SQLAlchemy2.0 使用手册 - (一) Core层篇
SQLAlchemy2.0 使用手册 - (一) Core层篇
简介
SQLAlchemy 是 Python 生态系统中最流行的 ORM。SQLAlchemy 设计非常优雅,分为了两部分 —— 底层的 Core 和上层的传统 ORM。在 Python 乃至其他语言的大多数 ORM 中,都没有实现很好的分层设计, 比如 django 的 ORM,数据库链接和 ORM 本身完全混在一起。
SQLAlchemy 当前版本是 1.4. 有两套 API,1.3 及之前的老 API 和 1.4 及之后的 2.0 兼容 API。本文中只介绍 2.0 API。
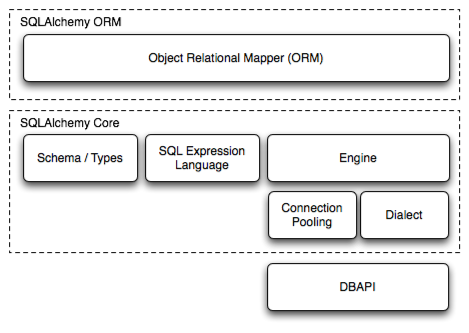
SQLAlchemy 架构中的 Core 层 和 ORM 层:
- SQLAlchemy 的 Core 层 是架构中的底层基础,直接与数据库交互,提供了比 ORM 更灵活、更接近 SQL 的操作方式。Core 层主要实现了数据库连接池(Connection Pool)、数据库引擎(Engine)、事务控制(Transaction)等核心作用。
- SQLAlchemy 的 ORM 层(Object-Relational Mapping Layer) 是架构中更高阶的抽象层,核心作用是将数据库的表结构映射为 Python 类,将数据库行记录映射为 Python 对象,使开发者能用面向对象的方式操作数据库,而无需直接编写 SQL 语句。
| 场景 | Core 层 | ORM 层 |
|---|---|---|
| 简单 CRUD | 需手动编写 SQL 或表达式 | 直接操作对象(如 session.add()) |
| 复杂查询 | 灵活编写多表 JOIN、子查询 | 可能需结合 session.execute() 回退到 Core |
| 高性能批量操作 | 直接使用 insert() + 参数列表批量插入 |
ORM 的 bulk_save_objects() 性能较低 |
| 数据库架构管理 | 通过 MetaData 创建/删除表 |
依赖 Alembic 迁移工具 |
| 直接控制 SQL | 支持原始 SQL(text()) |
优先使用 ORM 查询,必要时混合 SQL |
安装 SQLAlchemy
1、通过 pip 安装 SQLAlchemy 是最简单的方式。在命令行或终端中运行以下命令:
# 安装 SQLAlchemy
pip install sqlalchemy
# 安装最新版本的 SQLAlchemy
pip install --upgrade sqlalchemy
# 安装特定版本的 SQLAlchemy
pip install sqlalchemy==2.0.38
2、安装数据库驱动:
# 安装 mysqlclient
pip install mysqlclient
# 或 安装 pymysql
pip install pymysql
注:SQLite 是 Python 标准库的一部分,不需要额外安装驱动。
3、安装完成后,可以通过以下代码验证 SQLAlchemy 是否安装成功:
from sqlalchemy import create_engine
# 创建一个内存数据库引擎(SQLite)
engine = create_engine("sqlite:///:memory:")
# 测试连接
with engine.connect() as connection:
print("SQLAlchemy 安装成功!")
创建链接
create_engine 使用示例
SQLAlchemy 中使用 create_engine 来创建连接(池)。create_engine 的参数是数据库的 URL。
from sqlalchemy import create_engine
# create_engine 使用示例
engine = create_engine(
# 创建的数据库连接格式为:<database_type>+<driver_name>://<username>:<password>@<host>:<port>/<dbname>[?<options>]
"mysql+pymysql://user:password@localhost:3306/dbname",
echo=True, # echo 设为 True 会打印出实际执行的 sql,调试的时候更方便,默认值:False
future=True, # 启用 SQLAlchemy 2.0 API,向后兼容,默认值:False
pool_size=5, # 连接池的大小默认为 5 个,设置为 0 时表示连接无限制,默认值:5
pool_recycle=3600, # 设置连接回收时间,以限制数据库自动断开连接,默认值:-1(不回收)
pool_timeout=30, # 获取连接的超时时间,默认值:30秒
pool_pre_ping=True, # 检测连接是否有效,从连接池中获取连接时先发送一个简单的 SQL 查询(如 SELECT 1 ),默认值:False
max_overflow=10, # 最大溢出连接数,连接总数不能超过 pool_size + max_overflow,默认值:10
connect_args={"connect_timeout": 10}, # 数据库连接参数,以字典形式提供,默认值:空字典
isolation_level="READ COMMITTED", # 设置数据库事务隔离级别,默认值:None(由数据库决定)
)
# 注:创建一个 SQLite 的内存数据库,必须加上 check_same_thread=False 数据库连接参数,否则无法在多线程中使用
engine = create_engine("sqlite:///:memory:", echo=True, future=True, connect_args={"check_same_thread": False})
# pip install mysqlclient
engine = create_engine('mysql+mysqldb://user:password@localhost/foo?charset=utf8mb4')
创建一个 client 工具类
创建 SQLAlchemySyncManager 同步客户端工具类:
@singleton
class SQLAlchemySyncManager:
"""SQLAlchemy 2.0+ 数据库客户端管理器 (同步模式)"""
def __init__(
self,
sync_driver: str = "mysql+pymysql", # 同步驱动 ("mysql+aiomysql" 异步驱动示例)
username: str = "root",
password: str = "password",
host: str = "localhost",
port: int = 3306,
database: str = "test_db",
pool_size: int = 5,
max_overflow: int = 10,
ssl_ca: Optional[str] = None
):
self._sync_url = self._build_url(
drivername=sync_driver,
username=username,
password=password,
host=host,
port=port,
database=database,
ssl_ca=ssl_ca
)
self.sync_engine: Engine = create_engine(
self._sync_url,
echo=True, # 打印执行的 sql,默认为 False
future=True, # 使用 SQLAlchemy 2.0 API
pool_size=pool_size, # 设置连接池的大小
max_overflow=max_overflow, # 设置最大溢出连接数
pool_recycle=3600 # 设置时间以限制数据库自动断开, 默认值:-1(不回收)
)
self.SyncSession = sessionmaker(bind=self.sync_engine) # 创建会话工厂
@staticmethod
def _build_url(
drivername: str,
username: str,
password: str,
host: str,
port: int,
database: str,
ssl_ca: Optional[str]
) -> URL:
"""构建 SQLAlchemy URL (支持 SSL)"""
query_params = {}
if ssl_ca:
query_params = {
"ssl": {"ca": ssl_ca},
"charset": "utf8mb4"
}
return URL.create(
drivername=drivername,
username=username,
password=password,
host=host,
port=port,
database=database,
query=query_params
)
@contextmanager
def sync_session(self) -> Generator[Session, None, None]:
"""同步会话上下文管理器(session自动提交场景下使用)"""
session = self.SyncSession()
try:
yield session
session.commit()
except Exception as e:
session.rollback()
raise e
finally:
session.close()
def get_sync_sqlclient() -> SQLAlchemySyncManager:
return SQLAlchemySyncManager(
sync_driver="mysql+pymysql",
username="root",
password="123456",
database="t_database"
)
if __name__ == "__main__":
db = get_sync_sqlclient()
Core 层
Core 层 CRUD
在 SQLAlchemy 的 Core 层 中,CRUD(增删改查)操作通过 SQL 表达式语言直接操作数据库表,无需依赖 ORM 模型。以下是详细示例与说明:
表结构定义
from sqlalchemy import Table, Column, Integer, String, MetaData
metadata = MetaData() # 获取数据库表的元数据信息
# 定义 car_review 表
car_review = Table(
"car_review", metadata,
Column("id", Integer, primary_key=True),
Column("label_workflow", String(50)),
Column("opinion", String(200))
)
# 创建存储在该元数据中的所有表
metadata.create_all(engine) # engine 是已创建的数据库引擎
Insert(插入数据)
# 单条插入,构建 INSERT 语句
stmt = insert(car_review).values(
label_workflow="pending",
opinion="Initial review"
)
with engine.connect() as conn:
result = conn.execute(stmt) # 执行插入
conn.commit() # 显式提交事务
print("Inserted ID:", result.inserted_primary_key)
# 批量插入
data = [
{"label_workflow": "approved", "opinion": "Good quality"},
{"label_workflow": "rejected", "opinion": "Needs improvement"}
]
# 批量执行(自动优化为单个多值 INSERT 语句)
with engine.connect() as conn:
conn.execute(insert(car_review), data) # 直接传递数据列表
conn.commit()
Query(查询数据)
# 基础查询,构建 SELECT 语句
stmt = select(car_review.c.id, car_review.c.label_workflow)
with engine.connect() as conn:
result = conn.execute(stmt)
for row in result: # 执行查询(结果以 Row 对象形式返回)
print(f"ID: {row.id}, Status: {row.label_workflow}")
# 条件过滤查询
from sqlalchemy import and_
stmt = select(car_review).where(
and_(
car_review.c.label_workflow == "pending",
car_review.c.opinion.like("%urgent%")
)
)
with engine.connect() as conn:
result = conn.execute(stmt)
for row in result.mappings(): # mappings() 可以使用字典的形式访问
print(row["label_workflow"], row["opinion"])
Update(更新数据)
# 构建 UPDATE 语句
stmt = (
update(car_review)
.where(car_review.c.id == 1)
.values(
label_workflow="approved",
opinion="Final approval after review"
)
)
with engine.connect() as conn:
conn.execute(stmt)
conn.commit()
Delete(删除数据)
# 构建 DELETE 语句
stmt = delete(car_review).where(
car_review.c.label_workflow == "rejected"
)
with engine.connect() as conn:
conn.execute(stmt)
conn.commit()
使用原生 SQL 语句
from sqlachemy import text
with engine.connect() as conn:
result = conn.execute(text("select * from users"))
print(result.all())
# result: CursorResult 对象可以遍历,每一个行结果是一个 Row 对象
for row in result:
# Row 对象支持的访问方式
print(row.x, row.y)
print(row[0], row[1])
# 传递参数,使用 `:var` 传递
result = conn.execute(
text("SELECT x, y FROM some_table WHERE y > :y"),
{"y": 2}
)
# 也可以预先编译好参数
stmt = text("SELECT x, y FROM some_table WHERE y > :y ORDER BY x, y").bindparams(y=6)
# 插入时,可以直接插入多条
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 11, "y": 12}, {"x": 13, "y": 14}]
)
事务与 commit
SQLAlchemy 提供两种提交的方式,一种是手工 commit,一种是半自动 commit。官方文档建议使用 engine.begin()。还有一种完全自动的,每一行提交一次的 autocommit 方式,不建议使用。
# "commit as you go" 需要手动 commit
with engine.connect() as conn:
conn.execute(text("CREATE TABLE some_table (x int, y int)"))
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 1, "y": 1}, {"x": 2, "y": 4}]
)
conn.commit() # 注意这里的 commit
# "begin once" 半自动 commit
with engine.begin() as conn:
conn.execute(
text("INSERT INTO some_table (x, y) VALUES (:x, :y)"),
[{"x": 6, "y": 8}, {"x": 9, "y": 10}]
)
engine.begin() 方法源码实现如下:
# 生成上下文管理器
@contextlib.contextmanager
def begin(self) -> Iterator[Connection]:
with self.connect() as conn:
"""
begin() 返回一个事务的上下文管理器,它会在 with 块退出时调用 commit() 或 rollback()
"""
with conn.begin():
yield conn
Row 对象理解
在 SQLAlchemy 中,当使用 Core 层API(非 ORM层)执行查询时,通常返回的是 Row 对象。Row 对象 基于元组的底层存储结构 结合 动态属性映射 的混合设计,能够通过 row.name 的方式直接访问属性字段数据,同时还保持了类似元组的特性,使得操作数据更加灵活和高效。
Row 对象的简化理解及实现解析:
class Row:
def __init__(self, data, keymap):
self.data = data # 元组存储数据
self._keymap = keymap # 列名到索引的映射
def __getitem__(self, index):
return self.data[index]
def __getattr__(self, name):
try:
index = self._keymap[name]
return self.data[index]
except KeyError:
raise AttributeError(f"No column '{name}'")
def _asdict(self):
return {name: self.data[idx] for name, idx in self._keymap.items()}
# 使用示例
data = (1, "Alice", "alice@example.com")
keymap = {'id': 0, 'name': 1, 'email': 2}
row = Row(data, keymap)
print(row[0]) # 1
print(row.name) # "Alice"
print(row._asdict()) # {'id': 1, 'name': 'Alice', 'email': 'alice@example.com'}
在本文中,我们已经介绍了 SQLAlchemy 的 Core 层基础功能与使用方法。下一篇文章,我们将聚焦于 ORM 层,了解对象关系映射的操作数据库交互方式。
参考资料
————————————————

 浙公网安备 33010602011771号
浙公网安备 33010602011771号