浅谈自学Python之路(day2)
今天的主要内容是:
- 标准库
- 数据类型知识
- 数据运算
- 三元运算
- bytes类型
- 字符串操作
- 字典
- 集合
标准库
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,先来介绍2个简单的。
sys
import sys print(sys.path)#打印环境变量
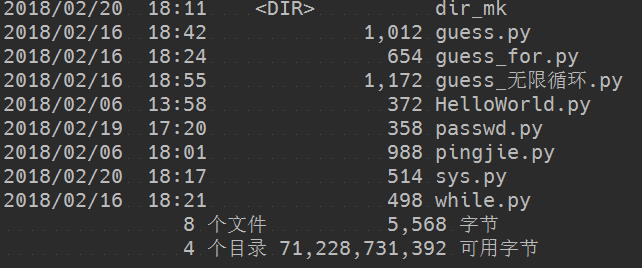
输出结果为:

os
import os os.mkdir("dir_mk")
此代码段含义为,在当前目录下新建一个文件夹,输出结果为:

文件夹下出现了新建的dir_mk文件夹:
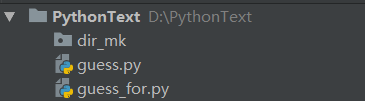
import os cmd_res = os.system("dir") #执行命令,但不保存结果
dir:查看当前路径下的文件,但此时输出结果有乱码,可以换为:
cmd_res = os.popen("dir").read() #read方法把它取出来
print("-->",cmd_res) #把它输出
这样输出结果如下:
简单明了
- 自己写个模块
就以之前写的登录程序为例,将其复制改名为login,然后在调用这个模块

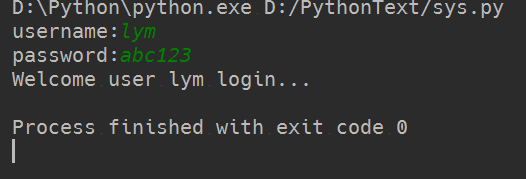
1 _username = 'lym' 2 _password = 'abc123' 3 username = input("username:") 4 #password = getpass.getpass("password:") 5 password = input("password:") 6 if _username == username and _password == password: 7 print("Welcome user {name} login...".format(name=username)) 8 else: 9 print("Invalid username or password!")
然后调用
import login
结果如下

接着手动输入用户名密码
这样一个简单的创建模块就创建好了,当然上面自己写的login.py模块只能在当前目录下导入,如果想在系统的何何一个地方都使用怎么办呢? 此时你就要把这个login.py放到python全局环境变量目录里啦,基本一般都放在一个叫做 python/lib/site-packages 的文件夹目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python的环境变量列表
数据类型知识
1.数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
2.布尔值
真或假
0或1
3.字符串
"hello world"
1 name = "lym" 2 print "i am %s " % name 3 #输出: i am lym
PS: 字符串是 %s;整数 %d;浮点数%f
- 移除空白
- 分割
- 长度
- 索引
- 切片
4.列表(开发中最常用的其中一种)
1 print("----------------------") 2 names = "LiangFF Guoy LiuZY XinY" 3 names = ["LiangFF","Guoy","LiuZY","XinY"] 4 names.append("GouJ")#添加到最后 5 names.insert(1,"GeD")#插入 6 names[2] = "WuX"#替换 7 8 print(names) 9 print(names[0],names[1]) 10 print(names[1:4])#切片,顾头不顾尾,所以打印的值为,第2,3,4个值,第5个值不打印(即names[4]),这就是顾头不顾尾,用数学符号表示即[ ) 11 print(names[-2:-1])#不能为[-1:-2],因为顺序是从左往右 12 print(names[-2:]) 13 print(names[0:3]) 14 print(names[:3]) 15 print("----------------------") 16 #删除 17 names.remove("WuX") 18 del names[2]#删除第三个值 19 names.pop()#删掉最后一个 20 print(names) 21 print("----------------------") 22 names.reverse()#反转 23 print(names) 24 print("----------------------") 25 names.sort()#排序 26 print(names) 27 print("----------------------") 28 print(names.index("GeD"))#查询值所在位置 29 print(names[names.index("GeD")]) 30 print(names.count("GeD"))#查询有几个GeD值 31 print("----------------------") 32 names.clear()#清空 33 print(names) 34 print("----------------------") 35 names = ["LiangFF","Guoy","LiuZY","XinY"] 36 names2 = [1,2,3,4] 37 names.extend(names2)#names2合并到names中 38 print(names,names2)
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
1 import copy 2 3 names = ["LiangFF","Guoy","LiuZY",["jack","mike"],"XinY"] 4 names2 = copy.deepcopy(names) #names2 = copy.copy(names) 此为浅copy 5 print(names[0:-1:2]) 6 print(names[::2])#0或-1可以省略 7 # for i in names: 8 # for j in names2: 9 # print(i,j) 10 11 print(names) 12 print(names2) 13 14 names[2] = "刘泽宇" 15 print(names) 16 print(names2) 17 18 names[3][0] = "JACK" 19 print(names) 20 print(names2)
输出结果为:
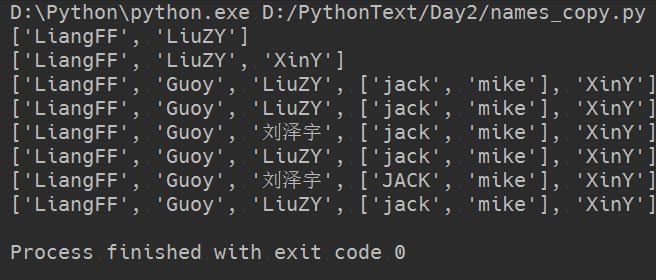
以上结果为深度Copy的结果,即names2将names的值完全copy下来,而且完全不做改动,具体有什么区别,上面的代码段中有浅copy的代码,大家可以试一试看看有什么区别,在这里就不做演示了
但还要补充2个额外的浅copy写法,代码如下:
names2 = names[:]
或者是
names2 = list(names)
这两种写法,和浅copy names2 = copy.copy(names) 是一样的作用,大家有兴趣可以尝试
其中
print(names[0:-1:2])
这段代码意思是,输出names中从的第一个值,到最后一个值,而且步数为2(隔一个输出一个值),也可以写为
print(names[::2])#0或-1可以省略
但第二种写法 print(names[::2]) 较好,因为如果值是五个的话,用第一种写法 print(names[0:-1:2]) ,第五个是输出不了的,可以先看一下输出的结果

第二种就可以把第1,3,5的值都输出,第一种则不行,如果值的个数为6,即有6个值,那么这两种写法都会输出1,3,5这三个值,即上下输出结果是一样的,本质上这两种写法的含义是相同的,可能第二种写法的排异性会好些,建议写第二种
补充Copy的用法—创建联合账号
1 #浅Copy用处用来创建联合账号 2 person = ["name",["saving",100]] 3 4 p1 = person[:] 5 p2 = person[:] 6 7 p1[0] = "lym" 8 p2[0] = "ym" 9 10 p1[1][1]=50 11 12 print(p1) 13 print(p2)
输出结果为:
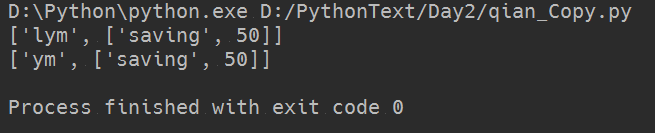
当我修改了P1中第二个数组中的第二个数为50时,输出时,P2当中第二个数组的第二个数也变为了50
1 names = ('lff','ged') 2 names.append('guoy') 3 print(names)
结果是报错的:
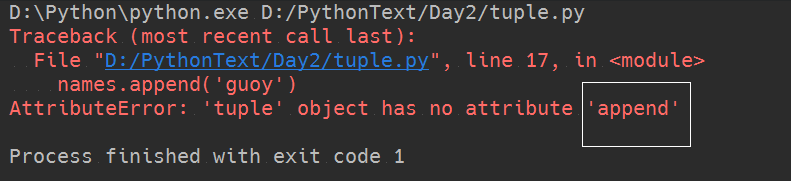
说明上面的代码只是演示了为什么元组只能查不能添加
它只有2个方法,一个是count,一个是index,完毕。
练习:写出购物车程序
需求:
- 启动程序后,让用户输入工资,然后打印商品列表
- 允许用户根据商品编号购买商品
- 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
- 可随时退出,退出时,打印已购买商品和余额
1 person = {"name": "mr.wu", 'age': 18} 2 或 3 person = dict({"name": "mr.wu", 'age': 18})
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
数据运算
- 首先举个简单的例子 4 +5 = 9 。 例子中,4 和 5 被称为操作数,"+" 称为运算符。

比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:

运算符优先级:

三元运算
1 a = 10 2 b = 5 3 c = 4 4 d = a if a > b else c 5 print("d =",d)
输出结果为:

如果条件为假:d = c
bytes类型
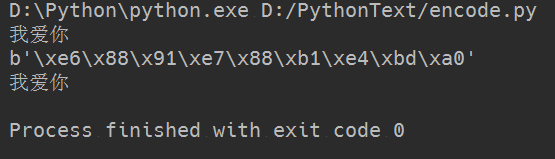
1 msg = "我爱你" 2 print(msg) 3 print(msg.encode(encoding = "utf-8"))#字符串转成byte类型 4 print(msg.encode(encoding = "utf-8").decode(encoding="utf-8"))#再转回来
字符串操作
- 特性:不可修改
1 #!/usr/bin/env.python 2 # -*- coding: utf-8 -*- 3 """ 4 ------------------------------------------------- 5 File Name: string 6 Description : 7 Author : lym 8 date: 2018/2/27 9 ------------------------------------------------- 10 Change Activity: 11 2018/2/27: 12 ------------------------------------------------- 13 """ 14 __author__ = 'lym' 15 16 name = "lym is a good boy" 17 print(name.capitalize())#首字母大写 18 print(name.count("l"))#统计l出现次数 19 print(name.casefold())#大写全部变小写 20 print(name.center(50,"-"))#输出输出 '---------------------lym----------------------' 21 print(name.encode())#将字符串编码成bytes格式 22 print(name.endswith("m"))#判断字符串是否以m结尾 23 print( "lym\tlff".expandtabs(10))#输出"lym lff", 将\t转换成多长的空格 24 print(name.find('a'))#查找m,找到返回其索引,找不到返回-1 25 print(name[name.find('a'):])#字符串切片 输出 a good boy 26 27 name = "my name is {name},and i am {age} years old" 28 print(name.format(name = "lym",age = 22)) #格式化输出,可参考Day1格式化输出内容 29 print(name.format_map({'name':'lym','age':22}))#字典 30 print('ab123'.isalnum())#包含所有的英文字符+阿拉伯数字 返回True 31 print('ab123\f'.isalnum())#若有特殊字符则返回False 32 print('abc'.isalpha())#包含所有的英文,包括大写英文 33 print('1A'.isalpha())#十进制返回True,其他返回False 34 print('12'.isdigit())#是不是一个整数 35 print('a123'.isidentifier())#判断是否为一个合法的标识符,若开头为数字,则返回False 36 print('A23'.islower())#判断首字母是否为小写,若为小写则返回True 37 print('A23'.isnumeric())#是否只有数字在里面,若是则返回True 38 print('A23'.isspace())#是否是一个空格 39 print('My Name Is Lym'.istitle())#每个单词开头是否为大写,若是则返回True 40 print('My Name Is Lym'.isprintable())#是不是可以打印的,比如 ttf.file,drive file是不可打印的,用途较少 41 print('My Name Is Lym'.isupper())#是否都为大写,若是则返回True 42 print('My Name Is Lym'.join("==")) 43 print('+'.join(['1','2','3','4'])) 44 print(name.ljust(50,'*'))#内容加在‘*‘左边 45 print(name.rjust(50,'~'))#内容加在‘~’右边 46 print('Lym'.lower()) 47 print('Lym'.upper()) 48 print('\nLym\n'.lstrip())#去除左边的空格 49 print('----------') 50 print('\nLym\n'.rstrip())#去除右边的空格 51 print('----------') 52 print('\nLym\n'.strip())#左右空格都去掉 53 print('----------') 54 print('Lym'.strip()) 55 56 p = str.maketrans("abcdefli",'123$@456') 57 print("yiming liang".translate(p) ) 58 59 print('yiming liang'.replace('l','L',1))#替换 60 print('yiming liang'.rfind('l'))#找从左往右数最右边的l的索引值 61 print('1+2+3+4'.split('+'))#把字符串按照+号分成一个列表,+号可以用其字符串中的任意值代替,就按你代替的值来分 62 print('1+2\n+3+4'.splitlines())#按换行来分 63 print('yiming LIAng'.swapcase())#大小写反转 64 print('yiming liang'.title())#每个单词开头字幕大写 65 print('yiming liang'.zfill(50))#在最前面加50个0 66 67 print( '---')
字典
1 #key-value 键—值 2 info = { 3 '204': "ym", 4 '205': "zq", 5 '206': "aq", 6 } 7 print(info) 8 #字典是无序的,字典不需要下标,通过key查找 9 print(info["204"]) 10 11 info["204"]="lp"#如果存在,则将204里的值ym替换为lp 12 print(info) 13 info["207"]="zr"#如果字典中不存在207,则添加一个新的 14 print(info) 15 16 #delete 17 del info["207"]#删除207 18 print(info) 19 20 info.pop("205")#删除205 21 print(info) 22 info.popitem()#随便删一个 23 print(info) 24 #--------------------查----------------------------- 25 info = { 26 '204': "ym", 27 '205': "zq", 28 '206': "aq", 29 } 30 print(info.get("205")) 31 print('204' in info)#info.has_key("205") 这个在py2.x py3里没有了 32 #--------------------update------------------------ 33 info = { 34 '204': "ym", 35 '205': "zq", 36 '206': "aq", 37 } 38 b = { 39 '204':'haa', 40 1:3, 41 2:4 42 } 43 info.update(b) 44 print(info) 45 #合并两个字典,有交叉就覆盖,无交叉就创建 ;204 ym替换haa;1:3 2:4加入info 46 print(info.items())#字典转为列表 47 #--------------------初始化一个新的字典------------------------ 48 c = dict.fromkeys([6,7,8],"asd")#尽量别用 49 print(c)
字典的特性:
- dict是无序的
- key必须是唯一的
1 #!/usr/bin/env.python 2 # -*- coding: utf-8 -*- 3 """ 4 ------------------------------------------------- 5 File Name: more_dictionary 6 Description : 7 Author : lym 8 date: 2018/3/2 9 ------------------------------------------------- 10 Change Activity: 11 2018/3/2: 12 ------------------------------------------------- 13 """ 14 __author__ = 'lym' 15 16 #目录 17 av_catalog = { 18 "欧美":{ 19 "www.youporn.com": ["很多免费的,世界最大的","质量一般"], 20 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], 21 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], 22 "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] 23 }, 24 "日韩":{ 25 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] 26 }, 27 "大陆":{ 28 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] 29 } 30 } 31 av_catalog["大陆"]["1024"][1] = "啊哈哈哈哈哈" 32 33 av_catalog.setdefault("台湾",{"1025":["台湾小姐姐美","美若天仙的台湾小姐姐"]})#如果没有台湾,则添加台湾,如果字典中有台湾,则不变 34 35 for k in av_catalog: 36 print(k,av_catalog[k])#打印 key ,value 37 print("--------------打印values的值-------------") 38 print(av_catalog.values()) 39 print("--------------打印key的值-------------") 40 print(av_catalog.keys())
循环格式:
1 for k in av_catalog: 2 print(k,av_catalog[k])#打印 key ,value
另外一种循环格式,先将字典转成列表,在循环,不建议用:
b = { '204':'haa', 1:3, 2:4 } for k in b: print(k,b[k])#建议用 for k,v in b.items():#不建议用 print(k,v)
以上内容包含了字典中所以函数方法,包括增删改查循环还有多级字典等,大家可以把代码拷贝到自己的编译器中运行以下即可明白
集合
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合常识:
1 #!/usr/bin/env.python 2 # -*- coding: utf-8 -*- 3 """ 4 ------------------------------------------------- 5 File Name: 集合 6 Description : 7 Author : lym 8 date: 2018/3/5 9 ------------------------------------------------- 10 Change Activity: 11 2018/3/5: 12 ------------------------------------------------- 13 """ 14 __author__ = 'lym' 15 #集合也是无序的 16 list_1 = [1,4,6,8,6,9,2,3,4] 17 #变成集合 set 数据类型是集合<class 'set'> 18 list_1 = set(list_1) 19 20 print(list_1,type(list_1)) 21 22 list_2 = set([2,6,88,0,6,7,3]) 23 print(list_1,list_2) 24 25 #list_1.intersection(list_2)--交集 26 print(list_1.intersection(list_2)) 27 28 #list_1.union(list_2)--并集 29 print(list_1.union(list_2)) 30 31 #list_1.difference(list_2)--差集 = 1里有的2里没有的 32 print(list_1.difference(list_2)) 33 #list_2.difference(list_1)--差集 = 2里有的1里没有的 34 print(list_2.difference(list_1)) 35 36 # 37 list_3 = set([2,3,6]) 38 print(list_3.issubset(list_2)) 39 print(list_1.issuperset(list_3)) 40 41 #对称差集,将两个集合中互相没有的取出=把交集去掉 42 print(list_1.symmetric_difference(list_2)) 43 44 print("这是一条分割线".center(50,'-')) 45 46 list_4 = set([1,5,7]) 47 print(list_3.isdisjoint(list_4))#3与4是否有交集,若有为True,若无为False
其他知识:
s = set([3,5,9,10]) #创建一个数值集合 t = set("Hello") #创建一个唯一字符的集合 a = t | s # t 和 s的并集 b = t & s # t 和 s的交集 c = t – s # 求差集(项在t中,但不在s中) d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 基本操作: t.add('x') # 添加一项 s.update([10,37,42]) # 在s中添加多项 使用remove()可以删除一项: t.remove('H') len(s) set 的长度 x in s 测试 x 是否是 s 的成员 x not in s 测试 x 是否不是 s 的成员 s.issubset(t) s <= t 测试是否 s 中的每一个元素都在 t 中 s.issuperset(t) s >= t 测试是否 t 中的每一个元素都在 s 中 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 s.copy() 返回 set “s”的一个浅复制
运用上方的知识,利用运算符将集合常识中代码简化:
1 #!/usr/bin/env.python 2 # -*- coding: utf-8 -*- 3 """ 4 ------------------------------------------------- 5 File Name: 集合简化 6 Description : 7 Author : lym 8 date: 2018/3/5 9 ------------------------------------------------- 10 Change Activity: 11 2018/3/5: 12 ------------------------------------------------- 13 """ 14 __author__ = 'lym' 15 16 list_1 = set([1,4,6,8,6,9,2,3,46]) 17 list_2 = set([2,6,88,0,6,7,3]) 18 print(list_1) 19 print(list_2) 20 21 #交集 22 print(list_1 & list_2) 23 #并集 24 print(list_1 | list_2) 25 #差集 26 print(list_1 - list_2)#在1不在2 27 print(list_2 - list_1)#在2不在1 28 #对称差集 29 print(list_1 ^ list_2) 30 31 print("这是一条分割线".center(50,'-')) 32 33 #添加一项 34 list_1.add(666) 35 print(list_1) 36 #添加多项 37 list_1.update([68,89,99]) 38 print(list_1) 39 #删除 40 print(list_1.pop()) 41 list_1.remove(46)#删除一项 42 print(list_1)
以上就是本讲的全部内容
欢迎大家多多交流
- QQ:616581760
- weibo:https://weibo.com/3010316791/profile?rightmod=1&wvr=6&mod=personinfo
- zcool:http://www.zcool.com.cn/u/16265217
- huke:https://huke88.com/teacher/17655.html
如果,您希望更容易地发现我的新博客,不妨点击一下绿色通道的【关注我】。
我的写作热情离不开您的肯定支持,感谢您的阅读,我是【YMLiang】!
我的个人博客:https://ymliang.netlify.com
QQ:616581760
邮箱:616581760@qq.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号