
how to design a distributed cache?
主题: 设计一个分布式的缓存系统(类似redis)
Senario 分析:
功能需求: put(key,value) get(key)
非功能需求: QPS: 10million/second
Service :
API: 1) POST : put(key,value) 2) GET : get(key)
算法: 但是cache的缓存空间是有限的,我们不希望所有的数据都加到缓存,如何高效利用缓存?
这里有两种算法: LRU(least recent used) 和 LFU (least frequently used) ,算法细节不再展开阐述
storage:
关于storage 我觉得也没什么好说的,我们暂且认为缓存的数据不需要持久化到磁盘
scalable :
我们要的10 millions 的QPS, 单个cache肯定是解决不了问题的,这也是为什么我们要设计分布式的cache
Hashing/sharding
我们应该如何将数据分布到cache节点上? 可以 对key进行hashcode % nodenum 进行hash
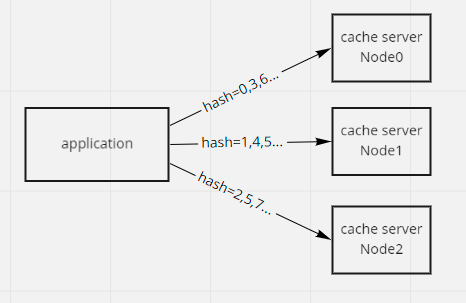
但是如果我要增加节点该怎么办? 如果增加节点的话,可能原来每个节点的部分数据都要进行rehashing,因此我们引出另一个概念 :
consisthashing
对于consist hashing ,我在consist hashing 中进行了阐述,在此就不再过多介绍,总的来讲 consist hashing 能让我们的系统:
1.增加/删除节点时,可以最小化数据rehashing
2.删除某节点时,其负载数据可以均衡的分配到其他节点上,不会对个别节点造成太大压力
load balance
下一步讨论hash/sharding的事情应该由谁来做,一开始我有3种想法,并且不知道该用哪种
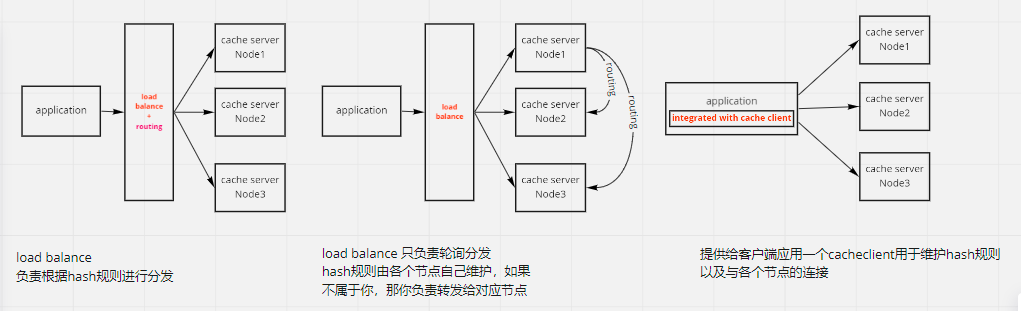
其实后来仔细想想,作为一个cache,性能要求太高了,应该避免多次转发,因此我认为第三种方案时最好的。 客户端直连cache节点,这也让我想起了我之前公司使用分布式内存库 ,用的是”胖客户端“
服务注册问题
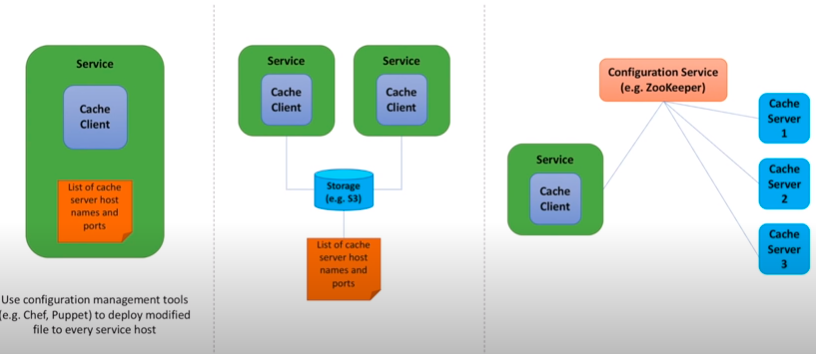
节点信息,以及hash规则,应该存在哪里?
这里有3种方案:
第一种是放到client所在server 磁盘,这样的话每次新增/删除节点或者节点宕机的话,路由数据更新起来太复杂,需要把所有client的server都刷新一遍,不靠谱。。。
第二种是可以存放到一个共享存储上面,比如AWS 的S3 storage,这样所有机器都可以访问同一个文件,方便维护,但是这样我们仍然需要手动去维护它
第三种,我们可以将node节点信息和routing数据存储在类似zk这样的注册中心当中,zk还具有高可用性和观察/监控机制,当节点数据变化时还可以通知订阅者
High Availability 待补充
<leader - follower>
<gossip>
Consistence 待补充
强一致性 和 最终一致性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号