软工第一次编程作业
一、源码地址:
[https://github.com/Orange2107/031802107]:
二、代码原理
1.大致流程图

2.过程实现
2.1实现前的知识储备
-
使用了jieba库加上余弦算法对相似度的计算。通过余弦算法计算两个文本的余弦值,通俗的理解就是余弦值越大说明文本相似度越高。
详细链接 https://blog.csdn.net/zz_dd_yy/article/details/51926305> -
对于jieba库。只能说它对中文的处理很强大,没有它我这次作业大概率做不完。
详细链接https://www.cnblogs.com/liyanyinng/p/10958791.html -
One hot编码
对文章的分词进行编码,编码完会是一个矩阵,矩阵的行首是样本的特征(通过jieba特征值提取得到),矩阵的列首是样本分词后的一个个词。one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
-
sklearn
当我在使用cosine_similarity计算余弦值的时候,例如a=[[X,X,X,],[Y,Y,Y]]的计算,得出的结果会是一个二维数组,数组的第一行第一个数表示[x,x,x]自己的余弦值,第二行第一个数表示[x,x,x]和[y,y,y]的余弦值。
2.2计算模块接口的设计
-
测试的结果(把算法封装成一个函数,测试起来较为方便)
正在载入orig_add.txt
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\65910\AppData\Local\Temp\jieba.cache
Loading model cost 0.631 seconds.
Prefix dict has been built successfully.
相似度: 83.50%
————————————————————————
正在载入orig_del.txt
相似度: 73.00%
————————————————————————
正在载入orig_dis_1.txt
相似度: 88.50%
————————————————————————
正在载入orig_dis_10.txt
相似度: 75.00%
————————————————————————
正在载入orig_dis_15.txt
相似度: 63.00%
————————————————————————
正在载入orig_dis_3.txt
相似度: 87.00%
————————————————————————
正在载入orig_dis_7.txt
相似度: 83.50%
————————————————————————
正在载入orig_dis_mix.txt
相似度: 80.00%
————————————————————————
正在载入orig_dis_rep.txt
相似度: 73.50%
———————————————————————— -
测试的性能
-
测试的代码
import unittest import algorithm # 引用一下计算程序,不然代码属实太长 import warnings from BeautifulReport import BeautifulReport class TestForAllTextTfIdf(unittest.TestCase): @classmethod def setUp(self): print("开始单元测试……") @classmethod def tearDown(self): print("已结束测试") def setUpClass(): warnings.simplefilter('ignore', ResourceWarning) def test_rep_tfidf_TextSameError(self): print("正在载入") def test_add(self): print("正在载入orig_add.txt") mini = algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_add.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_del(self): print("正在载入orig_del.txt") mini = algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_del.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_dis_1(self): print("正在载入orig_dis_1.txt") mini=algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_dis_1.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_dis_3(self): print("正在载入orig_dis_3.txt") mini = algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_dis_3.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_dis_7(self): print("正在载入orig_dis_7.txt") mini = algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_dis_7.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_dis_10(self): print("正在载入orig_dis_10.txt") mini = algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_dis_10.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_dis_15(self): print("正在载入orig_dis_15.txt") mini = algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_dis_15.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_mix(self): print("正在载入orig_mix.txt") mini = algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_mix.txt') print('相似度: %.2f%%' % (mini.main() * 100)) def test_rep(self): print("正在载入orig_rep.txt") mini=algorithm.CosineSimilarity('F:/sim_0.8/orig.txt', 'F:/sim_0.8/orig_0.8_rep.txt') print('相似度: %.2f%%' % (mini.main() * 100)) if __name__ == '__main__': #unittest.main() suite = unittest.TestSuite() suite.addTest(Testcase('test_add')) suite.addTest(Testcase('test_del')) suite.addTest(Testcase('test_dis_1')) suite.addTest(Testcase('test_dis_3')) suite.addTest(Testcase('test_dis_7')) suite.addTest(Testcase('test_dis_10')) suite.addTest(Testcase('test_dis_15')) suite.addTest(Testcase('test_mix')) suite.addTest(Testcase('test_rep')) runner = BeautifulReport(suite) runner.report( description='论文查重测试报告', # => 报告描述 filename='nlp_TFIDF.html', # => 生成的报告文件名 log_path='.' # => 报告路径 ) -
算法代码
# coding:utf-8 # 正则包 import re # 自然语言处理包 import jieba import jieba.analyse import io import sys # 机器学习包 from sklearn.metrics.pairwise import cosine_similarity # 计算多个量的余弦值 class CosineSimilarity(object): """ 余弦相似度 """ def __init__(self, orig_position, exam_position): with open(orig_position, encoding='UTF-8') as x, open(exam_position, encoding='UTF-8') as y: content_x = x.read() # 从文件指针所在的位置,读到文件结尾 content_y = y.read() self.s1 = content_x self.s2 = content_y @staticmethod def extract_keyword(content): # 提取关键词 # 切割 seg = [i for i in jieba.cut(content, cut_all=True) if i != ''] # 提取关键词 keywords = jieba.analyse.extract_tags("|".join(seg), topK=200, withWeight=False) return keywords @staticmethod def one_hot(word_dict, keywords): # oneHot编码 # cut_code = [word_dict[word] for word in keywords] cut_code = [0] * len(word_dict) for word in keywords: cut_code[word_dict[word]] += 1 return cut_code def main(self): # 去除停用词 jieba.analyse.set_stop_words('F:/sim_0.8/stopwords.txt') # 提取关键词 keywords1 = self.extract_keyword(self.s1) keywords2 = self.extract_keyword(self.s2) # 词的并集 union = set(keywords1).union(set(keywords2)) # 编码 word_dict = {} i = 0 for word in union: word_dict[word] = i i += 1 # oneHot编码 s1_cut_code = self.one_hot(word_dict, keywords1) s2_cut_code = self.one_hot(word_dict, keywords2) # 余弦相似度计算 sample = [s1_cut_code, s2_cut_code] # 数组中存放数组 # 除零处理 try: sim = cosine_similarity(sample) # 求出余弦的二维数组 return sim[1][0] except Exception as e: print(e) # 打印出错误明细 return 0.0 # 测试 # def begin(orig_position,exam_position): if __name__ == '__main__': similarity = CosineSimilarity(sys.argv[1], sys.argv[2]) # 对类进行赋值 similarity = similarity.main() print('相似度: %.2f%%' % (similarity*100)) #输出两位小数 print('————————————————————————') #z = open(r'F:\pythonProject3\output.txt', 'a', encoding='UTF-8') #result = str('%.2f%%\n' % (similarity * 100)) #z.write(result) #z.close() -
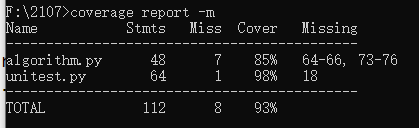
代码覆盖率
三、P2P表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 100 |
| Estimate | 估计这个任务需要多少时间 | 90 | 90 |
| Development | 开发 | 900 | 1000 |
| Analysis | 需求分析 (包括学习新技术) | 200 | 250 |
| Design Spec | 生成设计文档 | 60 | 80 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 25 |
| Design | 具体设计 | 50 | 50 |
| Coding | 具体编码 | 30 | 30 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 120 | 120 |
| Test Repor | 测试报告 | 120 | 120 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 1770 | 1915 |
四、总结
- 刚开始的时候啥也不会,好久好久没打代码了,感觉就像一个清洁工拿着螺丝刀开始造火箭(好绝望)。
- 学习的过程痛并快乐着,感受到软件工程的不易和许多习惯需要慢慢养成。
- 经历了万事开头难的痛苦后希望后几次作业可以顺心一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号