Big Data: Principles and Best Practices of Scalable Realtime Data Systems (Manning), he proposed a pipeline architecture that aims to reduce the com‐ plexity seen in real-time analytics pipelines by constraining any incremental compu‐ tation to only a small portion of this architecture.
In lambda architecture, there are two paths for data to flow in the pipeline
• A “hot” path where latency-sensitive data (e.g., the results need to be ready in
seconds or less) flows for rapid consumption by analytics clients
• A “cold” path where all data goes and is processed in batches that can
tolerate greater latencies (e.g., the results can take minutes or even
hours) until results are ready
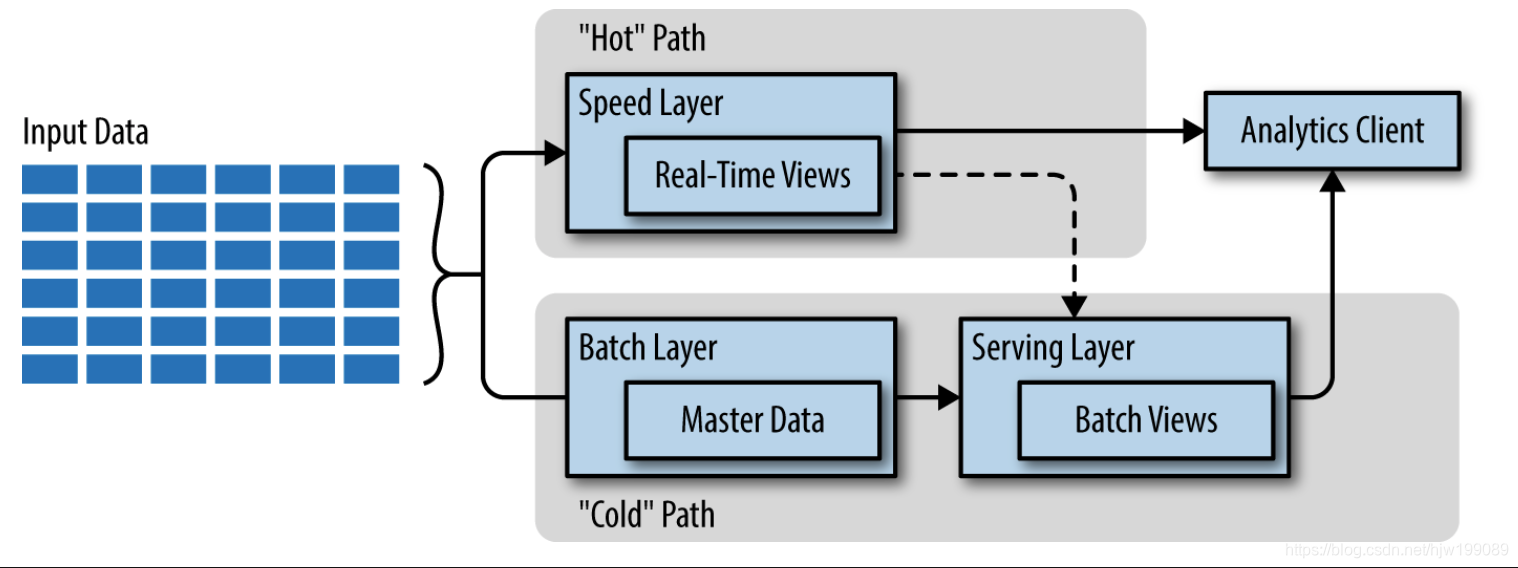
When data flows into the “cold” path, this data is immutable. Any
changes to the value of particular datum are reflected by a new,
timestamped datum being stored in the system alongside any previous
values. This approach enables the system to re- compute the then-current
value of a particular datum for any point in time across the history of
the data collected. Because the “cold” path can tolerate a greater
latency until the results are ready, the computation can afford to run
across large data sets,and the types of calculation performed can be
time-intensive. The objective of the “cold” path can be summarized as:
take the time you need, but make the results extremely accurate.
When data flows into the “hot” path, this data is mutable and can be updated in place. In addition, the hot path places a latency constraint on the data (as the results are typ‐ ically desired in near–real time). The impact of this latency constraint is that the types of calculations that can be performed are limited to those that can happen quickly enough. This might mean switching from an algorithm that provides perfect accuracy to one that provides an approximation. An example of this involves counting the number of distinct items in a data set (e.g., the number of visitors to your website): you can either count each individual datum (which can be very high latency if the volume is high) or you can approximate the count using algorithms like HyperLogLog. The objective of the hot path can be summarized as: trade off some amount of accuracy in the results in order to ensure that the data is ready as quickly as possible.
lambda architecture captures all data entering the pipeline into immutable storage, labeled “Master Data” in the diagram. is data is processed by the batch layer and output to a serving layer in the form of batch views. Latency-sensitive calcula‐ tions are applied on the input data by the speed layer and exposed as real-time views. Analytics clients can consume the data from either the speed layer views or the serving layer views depending on the time frame of the data required. In some implementations, the serving layer can host both the real-time views and the batch views.
The hot and cold paths ultimately converge at the analytics client application. The cli‐ ent must choose the path from which it acquires the result. It can choose to use the less accurate but most up-to-date result from the hot path, or it can use the less timely but more accurate result from the cold path. An important component of this deci‐ sion relates to the window of time for which only the hot path has a result, as the cold path has not yet computed the result. Looking at this another way, the hot path has results for only a small window of time, and its results will ultimately be updated by the more accurate cold path in time. This has the effect of minimizing the volume of data that components of the hot path have to deal with.
Kappa Architecture
Kappa architecture surfaced in response to a desire to simplify the
lambda architecture dramatically by making a single change: eliminate
the cold path and make all processing happen in a near–real-time
streaming mode (Figure 1-3). Recomputation on the data can still occur
when needed; it is in effect streamed through the kappa pipeline again.
The kappa architecture was proposed by Jay Kreps based on his expe‐
riences at LinkedIn, and particularly his frustrations in dealing with
the problem of “code sharing” in lambda architectures—that is, keeping
in sync the logic that does the computation in the hot path with the
logic that is doing the same calculation in the cold path.
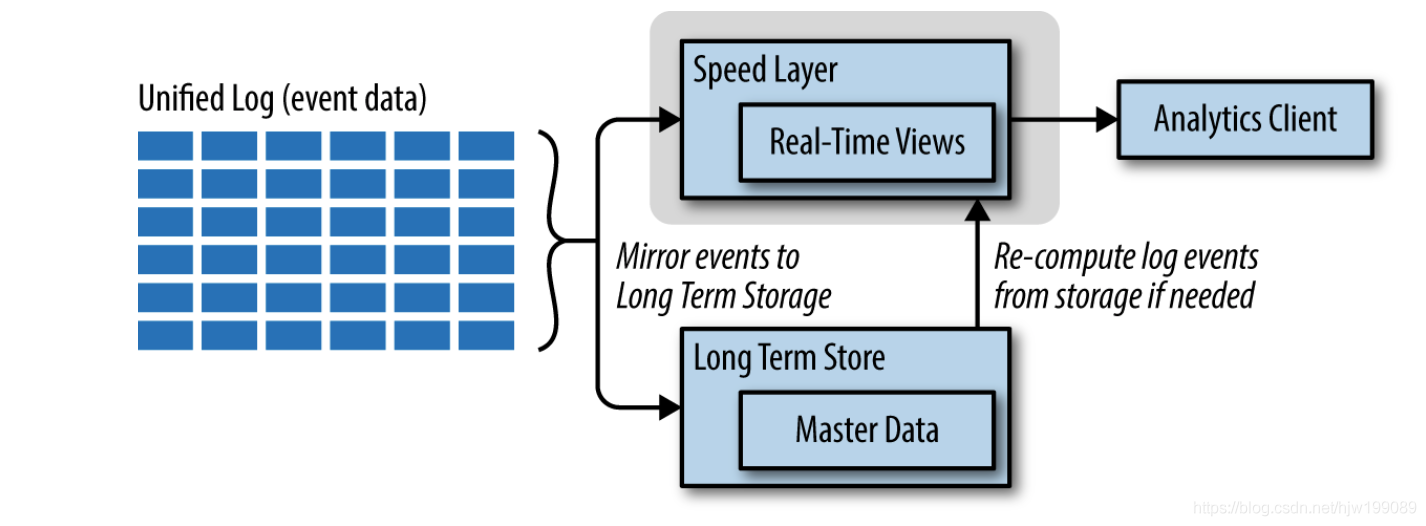
In the kappa architecture, analytics clients get their data only from
the speed layer, as all computation happens upon streaming data. Input
events can be mirrored to long-term storage to enable recomputation on
historical data should the need arise.
Kappa architecture centers on a unified log (think of it as a highly scalable queue), which ingests all data (which are considered events in this architecture). There is a single deployment of this log in the architecture, whereby each event datum collected is immutable, the events are ordered, and the current state of an event is changed only by a new event being appended.the unified log itself is designed to be distributed and fault tolerant, suitable to its place at that heart of the analytics topology. All processing of events is performed on the input streams and persisted as a real-time view (just as in the hot path of the lambda architecture). To support the human-fault-tolerant aspects, the data ingested from the unified log is typically persisted to a scalable, fault-tolerant persistent stor‐ age so that it can be recomputed even if the data has “aged out” of the unified log.
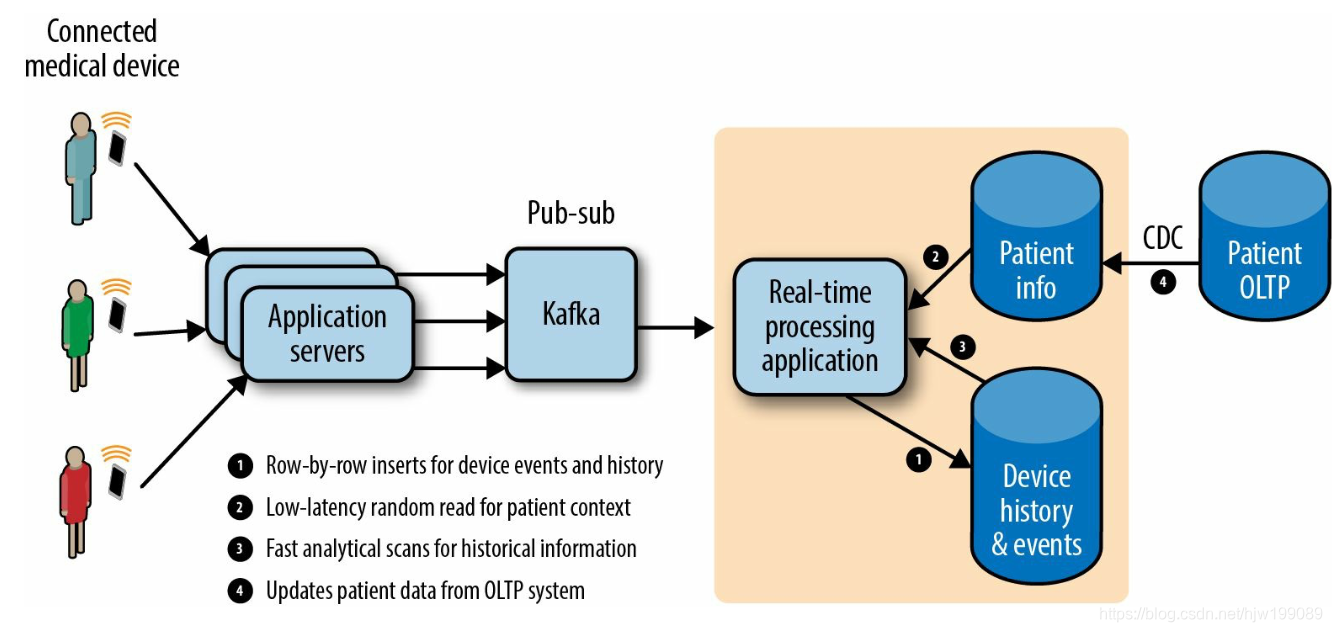
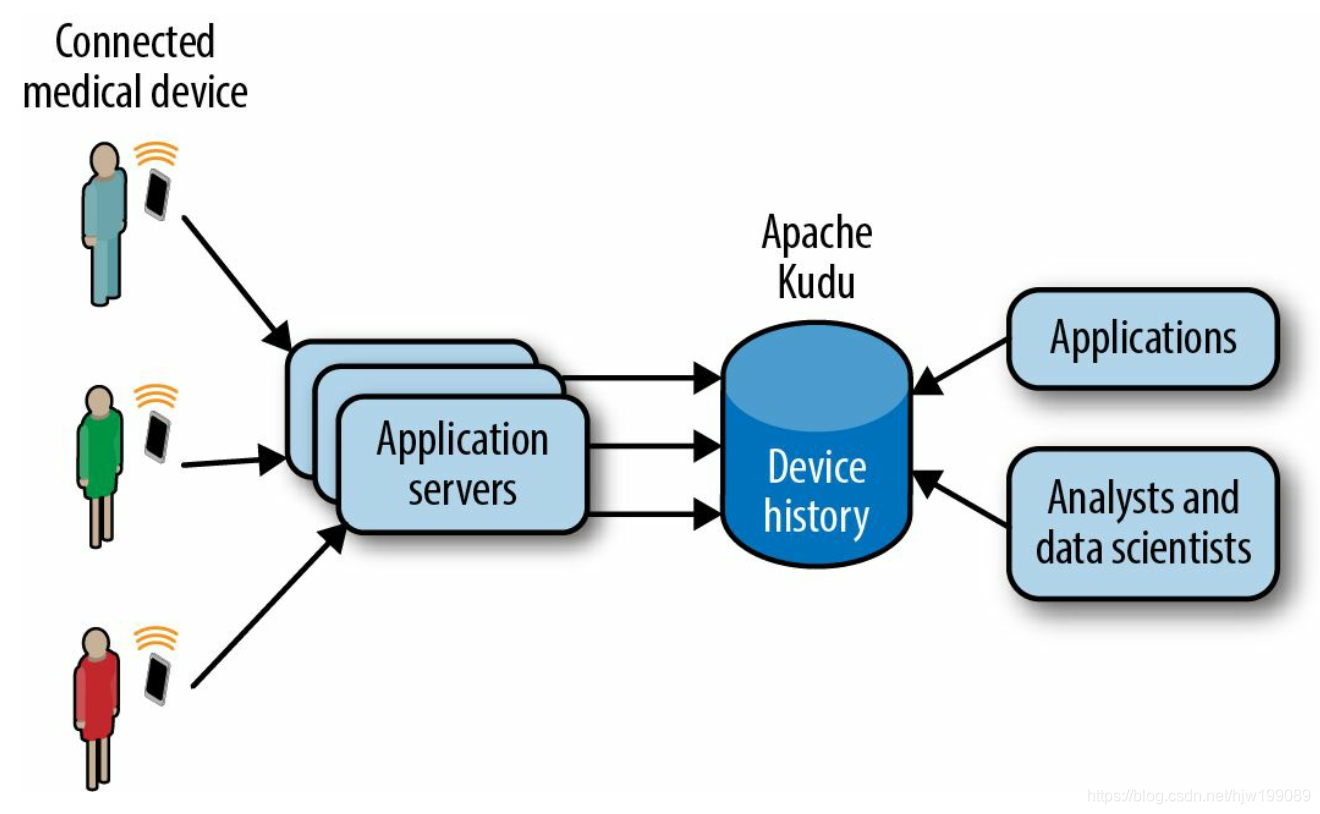
Moving Beyond Lambda Kappa Architectures with Apache Kudu
normal real-time data flow
solution with kudu


 浙公网安备 33010602011771号
浙公网安备 33010602011771号