

python数据挖掘 pycaret.arules 关联规则学习
1.关联算法应用介绍
关联规则分析是数据挖掘中最活跃的研究方法之一,目的是在一个数据集中找出各项之间的关联关系,而这种关系并没有在数据中直接表示出来。常见于与购物篮分析。
常用关联算法表如下,简单理解的话,就是测算某几项东西一起出现的概率。比如:如果测算得出,大量订单中出现面包、牛奶这两个东西,那么就放在一起销售,增加市场收入。

三个判断准则:支持度(support)、置信度(confident)、提升度(lift)。参考链接:如何理解关联法则中的三个判断准则
1.support(A)= number of A/total items,support(B)= number of B/total items,support(A=>B)= support(B=>A)= number of A and B/total items
2.confidence(A=>B)= number of A and B/number of A,confidence(A=>B)!= confidence(B=>A)
3.lift(A=>B)= confidence(A=>B)/support(B),lift(A=>B)= lift(B=>A)
对三个准则的解释:
support很简单,就是单一商品或者rule出现的概率。我们认为某条规则(rule)出现的次数需要达到一定程度,才能认为这条规则有足够的支持度来支撑其是真实存在的,而不仅仅是因为偶然出现了几次就认为这是一条普遍存在的规则。support是第一道过滤的准则,能够在繁杂众多的交易中过滤出值得我们关注的潜在规则。
confidence我们认为代表着“给定consequent的情况下,antecedent出现的概率”,也就是说是判断规则中两边存在的联系。confidence越高越好,一个高的confidence证明当交易出现了某个antecedent的时候,很大可能会出现某个consequent,也就是某条规则成立的概率越大。
lift融合了support和confidence,代表一条规则中,antecedent和consequent的依赖性,当lift=1的时候,代表给定一个antecedent,某个consequent出现的概率是随机的,也就是说antecedent和consequent相互独立,两者没有任何依赖性,规则不成立。当lift<1的时候,证明antecedent和consequent之间可能存在负依赖性,两者同时存在的概率甚至小于随机选择,若果lift大大小于1,有可能两者是替代商品。当lift>1的时候,则代表两者可能存在正依赖性,顾客买antecedent的时候更倾向于同时购买consequent。
举例:
假设有两个商品A和B,商品A的support是40%,商品B的support是95%,表明40%的交易里面存在A,95%的交易里面存在B,注意,A和B之间在这里仅仅代表自己,40%和95%这两个数值并不代表他们之间存在联系。假如confidence(A=>B)=80%,表明如果顾客购买了A,有80%的顾客同时有购买了B。又假设support(A=>B)足够高,这似乎看起来support和confidence都很高的情况下,A=>B这条规则是很有可能成立的。然而lift只有confidence(A=>B)/support(B)= 80% / 95% =0.8421,也就是说lift不太支持这条规则成立,因为顾客普遍都会买B,导致了support和confidence都偏高而lift则不高。
2.pycaret.arules使用方法
官方链接:https://pycaret.readthedocs.io/en/latest/api/arules.html,整体使用的流程为:
1)setup() :初始化-> create_model() :创建模型-> plot_model()展示模型结果与分析
2)get_rules():查看详细规则,返回pandas.DataFrame
2.1API介绍
初始化:
# pycaret使用模型的第一步,初始化。 # data: pandas.DataFrame # transaction_id: str 识别事务的ID字段 # item_id: str 用于做关联的字段,如:菜品Id列 # ignore_items: list, default = None 规则挖掘中,需要被忽略的规则 # session_id: int, default = None 随机种子?
# return 全局变量
pycaret.arules.setup(data, transaction_id, item_id, ignore_items=None, session_id=None)
创建模型:
#metric:设置评估变量,可以为'confidence',‘support’, ‘lift’, ‘leverage’, ‘conviction’ #threshold: float, default = 0.5,评估变量的最小阈值 #min_support: float, default = 0.05,支持度最小阈值 #round: int, default = 4,设置小数位精确度 #Returns:pandas.DataFrame规则详情 pycaret.arules.create_model(metric='confidence', threshold=0.5, min_support=0.05, round=4)
绘制展示:
# model: pandas.DataFrame, default = none,传入刚刚创建的模型 # plot: str, default = ‘2d’,或'3d',绘制图表类型的参数 # scale: float, default = 1,图像分辨率 pycaret.arules.plot_model(model, plot='2d', scale=1)
其他
具体使用代码:
from pycaret.datasets import get_data data = get_data('france') from pycaret.arules import * exp_name = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description') rule1 = create_model(metric='confidence', threshold=0.7, min_support=0.05) plot_model(rule1, plot='3d')
rule1,字段定义:
-
support(A->C) = support(A+C) [aka ‘support’], range: [0, 1]
-
confidence(A->C) = support(A+C) / support(A), range: [0, 1]
-
lift(A->C) = confidence(A->C) / support(C), range: [0, inf]
-
leverage(A->C) = support(A->C) - support(A)*support(C), range: [-1, 1],emmm,没看出啥意义先。
-
conviction = [1 - support(C)] / [1 - confidence(A->C)], range: [0, inf],emmm,没看出啥意义先。
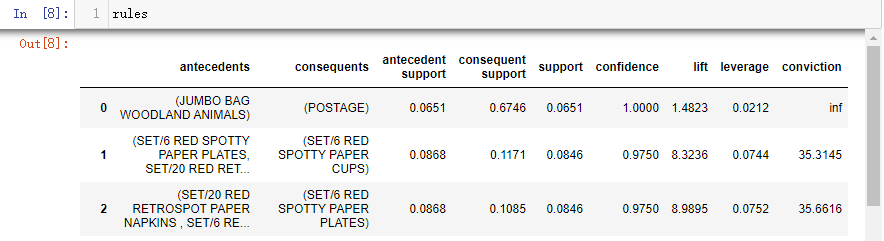
· 实际使用中,应该还有对consequents进行一个筛选,留下自己期望的结果。比如,中医症状与病情,结果仅需要“病情”。
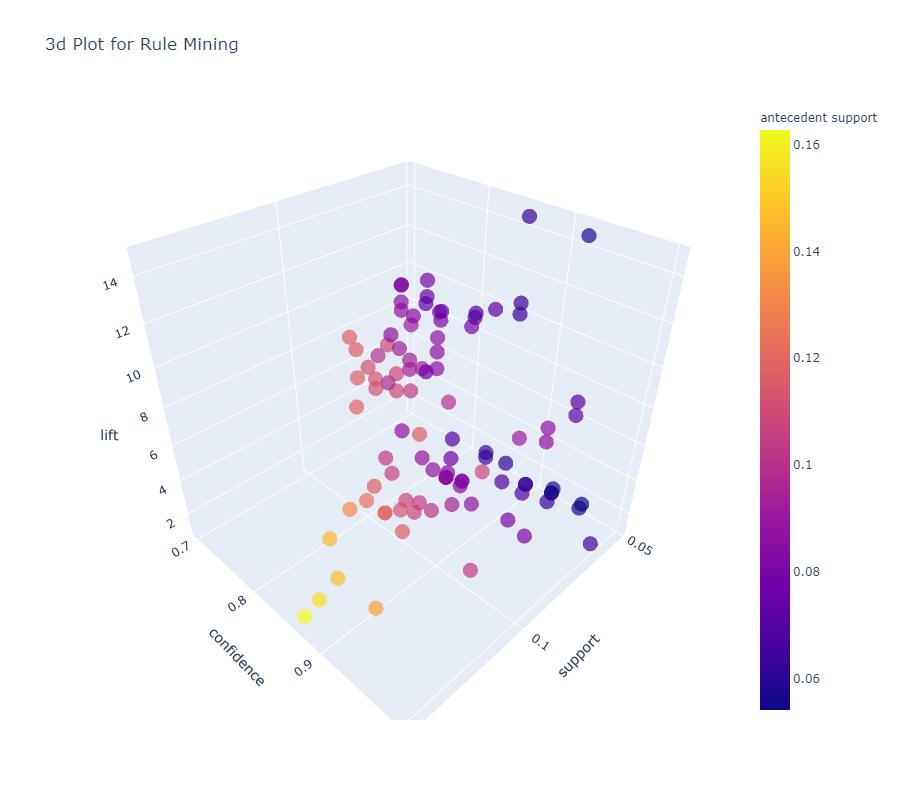
图例显示,3d图形的显示,能够很快的找到相对各参数都比较大的点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号