
02简单分类器
最近邻算法
- 思想:
- 训练:只是记录下每个样本的位置和标签
- 预测:遍历每个点,看一下距离该点最近的样本点的标签是啥,那他就是哪一类
K近邻算法
- 思想:
- 训练:只是记录下每个样本的位置和标签
- 预测:遍历每个点,看一下距离该点最近的K个样本点的标签较多的是啥,那他就是哪一类,如果各类数量一样无法区分
- 实现
- 可以多使用模块化思想,数据输入、预处理和分类器模型分开来写,这样方便分类器的复用
- 向量化运算可以大大缩短循环所需的时间
- np.sum(a,axis=0) 假设a原本是2 × 3 × 4,对第一维求和后变为 3 × 4
- np.sort(), np.argmin(a)找到a数组中最小的数的索引
- numpy.array_split:将numpy数组分为n份,对于不整除的前面是 1 // n + 1 ..后面是1 // n
- np.concatenate((a,b,c),axis = 0) 将numpy数组a,b,c拼接
训练完计算准确率常用:
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy))
线性分类器
类似于模板匹配
CIFAR10 图片分类任务,是个很经典的数据集,图片大小是 32*32*3 , 类别是十类

输入 1*3072的数据 输出十个数(表示十各类的得分)
F(x,W) = Wx + b,就是要找一些数能够使得图片x所对应的标签得分更高
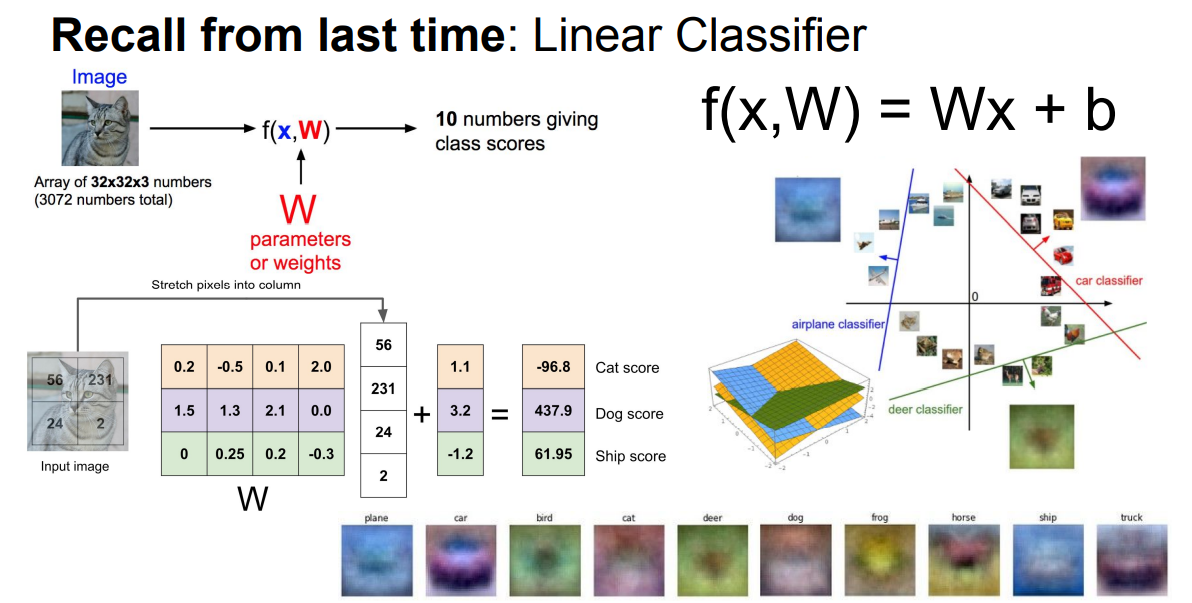
将W可视化后也可以看到大概W就是每类图片的一个公共的特征
现在只是有了一个打分,但是如何衡量这个打分的好坏,需要量化,我们把这个评价其打分好坏的量化函数叫做损失函数
其他
-
关于划分训练集和测试集
- 比较好的思路是划分训练集+验证集+测试集,然后用训练集训练,通过验证集调节超参,调到最好的超参后在测试集上测试准确率,这样的话在模型调节完之前一直接触不到测试集,测试集才能更加好的拟合数据集之外的真实数据
- 还有一个思路K折交叉验证,意思是划分为训练集 + 测试集,但是训练集划分为K份,用其中的K-1份进行训练,1份用作验证集调参。(一般用于数据较少的时候,少于一万条?)
-
关于调节超参
最好有一个随着超参的每一个值变化,模型准确率变化的图,这样能够更好的描述该参数最好的取值是多少
----------------------------------------------------------------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号