

基于泰坦尼克号 - 机器从灾难中学习
基于泰坦尼克号 - 机器从灾难中学习
一,选题背景
这是传说中的泰坦尼克号ML比赛-最好的,并熟悉自己如何Kaggle平台的工作原理。竞争很简单:使用机器学习来创建一个模型,预测哪些乘客在泰坦尼克号沉船事故中幸存下来。泰坦尼克号沉没是历史上最臭名昭著的沉船事件之一。1912年4月15日,在她的处女航中,被广泛认为是"不沉"的"泰坦尼克号"在与冰山相撞后沉没。不幸的是,船上没有足够的救生艇,导致2224名乘客和船员中有1502人死亡。虽然生存中有一些运气因素,但似乎有些人比其他人更有可能生存下来。
二,机器学习设计方案
提出问题-->理解数据-->数据清洗-->构建模型-->方案实施
三,实现步骤
1.导入数据
数据集来源:https://www.kaggle.com/c/titanic/data
1 import pandas as pd 2 import numpy as np
1 # 读取数据 2 train = pd.read_csv("D:\\Anaconda\\jupyter_data\\titanic\\train.csv") 3 test = pd.read_csv("D:\\Anaconda\\jupyter_data\\titanic\\test.csv") 4 5 # train = pd.read_csv("D:/Anaconda/jupyter_data/titanic/train.csv") 6 # test = pd.read_csv("D:/Anaconda/jupyter_data/titanic/test.csv") 7 print('train:',train.shape, "test:",test.shape) 8 9 # 合并数据集,方便同时对两个数据进行清洗 10 full = train.append(test, ignore_index = True) 11 print('合并后的数据集:',full.shape)

2.初步查看数据集概要信息
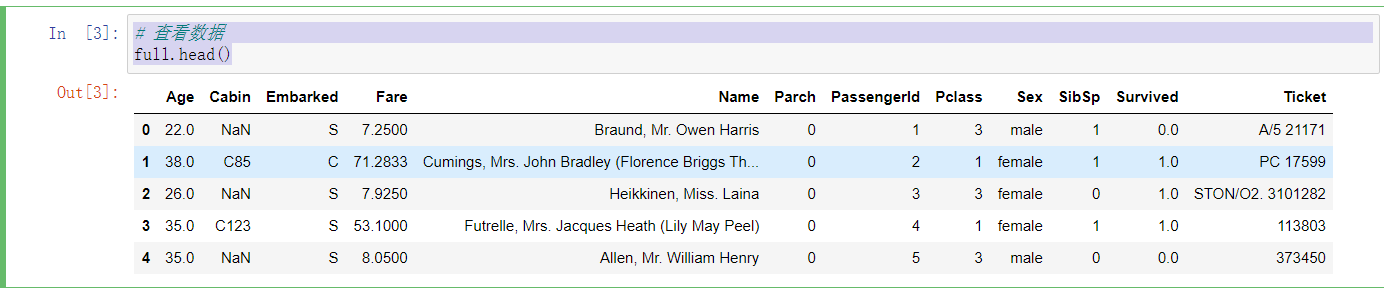
1 # 查看数据 2 full.head()
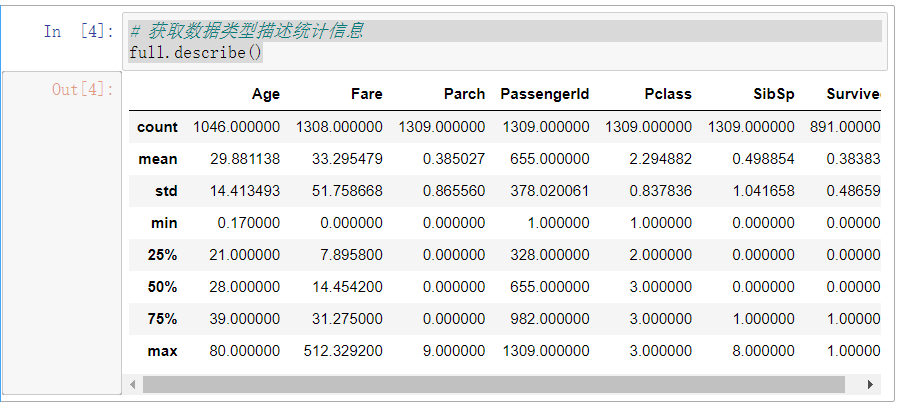
1 # 获取数据类型描述统计信息 2 full.describe()
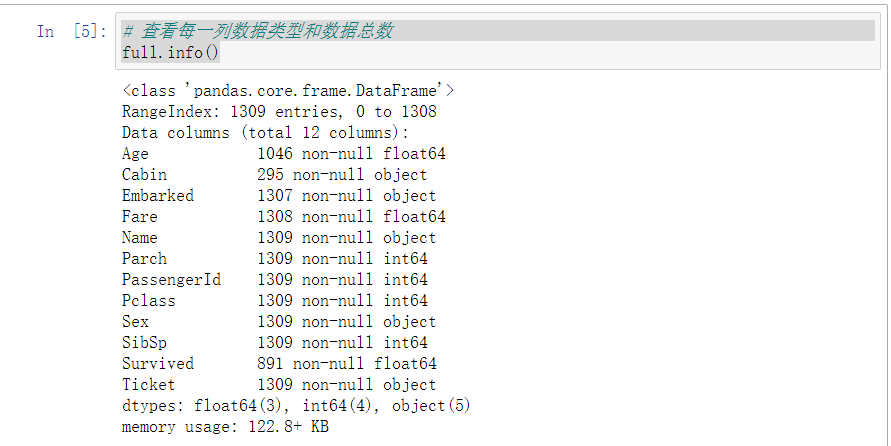
1 # 查看每一列数据类型和数据总数 2 full.info()
3.数据清洗
(1)处理缺失数据
1 # age和fare都存在缺失值,且为浮点数类型,可使用平均值进行填充 2 3 full['Age'] = full['Age'].fillna(full['Age'].mean()) 4 full['Fare'] = full['Fare'].fillna(full['Fare'].mean())
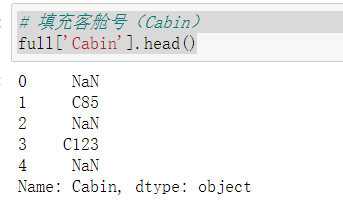
1 # 填充客舱号(Cabin) 2 full['Cabin'].head()
1 # Cabin 这一列缺失值较多且无规律,直接填充U(unknow) 2 full['Cabin'] = full['Cabin'].fillna('U')
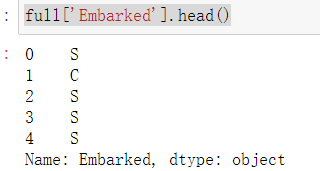
1 # 出发地点:S=南安普敦 途经地点:C=瑟堡,Q=皇后镇 2 full['Embarked'].head()
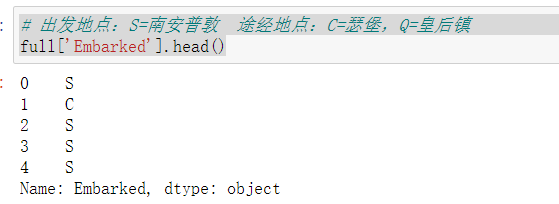
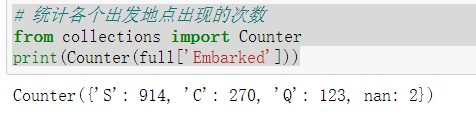
1 # 统计各个出发地点出现的次数 2 from collections import Counter 3 print(Counter(full['Embarked']))
1 # 由于登船港口(Emabrked)这一列只有两个缺失值,将填充为 最频繁出现的S 2 full['Embarked'] = full['Embarked'].fillna('S')
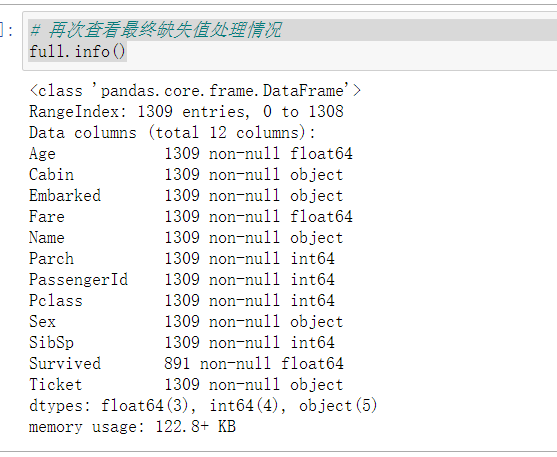
1 # 再次查看最终缺失值处理情况 2 full.info()
(2)提取特征
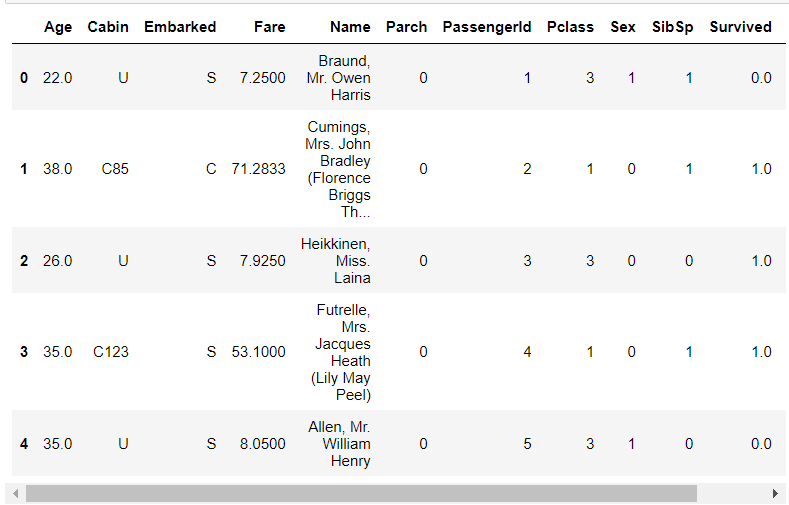
1 """ 2 将性别的值映射为数值, 3 male --> 1 4 female --> 0 5 """ 6 sex_mapDict = {'male':1, 'female':0} 7 # map函数:对于Series 每个数据应用自定义函数计算 8 full['Sex'] = full['Sex'].map(sex_mapDict) 9 full.head()
1 full['Embarked'].head()
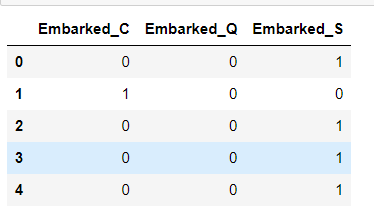
1 # 存放提取后的特征 2 embarkedDF = pd.DataFrame() 3 4 # 使用get_dummies进行one-hot编码,列名前缀为Embarked 5 embarkedDF = pd.get_dummies(full['Embarked'],prefix = 'Embarked') 6 embarkedDF.head()
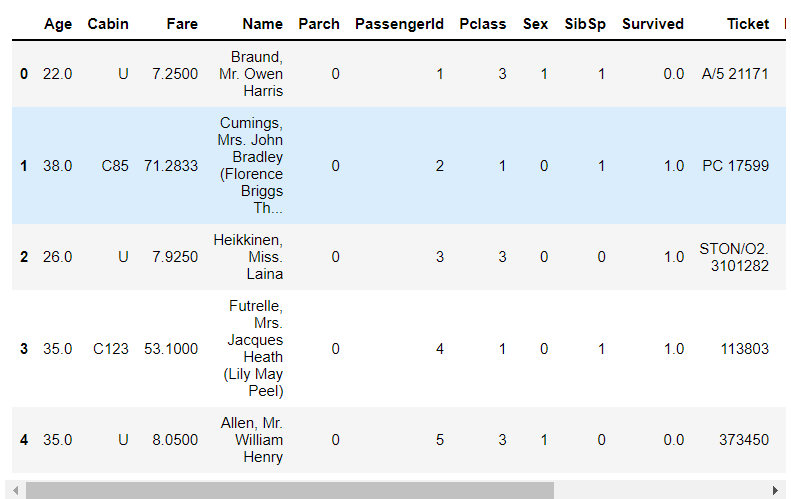
1 # 添加one-hot编码产生的虚拟变量(dummy variables)到泰坦尼克号数据集full 2 full = pd.concat([full, embarkedDF], axis = 1) 3 4 # 因已对登船港口(Embarked)进行了one-hot编码产生虚拟变量,故删除 Embarked 5 full.drop('Embarked', axis = 1, inplace = True) 6 full.head()
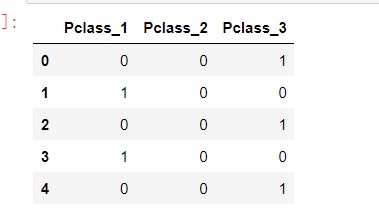
1 # 存放提取后的特征 2 pclassDf = pd.DataFrame() 3 4 # 使用get_dummies进行one-hot编码,列名前缀为Pclass 5 pclassDf = pd.get_dummies(full['Pclass'], prefix = 'Pclass') 6 pclassDf.head()
1 full = pd.concat([full, pclassDf], axis = 1) 2 3 full.drop('Pclass', axis = 1, inplace = True) 4 full.head()
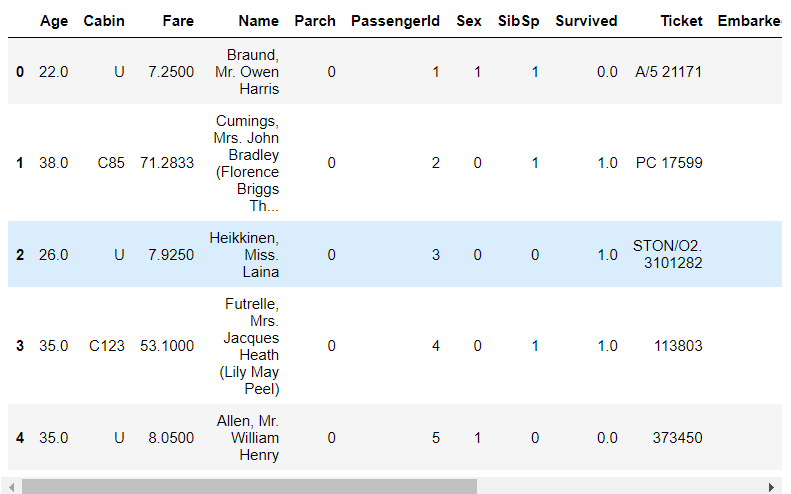
1 full['Name'].head()

1 # 从姓名中获取头衔 2 # split()通过制定分隔符对字符串进行切片 3 def getTitle(name): 4 str1 = name.split(',')[1] 5 str2 = str1.split('.')[0] 6 # strip()移除字符串头尾制定的字符(默认为空格) 7 str3 = str2.strip() 8 return str3 9 10 titleDf = pd.DataFrame() 11 12 # map函数:对于Series每个数据应用自定义函数计数 13 titleDf['Title'] = full['Name'].map(getTitle) 14 titleDf.head()

1 # 从姓名中头衔字符串与自定义头衔类别的映射 2 title_mapDict = { 3 'Capt':'Officer', 4 'Col':'Officer', 5 'Major':'Officer', 6 'Jonkheer':'Royalty', 7 'Don':'Royalty', 8 'Sir':'Royalty', 9 'Dr':'Officer', 10 'Rev':'Officer', 11 'the Countess':'Royalty', 12 'Dona':'Royalty', 13 'Mme':'Mrs', 14 'Mlle':'Miss', 15 'Mr':'Mr', 16 'Mrs':'Mrs', 17 'Miss':'Miss', 18 'Master':'Master', 19 'Lady':'Royalty' 20 } 21 # print(title_mapDict) 22 titleDf['Title'] = titleDf['Title'].map(title_mapDict) 23 # 使用get——dummies进行one-hot编码 24 titleDf = pd.get_dummies(titleDf['Title']) 25 titleDf.head()
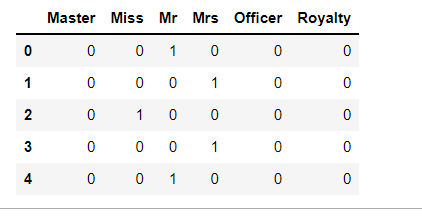
1 # 添加one-hot编码产生的虚拟变量到泰坦尼克号数据集full 2 full = pd.concat([full, titleDf], axis = 1) 3 4 # 删除姓名(Name)这一列 5 full.drop('Name', axis = 1, inplace = True) 6 full.head()
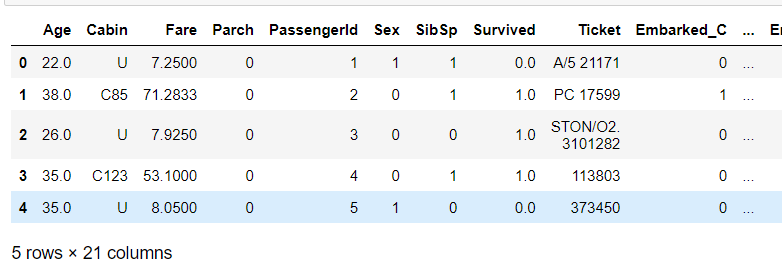
1 full['Cabin'].head()

1 # 存放客舱号信息 2 cabinDf = pd.DataFrame() 3 4 # 客舱号的类别值是首字母, eg:C85 5 6 #定义匿名函数 lambda,用于查找首字母 7 full['Cabin'] = full['Cabin'].map(lambda c:c[0]) 8 9 # 使用get_dummies 进行one-hot 编码, 列名前缀为Cabin 10 cabinDf = pd.get_dummies(full['Cabin'], prefix = 'Cabin') 11 cabinDf.head()
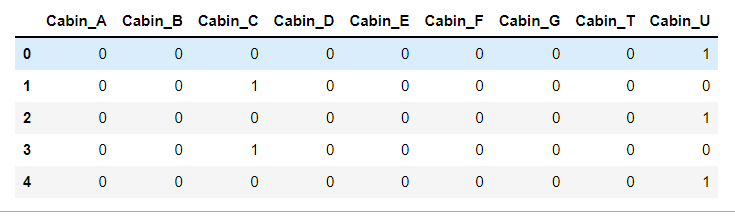
1 # 添加one-hot编码产生的虚拟变量到泰坦尼克号数据集full 2 full = pd.concat([full, cabinDf], axis = 1) 3 # 删除客舱号等级(Pclass)这一列 4 full.drop('Cabin', axis = 1, inplace = True) 5 full.head()
1 # 存放家庭信息 2 familyDf = pd.DataFrame() 3 # 家庭人数 = 同代直系亲属数(SibSp)+ 不同代直系亲属数(Parch)+ 乘客自己 4 familyDf['Familysize'] = full['SibSp'] + full['Parch'] + 1 5 """ 6 家庭类别: 7 小家庭Family_Single:家庭人数=1 8 中等家庭Family_Small:2<=家庭人数<=4 9 大家庭Family_Large:家庭人数>=5 10 """ 11 # if条件为真是返回if前面内容, 否则返回0 12 familyDf['Family_Single'] = familyDf['Familysize'].map(lambda s : 1 if s == 1 else 0) 13 familyDf['Family_Small'] = familyDf['Familysize'].map(lambda s : 1 if 2 <= s <=4 else 0) 14 familyDf['Family_Large'] = familyDf['Familysize'].map(lambda s : 1 if s >= 5 else 0) 15 familyDf.head()
1 # 添加one-hot编码产生的虚拟变量到泰坦尼克号数据集full 2 full = pd.concat([full, familyDf], axis = 1) 3 full.head()
1 # 存放年龄信息 2 ageDf = pd.DataFrame() 3 """ 4 年龄类别: 5 儿童Child:0<年龄<=6 6 青少年Teenager:6<年龄<18 7 青年Youth:18<=年龄<=40 8 中年Middle_age:40<年龄<=60 9 老年Older:60<年龄 10 """ 11 ageDf['Child'] = full['Age'].map(lambda a : 1 if 0 < a <= 6 else 0) 12 ageDf['Teenager'] = full['Age'].map(lambda a : 1 if 6 < a < 18 else 0) 13 ageDf['Youth'] = full['Age'].map(lambda a : 1 if 18 <= a <= 40 else 0) 14 ageDf['Middle_age'] = full['Age'].map(lambda a : 1 if 40 < a <= 60 else 0) 15 ageDf['Older'] = full['Age'].map(lambda a : 1 if a > 60 else 0) 16 ageDf.head()
1 # 添加one-hot编码产生的虚拟变量到泰坦尼克号数据集full 2 full = pd.concat([full, ageDf], axis = 1) 3 # 删除Age这一列 4 full.drop('Age', axis = 1, inplace = True) 5 full.head()
1 # 查看现已有的特征 2 full.shape
(3)特征选择
1 # 相关矩阵 2 corrDf = full.corr() 3 corrDf
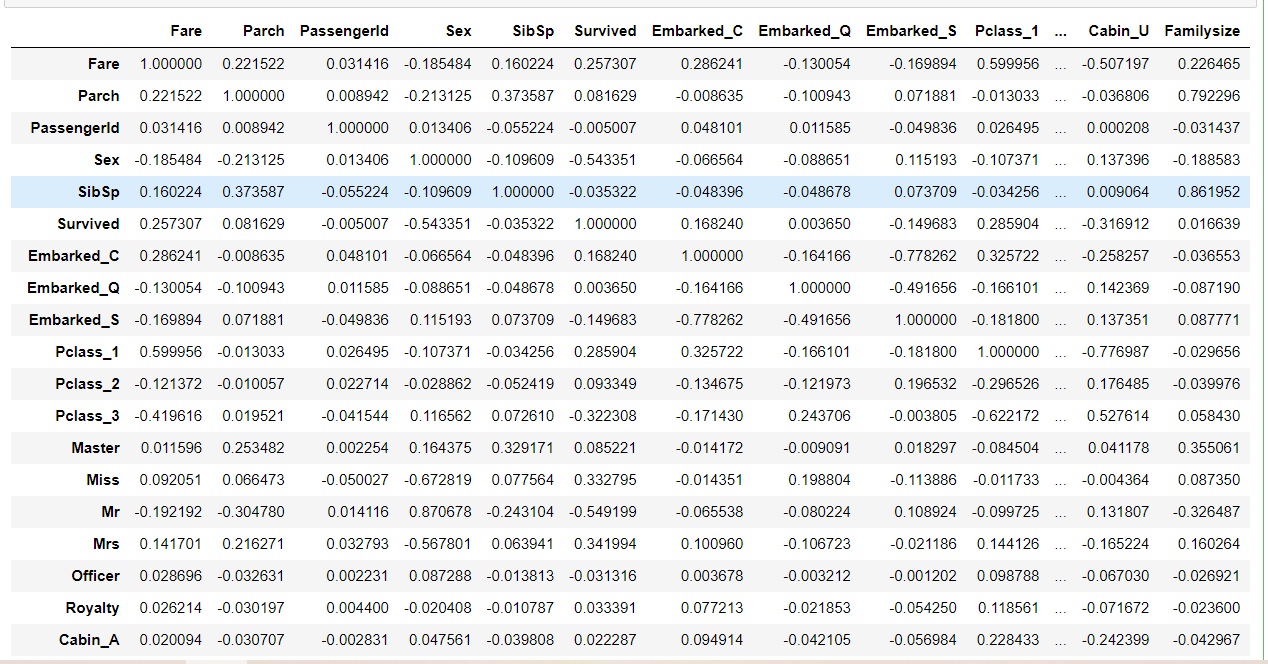
1 # 查看各个特征与生成情况(Survived)的相关系数,ascending = False表示按降序排列 2 3 corrDf['Survived'].sort_values(ascending = False)
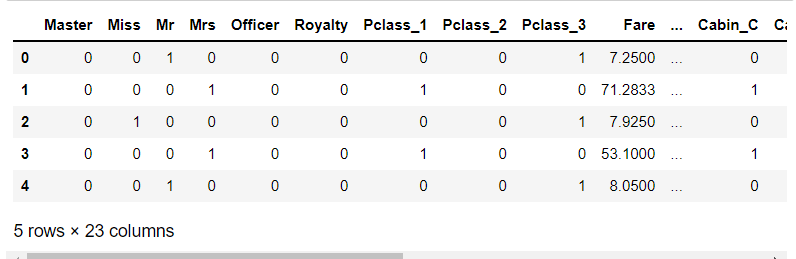
1 # 特征选择 2 full_X = pd.concat([ 3 titleDf, # 头衔 4 pclassDf, 5 full['Fare'], 6 full['Sex'], 7 cabinDf, 8 embarkedDF 9 ], axis = 1) 10 full_X.head()
4构建模型
(1)建立训练集和测试集
1 # 原始数据共有891行 2 sourceRow = 891 3 """ 4 原始数据集sourceRow是从Kaggle下载的训练集,可知共有891条数据从特征集 5 full_X中提取原始数据前891行数据时需减去1,因为行号是从0开始 6 """ 7 # 原始数据集:特征 8 source_X = full_X.loc[0:sourceRow-1,:] 9 # 原始数据集:标签 10 source_y = full.loc[0:sourceRow-1,'Survived'] 11 # 预测数据集:特征 12 pred_X = full_X.loc[sourceRow:,:] 13 # 查看原始数据集有多少行 14 print('原始数据集:', source_X.shape[0]) 15 # 查看预测数据集有多少行 16 print('预测数据集:',pred_X.shape[0])

1 # from sklearn.cross_validation import train_test_split 2 from sklearn.model_selection import train_test_split 3 4 # 建立模型所需的训练数据集合测试集 5 train_X,test_X,train_y,test_y = train_test_split(source_X,source_y,train_size=0.8) 6 # 输出数据集大小 7 print('原始数据集特征:',source_X.shape, 8 '训练数据集特征:',train_X.shape, 9 '测试数据集特征:',test_X.shape,) 10 print('原始数据集标签:',source_y.shape, 11 '训练数据集标签:',train_y.shape, 12 '测试数据集标签:',test_y.shape,)

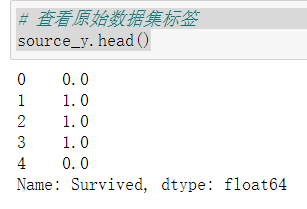
1 # 查看原始数据集标签 2 source_y.head()
(2)选择机器学习算法
1 # 第一步:导入算法 2 from sklearn.linear_model import LogisticRegression 3 # 第二步:创建模型:逻辑回归 4 model = LogisticRegression()
1 # 第三步:训练模型 2 model.fit(train_X, train_y)

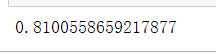
1 # 第四步评估模型 2 # 分类问题 score 得到的是模型正确率 3 model.score(test_X, test_y)
5实施方案
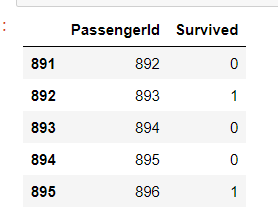
1 # 使用机器学习模型,对预测数据集中的生存情况进行预测 2 pred_y = model.predict(pred_X) 3 4 # 生成的预测值是浮点数,但是Kaggle要求提交的结果是整数型 5 # 使用astype对数据类型进行转换 6 pred_y = pred_y.astype(int) 7 # 乘客id 8 passenger_id = full.loc[sourceRow:,'PassengerId'] 9 # 数据框:乘客id, 预测生存情况 10 predDf = pd.DataFrame({'PassengerId':passenger_id, 'Survived':pred_y}) 11 predDf.shape 12 predDf.head()
# 保存结果 predDf.to_csv('./titanic_pred.csv', index=False)

四,总结
1,通过对泰坦尼克号 - 机器从灾难中学习过程实现,得到了0.81的精度,
2,完成设计过程中,机器学习过程时间过于长需要一直跑测试集,需要改进的地方是如果还将性别变量转换为数字
x[性别][labelencoder_x.fit_转换(x[[性']),问题可能会得到解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号