
文本挖掘(二)python 基于scikit-learn计算TF-IDF
简介:前文python jieba+wordcloud使用笔记+词云分析应用讲到可以自定义Idf文档,所以来处理处理。算法已经有现成,本文讲解基本原理及其使用。
参考链接:
sklearn-TfidfVectorizer 计算过程详解
CountVectorize和TfidVectorizer实例及参数详解
1、TF-IDF算法的基本讲解
TF-IDF(Term Frequency-InversDocument Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词的在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。
- TF(Term Frequency)表示某个关键词在整篇文章中出现的频率。
- IDF(InversDocument Frequency)表示计算倒文本频率。文本频率是指某个关键词在整个语料所有文章中出现的次数。倒文档频率又称为逆文档频率,它是文档频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。
计算方法:通过将局部分量(词频)与全局分量(逆文档频率)相乘来计算tf-idf,并将所得文档标准化为单位长度。文件中的文档中的非标准权重的公式,如图:
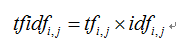
分开的步骤
(1)计算词频
词频 = 某个词在文章中出现的总次数/文章的总词数
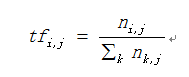
(2)计算逆文档频率
逆文档频率(IDF) = log(词料库的文档总数/包含该词的文档数+1)
2、sklearn计算过程详解
下面为sklearn.TfidfTransformer的计算过程,与百度百科的有些许区别,一是tf使用的是词频,并不是频率;二是idf计算有两种方法,第二种比较平滑。
tf-idf(t, d) = tf(t, d) * idf(t) tf(t,d)表示文本d中词频t出现的词数 idf(t) =idf(t) = log [ n / (df(t) + 1) ]) (if ``smooth_idf=False``) idf(t) = log [ (1 + n) / (1 + df(t)) ] + 1(if ``smooth_idf=True``)
3、常用参数讲解
class CountVectorizer(_VectorizerMixin, BaseEstimator): # stop_words 停用词:string {'english'}, list, default=None def __init__(self, *, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern=r"(?u)\b\w\w+\b", ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=np.int64)
class TfidfTransformer(TransformerMixin, BaseEstimator): # norm = [None,'l1','l2'] 默认为'l2',可设为'l1'或None,计算得到tf-idf值后,如果norm='l2',则整行权值将归一化,即整行权值向量为单位向量,如果norm=None,则不会进行归一化。大多数情况下,使用归一化是有必要的。 # use_idf 默认为True,权值是tf*idf,如果设为False,将不使用idf,就是只使用tf,相当于CountVectorizer了 # smooth_idf 选择是否平滑计算Idf def __init__(self, *, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False):
4、例子展示-计算tf-idf,及输出idf
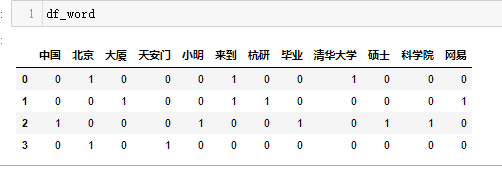
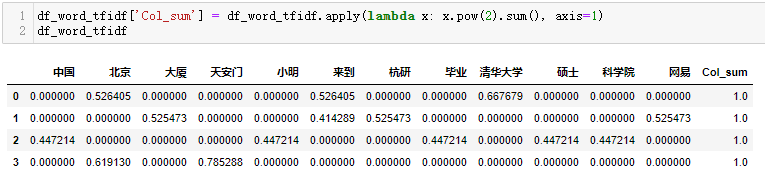
# coding:utf-8 from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer #语料,已经分好词的预料 corpus=["我 来到 北京 清华大学",#第一类文本切词后的结果,词之间以空格隔开 "他 来到 了 网易 杭研 大厦",#第二类文本的切词结果 "小明 硕士 毕业 与 中国 科学院",#第三类文本的切词结果 "我 爱 北京 天安门"]#第四类文本的切词结果 #将文本中的词语转换为词频矩阵 vectorizer = CountVectorizer(stop_words=None) #计算个词语出现的次数 X = vectorizer.fit_transform(corpus) #获取词袋中所有文本关键词 word = vectorizer.get_feature_names() #查看词频结果 df_word = pd.DataFrame(X.toarray(),columns=vectorizer.get_feature_names()) # ---------------------------------------------------- #类调用 transformer = TfidfTransformer(smooth_idf=True,norm='l2',use_idf=True) print(transformer) #将计算好的词频矩阵X统计成TF-IDF值 tfidf = transformer.fit_transform(X) #查看计算的tf-idf df_word_tfidf = pd.DataFrame(tfidf.toarray(),columns=vectorizer.get_feature_names()) #查看计算的idf df_word_idf = pd.DataFrame(list(zip(vectorizer.get_feature_names(),transformer.idf_)),columns=['单词','idf'])
输出:
因为norm='l2',所以tf-idf值会正则化,即每一行每一个字段的平方相加为1.
最后,这个是我们需要的idf值。

总结,训练idf值需要大量的语料库,如果有数据储备可以自行创建,如果没有,则只好寻找更好的资源。当然jieba库里面本身还自带着一个idf.big.txt文件可以使用。
目前学习了分词,tf-df创建,下一步学习snownlp基本使用,再往下就进行gensim的lda主题模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号