


04 Hadoop思想与原理,HBase架构与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。从与谷歌系统的关系,关键时间节点,1.x,2.x与3.x的区别,不同公司发行版本等方面来讲。
答:Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。Hadoop 是最受欢迎的在 Internet上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。例如,如果您要 grep 一个10TB 的巨型文件,会出现什么情况?在传统的系统上,这将需要很长的时间。但是 Hadoop 在设计时就考虑到这些问题,采用并行执行机制,因此能大大提高效率。
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。Hadoop最初只与网页索引有关,迅速发展成为分析大数据的领先平台。
有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估的软件。
1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等,该版本已被淘汰
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性,是现在使用的主流版本。
3.x版本系列:对HDFS、MapReduce、YARN都有较大升级,还新增了Ozone key-value存储。
2.用图与自己的话,简要描述名称节点、数据节点的主要功能及相互关系、名称节点的工作机制。
答:主要功能:
1、HDFS 采用主/从架构,主节点即NameNode 从节点即:DataNode
2、NameNode即是模式, 并完成外模式和模式之间的映像,模式和内模式之间的映像。
3、NameNode存放HDFS全局命名空间,充当全局数据目录;存储全局文件系统树,目录-文件-文件块信息
NameNode存放的数据块信息是在启动时扫描所有数据节点重构;
在运行过程中周期性受到数据节点发送的数据块列表信息重构而得;
4、在客户端读取数据过程中,将数据块和数据节点映射按远近排序列表发送给客户端;
5、在客户端写数据过程中,检查文件是否存在、是否有权限;将待写入文件分成若干文件块,并根据数据节点的繁忙和磁盘容量程度,分配数据块和数据节点对应关系列表反馈给客户端;
6、HDFS文件块默认是64M,普通文件块的大小为521字节;
相互关系:
名称节点管理文件系统的命名空间。它维护着这个文件系统树及这个树内所有的文件和索引目录。这些信息以两种形式将文件永久保存在本地磁盘上:命名空间镜像和编辑日志。名称节点也记录着每个文件的每个块所在的数据节点,但它并不永久保存块的位置,因为这些信息会在系统启动时由数据节点重建。
名称结点的工作机制:
名称节点启动时,会将FsImage的内容加载到内存当中,然后执行EditLog文件中的各项操作,使得内存中的元数据保存最新。这个操作完成后,就会创建一个新的FsImage文件和一个空的EditLog文件。名称节点启动成功并进入正常运行状态以后,HDFS中的更新操作都会被写入到EditLog,而不是直接写入FsImage(文件大,直接写入系统会变慢)。
3.分别从以下这些方面,梳理清楚HDFS的结构与运行流程,以图的形式描述。
客户端与HDFS
客户端读
客户端写
数据结点与集群
数据结点与名称结点
名称结点与第二名称结点
数据结点与数据结点
数据冗余
数据存取策略
数据错误与恢复
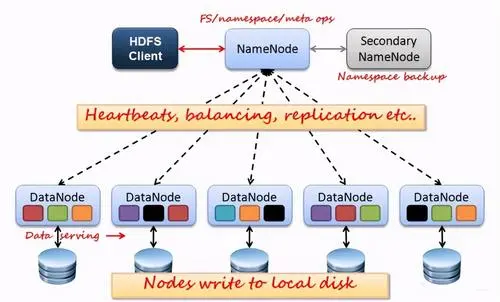
4.简述HBase与传统数据库的主要区别
答:
1.数据类型。关系数据库采用关系模型,具有丰富的数据类型和储存方式。HBase则采用了更加简单的数据模型,它把数据储存为未经解释的字符串,用户可以把不同格式的结构化数据和非结构化数据都序列化成字符串保存到HBase中,用户需要自己编写程序把字符串解析成不同的数据类型。
2.数据操作。关系数据库中包含了丰富的操作,如插入、删除、更新、查询等,其中会涉及复杂的多表连接,通常是借助多个表之间的主外键关联来实现的。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表与表之间的关系,通常只采用单表的主键查询,所以它无法实现像关系数据库中那样的表与表之间的连接操作。
3.存储模式。关系数据库是基于行模式存储的,元祖或行会被连续地存储在磁盘页中。在读取数据时,需要顺序扫描每个元组,然后从中筛选出查询所需要的属性。如果每个元组只有少量属性的值对于查询是有用的,那么基于行模式存储就会浪费许多磁盘空间和内存带宽。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的,它的优点是:可以降低I/O开销,支持大量并发用户查询,因为仅需要处理可以回答这些查询的列,而不是处理与查询无关的大量数据行;同一个列族中的数据会被一起进行压缩,由于同一列族内的数据相似度较高,因此可以获得较高的数据压缩比。
4.数据索引。关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。与关系数据库不同的是,HBase只有一个索引——行键,通过巧妙的设计,HBase中所有访问方法,或者通过行键访问,或者通过行键扫描,从而使整个系统不会慢下来。由于HBase位于Hadoop框架之上,因此可以使用Hadoop MapReduce来快速、高效地生成索引表。
6.数据维护。在关系数据库中,更新操作会用最新的当前值去替换记录中原来的旧值,旧值被覆盖后就不会存在。而在HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍旧保留。
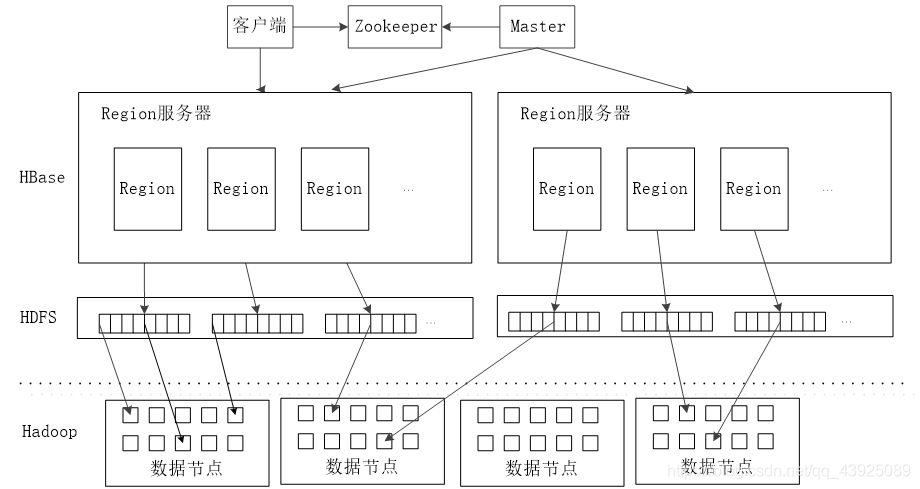
5.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联

 浙公网安备 33010602011771号
浙公网安备 33010602011771号