
第三单元博客总结
JML小结
JML作为一种行为接口的规范语言,可以用来指定Java模块的行为,其最基本的用途是作为Java的合同设计(DBC)语言。
使用 JML 来说明性地描述所希望的类和方法的行为,可以显著地改善整个开发过程。将建模表示法添加到 Java 代码中,其好处包括以下几点:
1.能更加精确地描述代码所完成的任务
2.能有效地发现和纠正错误
3.能减少随着应用程序的进展而引入错误的机会
4.能较早地发现客户没有正确使用类
5.能产生始终与应用程序代码保持同步的精确文档
JML是注重对象的,描述严格而精确,甚至略显繁琐。JML的要求就是让我们尽量理清我们的目标是什么,至于具体的实现过程,比如用什么容器、用什么算法是不关心的。
我们这一单元要掌握的重点也就是JML。
第一次作业
第一次作业里JML描述的方法整体上比较简单,只需按着JML给出的规格最直观的实现基本不会出现问题。对于Acquaintance等我都采用了map容器来存放,查找速度较快,其中people用了LinkedHashMap这样便于实现queryBlockSum方法。这次作业中最难的地方在于isCircle的判断,是查询两个人是否有直接或者间接的联系。对时间要求并不严格,于是我使用了遍历递归每个人的acquaintance的方式去查询,通过添加标志位判断某个人是否被查询过。
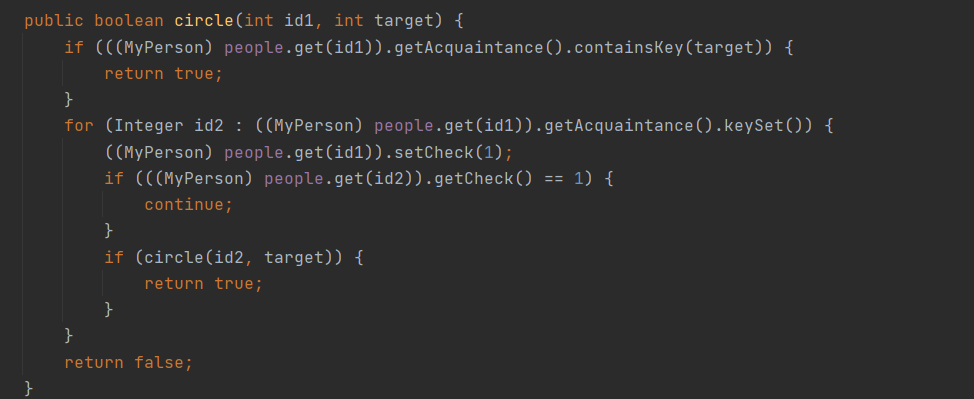
建立一个自己的circle判断方法。
第二次作业
第二次作业中在Network中添加的message和groups我只采用了Arraylist,基本上也是够用的,无需再用map加快查找速度。而且在遍历的过程中Map效率比List要低。
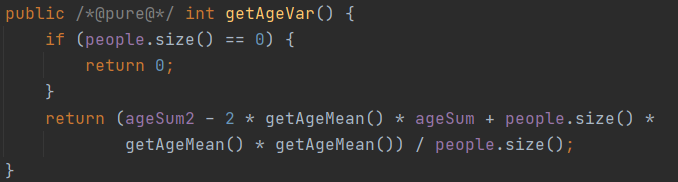
第二次作业对时间的要求增多了,在getAgeMean和getAgeVar方法中我一开始只是简单地采用了遍历,去求和,结果当然产生了TLE。于是我改变方法将求和放在add和del方法中,只要增加或减少人就立刻改变ageSum,对getAgeVar方法也将原有遍历求和合并变成一个表达式就能计算的结果。这样在这两个方法我就大幅度减少了时间。
第二次作业在公测中我的queryBlockSum再次超时,因为原有的circle方法采用遍历,速度很慢。为了从本质上改变查找速度,我采用了并查集,建立father节点的HashMap,存放每个节点的父节点,在查询时候只需查找最终父节点是否相同即可。并查集的这种方法插入块,查找略慢,但是相对于遍历递归是有质的飞跃。
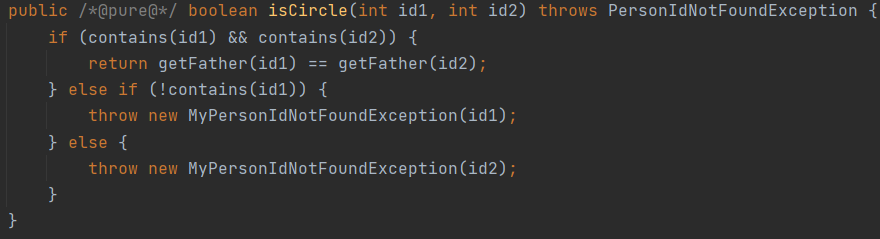

改为并查集以后不仅查找效率提升,而且代码量也大大减少。
第三次作业
第三次作业我意识到sendIndirectMessage如果采用传统遍历方式应该会超时,所以在我建立了heatToId的TreeMap对同样热度的表情id建立索引,一旦某个表情的热度发生变化就修改索引;建立idToMessage对同样表情的message建立索引。有了这两个Map就无需遍历表情或者message,用TreeMap有序排列能够快速找到coldEmoji,然后对着索引直接得到message的Id。同时采用堆优化的Dijkstra算法,来查找send的路径。
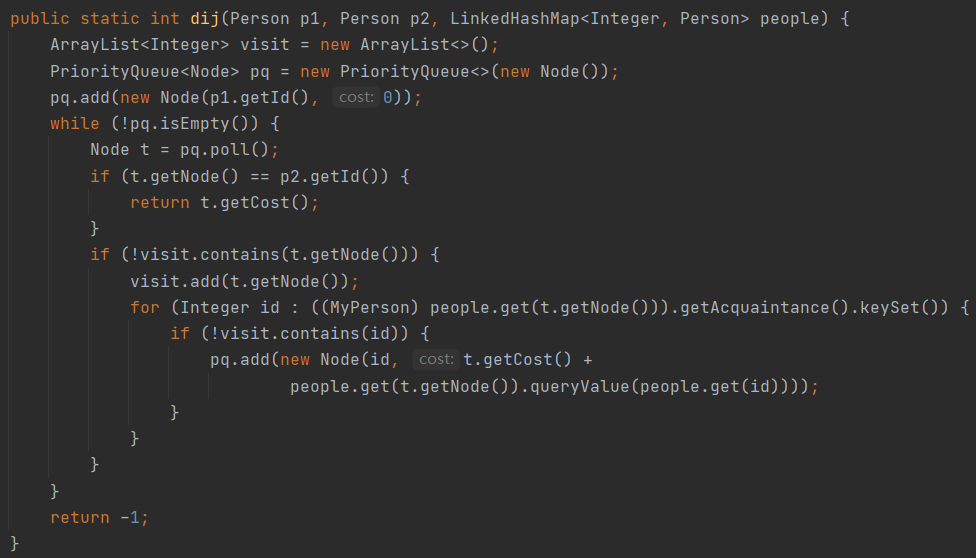
因为Java自带PriorityQueue,所以Dijkstra算法写起来非常简单。
在公测环节出现了大量指针指向错误的Bug,是因为在建立索引时出现失误,对于message的查找变成了对id的查找。修复该Bug后就通过了全部测试。
针对JML设计代码
1.针对JML写代码需要先看require,再看ensures,JML的结果是非常清晰的,实现时不能出现误差;
2.对于修改的变量要仔细看看含有\old的条件;
3.规格是一种说明,并不会限制代码实现,比如我为了实现AgeSum可以在add方法里面添加对Sum的计算,并没有限制说AgeSum只能在对应的方法里面完成计算;
4.针对方法慎重选择容器种类,建立恰当的映射关系可以让计算效率提高很多。
总结
在规格下对需求有了更好的把握,对边界情况实现更加清晰,因此代码实现起来结构也更好。
要考虑的是实现方式的复杂度而已。预先规定的接口和逻辑层次使得无需对全部代码重构,只需要微调。
