

flinkSQL总结
-
进入sql客户端
./sql-client.sh -
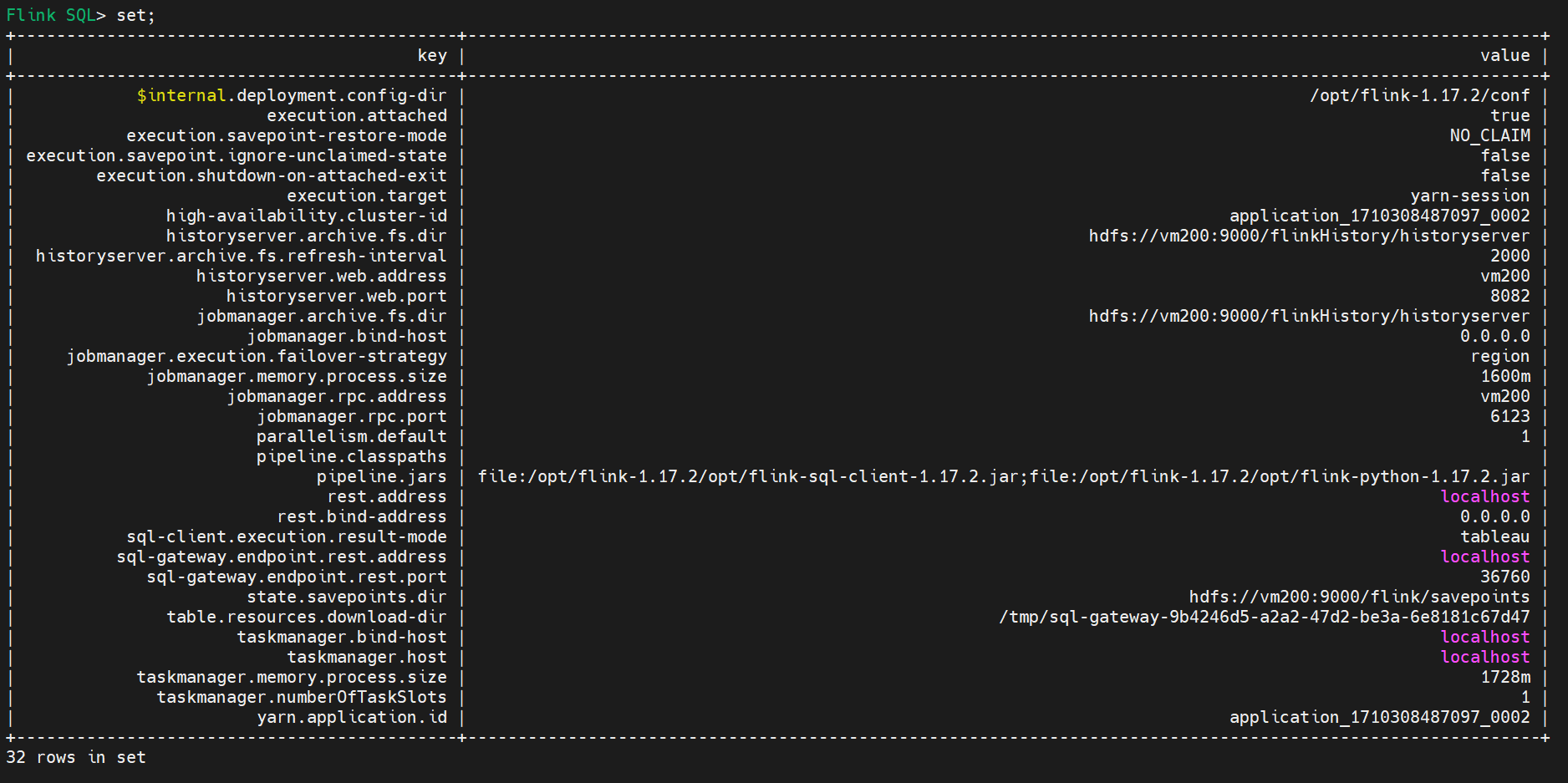
查看有哪些设置
set;
set;显示的设置不全
![image-20240313153211677]()
-
几种常见的设置
#默认: table,能设为 : tableau、changelog SET sql-client.execution.result-mode=tableau; # 执行环境 # 默认: streaming, 或 batch SET execution.runtime-mode=streaming; # 默认并行度 SET parallelism.default=1; # 设置状态TTL SET table.exec.state.ttl=1000; -
启动sql客户端的时候使用初始化脚本
vi ../conf/sql-client-init.sql
写入初始化脚本SET sql-client.execution.result-mode=tableau; CREATE DATABASE mydb;使用初始化脚本启动
./sql-client.sh embedded -s yarn-session -i ../conf/sql-client-init.sqlembedded:内嵌模式
-s yarn-session:指定运行模式
-i ../conf/sql-client-init.sql:指定初始化配置文件 -
flink 是一个分布式计算引擎,flink sql只是映射 sql 为分布式计算任务的工具
flink sql 不保存数据,数据需要通过连接器器去外部读取
保存映射关系需要有地方保存映射关系的元元数据,flink 没有类似hive metastore的东西,所以flink 不会保存创建的表结构,如果要保持包结构,可以把创建表的sql 写到 初始化脚本里面,以此到达类似元数据持久化的效果。 -
flink sql 支持的类型
默认支持的数据类型
Data Type Remarks for Data Type CHARVARCHARSTRINGBOOLEANBINARYVARBINARYBYTESDECIMALSupports fixed precision and scale. TINYINTSMALLINTINTEGERBIGINTFLOATDOUBLEDATETIMESupports only a precision of 0.TIMESTAMPTIMESTAMP_LTZINTERVALSupports only interval of MONTHandSECOND(3).ARRAYMULTISETMAPROWRAWStructured types Only exposed in user-defined functions yet. -
创建表
flink的表就是一份数据上的映射,创建表定义的映射关系,查询被翻译成执行的流处理job。
sink表是输出数据的映射,不能查询只能插入数据。--数据表 create table source( id bigint, action int, action_time TIMESTAMP, user_id bigint, val varchar(255) ) with( 'connector' = 'datagen', 'rows-per-second'='1', 'fields.id.kind'='sequence', 'fields.id.start'='1', 'fields.id.end'='10000', 'fields.action.kind'='random', 'fields.action.min'='1', 'fields.action.max'='10', 'fields.action_time.kind'='random', 'fields.action_time.max-past'='100', 'fields.user_id.kind'='random', 'fields.user_id.min'='1', 'fields.user_id.max'='20', 'fields.val.kind'='random', 'fields.val.length'='6' ); --数据表 create table source( id bigint, action int, action_time TIMESTAMP, user_id bigint, val varchar(255), --指定主键,并且主键必须是非强制 primary key(id) NOT enforced ) with( 'connector' = 'datagen', 'rows-per-second'='1', 'fields.id.kind'='sequence', 'fields.id.start'='1', 'fields.id.end'='10000', 'fields.action.kind'='random', 'fields.action.min'='1', 'fields.action.max'='10', 'fields.action_time.kind'='random', 'fields.action_time.max-past'='100', 'fields.user_id.kind'='random', 'fields.user_id.min'='1', 'fields.user_id.max'='20', 'fields.val.kind'='random', 'fields.val.length'='6' ); -- sink 到控制台的表 create table print( id bigint, action int, action_time TIMESTAMP, user_id bigint, val varchar(255) ) with( 'connector' = 'print' ); -
每个查询就是一个flink job
--查询一个表会生成一个job select * from source;查询结果
![image-20240314103619837]()
生成的job
![image-20240314103543781]()
-
sink表不能查询,只能插入
--sink表是不能查询的,查询会报错 select * from print; --sink表只能用于插入数据(输出数据) insert into print select * from source;查询sink表保存信息
#输出结果 Flink SQL> select * from print; [ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.ValidationException: Connector 'print' can only be used as a sink. It cannot be used as a source. -
从固定数据源查询


--用现有数据创建表,而不是连接器
select id,name from (
values (1,'张三'),
(2,'李四'),
(3,'王五')
)as `user`(id,name);
-
类型装换
cast(原数据字段 as 目标类型)--通用输出表5字段 create table sink5( a string, b string, c string, d string, e string ) with( 'connector' = 'print' ); --输出到指定指定表 --把Id转换成string 类型,并且加了3个孔字段和输出表对其 insert into sink5 select cast(id as String),name,'' as c,'' as d,'' as e from ( values (1,'张三'), (2,'李四'), (3,'王五') )as `user`(id,name); -
使用当前时间
current_timestamp--使用当前时间 select id,name,current_timestamp as `time` from ( values (1,'张三'), (2,'李四'), (3,'王五') )as `user`(id,name);时间格式化
SELECT DATE_FORMAT(date_time_col, 'yyyy-MM-dd HH:mm:ss') FROM table_name; -
时间字段
current_timestamp获取当前时间,current_timestamp类型是timestamp_ltz(3)时间精度是毫秒,是带有本地时区的timestamp(3)
timestamp(3)是精确到毫秒,格式滑以后显示为:2024-03-13 23:47:50.058
timestamp是精确到纳秒,格式化后显示为:2024-03-14 03:47:14.518000可以使用current_timestamp 作为事件字段默认值 ,时间转化 as cast(current_timestamp as timestamp(3))
--水位线 create table source4( id bigint, --作为事件时间的字段必须是timestamp(3),timestamp(0),timestamp_ltz(3),timestamp_ltz(0) action_time as cast(current_timestamp as timestamp(3)), --设置水位线,使用了action_time字段作为事件时间 watermark for action_time as action_time- interval '5' second ) ... -
查询去重
distinctselect distinct id id_distinct,* from r3; -
group by
flink sql 对group要求严格,除了聚合函数以外,查询字段必须全部出现在group by 后面。select `action`,count(*) from source_fs group by `action`; -
order by 排序只能使用时间字段开头,并且只能升序排序(流模式的情况下)
#时间字段倒序排序,异常如下 select * from source order by action_time desc; [ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.TableException: Sort on a non-time-attribute field is not supported. -
with使用连接器,有哪些属性怎么生成?
具体去官方文旦查看![image-20240314112514398]()
这里以datagen连接器的官方文档的例子
datagen连接器写法
CREATE TABLE datagen ( f_sequence INT, f_random INT, f_random_str STRING, ts AS localtimestamp, WATERMARK FOR ts AS ts ) WITH ( 'connector' = 'datagen', -- optional options -- 'rows-per-second'='5', 'fields.f_sequence.kind'='sequence', 'fields.f_sequence.start'='1', 'fields.f_sequence.end'='1000', 'fields.f_random.min'='1', 'fields.f_random.max'='1000', 'fields.f_random_str.length'='10' )datagen连接器参数
fields.#.max-past的时间单位默认是毫秒
参数 是否必选 默认值 数据类型 描述 connector 必须 (none) String 指定要使用的连接器,这里是 'datagen'。 rows-per-second 可选 10000 Long 每秒生成的行数,用以控制数据发出速率。 fields.#.kind 可选 random String 指定 '#' 字段的生成器。可以是 'sequence' 或 'random'。 fields.#.min 可选 (Minimum value of type) (Type of field) 随机生成器的最小值,适用于数字类型。 fields.#.max 可选 (Maximum value of type) (Type of field) 随机生成器的最大值,适用于数字类型。 fields.#.max-past 可选 0 Duration 随机生成器生成相对当前时间向过去偏移的最大值,适用于 timestamp 类型。 fields.#.length 可选 100 Integer 随机生成器生成字符的长度,适用于 char、varchar、binary、varbinary、string。 fields.#.start 可选 (none) (Type of field) 序列生成器的起始值。 fields.#.end 可选 (none) (Type of field) 序列生成器的结束值。 -
使用文件系统连接器
--文件系统连接器 create table source_fs( id bigint, action string, action_time timestamp(3), user_id bigint, val varchar(255), watermark for action_time as action_time - interval '5' second ) with( 'connector' = 'filesystem', --位于hdfs上csv文件地址 'path' = 'hdfs://vm200:9000/flink/table/fs-table.csv', 'format' = 'csv' );csv文件地址
地址:hdfs://vm200:9000/flink/table/fs-table.csv1,add,2024-03-14 11:11:11,1,val1 2,add,2024-03-15 11:11:11,2,val2 3,add,2024-03-14 11:11:12,3,val3 4,add,2024-03-15 11:11:12,4,val4 5,add,2024-03-14 11:11:13,5,val5 6,add,2024-03-15 11:11:13,6,val6 7,add,2024-03-14 11:11:14,6,val7 8,add,2024-03-15 11:11:14,7,val8 9,delete,2024-03-14 11:11:15,1,val9 10,delete,2024-03-15 11:11:15,2,val10 11,delete,2024-03-14 11:11:16,4,val11 12,delete,2024-03-15 11:11:16,4,val12 13,delete,2024-03-14 11:11:17,3,val13 14,delete,2024-03-15 11:11:17,5,val14 15,delete,2024-03-14 11:11:18,1,val15 16,update,2024-03-15 11:11:18,6,val16 17,update,2024-03-14 11:11:19,1,val17 18,update,2024-03-15 11:11:19,3,val18 19,update,2024-03-14 11:11:20,1,val19 20,update,2024-03-15 11:11:20,2,val20 -
使用连接器的元属性
元数据字段名 字段类型 metadata
字段名 字段类型 metadata from 元数据字段名virtual表示只读
--使用元数据 create table source_fs2( id bigint, action string, action_time timestamp(3), user_id bigint, val varchar(255), --使用文件路径元数据(同名字段) `file.path` STRING NOT NULL metadata, watermark for action_time as action_time - interval '5' second ) with( 'connector' = 'filesystem', 'path' = 'hdfs://vm200:9000/flink/table/fs-table.csv', 'format' = 'csv' ); --使用元数据 create table source_fs4( id bigint, action string, action_time timestamp(3), user_id bigint, val varchar(255), --使用文件路径元数据(不同名字段) `filePath` string metadata from 'file.path' virtual, watermark for action_time as action_time - interval '5' second ) with( 'connector' = 'filesystem', 'path' = 'hdfs://vm200:9000/flink/table/fs-table.csv', 'format' = 'csv' ); -
设置水位线
格式: watermark for 事件时间字段 as 事件时间字段 - interval 'n' second
事件时间类型限制: TIMESTAMP(p) or TIMESTAMP_LTZ(p), the supported precision 'p' is from 0 to 3
--创建表设置水位线为随机生成 create table source3( id bigint, action int, --作为事件时间的字段必须是timestamp(3) action_time timestamp(3), user_id bigint, val varchar(255), --设置水位线,使用了action_time字段作为事件时间 watermark for action_time as action_time - interval '5' second ) with( 'connector' = 'datagen', 'rows-per-second'='1', 'fields.id.kind'='sequence', 'fields.id.start'='1', 'fields.id.end'='10000', 'fields.action.kind'='random', 'fields.action.min'='1', 'fields.action.max'='10', --事件时间字段随机生成,当前时间随机慢5000毫秒以内 'fields.action_time.kind'='random', 'fields.action_time.max-past'='5000', 'fields.user_id.kind'='random', 'fields.user_id.min'='1', 'fields.user_id.max'='20', l 'fields.val.kind'='random', 'fields.val.length'='6' ); --创建表设置水位线为当前时间 create table source4( id bigint, action int, --使用当前时间 action_time as current_timestamp, user_id bigint, val varchar(255), --设置水位线,使用了action_time字段作为事件时间 watermark for action_time as action_time- interval '5' second ) with( 'connector' = 'datagen', 'rows-per-second'='1', 'fields.id.kind'='sequence', 'fields.id.start'='1', 'fields.id.end'='10000', 'fields.action.kind'='random', 'fields.action.min'='1', 'fields.action.max'='10', 'fields.user_id.kind'='random', 'fields.user_id.min'='1', 'fields.user_id.max'='20', 'fields.val.kind'='random', 'fields.val.length'='6' ); -
窗口(1.13前语法)
老的窗口函数式把窗口当做一个特殊字段来用--窗口老语法(滚动) select tumble_start(action_time, interval '10' second ),tumble_end(action_time, interval '10' second ) from source group by tumble( action_time , interval '10' second ); --窗口老语法(滑动) select hop_start(action_time, interval '5' second , interval '10' second ),hop_end(action_time, interval '5' second , interval '10' second ) from source group by hop( action_time, interval '5' second , interval '10' second ); --窗口老语法(session) select id, session_start(action_time, interval '10' second ) from source group by id, session( action_time, interval '10' second ); -
窗口1.13后建议使用TVF(table value function) 表值函数
新的TVF是把窗口当做一个表来用-- 滚动窗口 select * from table( tumble( --表名 table source, --事件时间字段名 descriptor(action_time), --窗口时长 interval '10' second ) ); --滑动窗口 select * from table( hop( --表名 table source, --事件时间字段名 descriptor(action_time), --窗口滑动步长 interval '5' second, --窗口时长 interval '10' second ) ); --积累窗口(特殊的滑动窗口,滑动步长必须是窗口长度的整数倍) select * from table( cumulate( --表名 table source, --事件时间字段名 descriptor(action_time), --窗口滑动步长 interval '5' second, --窗口时长 interval '10' second ) ); -
分窗以后,窗口内部求聚合
--窗口内按照action分组,然后统计 数量 select action,count(id) from table( tumble( table source, descriptor(action_time), interval '10' second ) ) group by action; --全窗口一起统计数量,最大值等 select window_start,window_end,count(id),max(id) from table( tumble( table source, descriptor(action_time), interval '10' second ) ) group by window_start,window_end; ); -
group sets,一次得到多种分组维度的统计结果
下面的结果4个分组维度,没来一条就统计一次4个维度的结果。- 所有一组
- 按照action分组
- 按照user_id分组
- 按照action和user_id分组
--grouping sets select action,user_id,count(*) from source group by grouping sets( (), (action), (user_id), (user_id,action) ); -
获取窗口时间
--获取窗口起始时间 select window_start,window_end from table( hop(table source,descriptor(action_time),interval '5' second,interval '10' second) ); -
over
开窗相当于在每行的基础上,计算当前行和前后关联数据的关系
分区不是必须的,排序是必须的
分区内必须排序,排序字段只能是时间字段,并且升序
range是时间窗口,rows是计数窗口
开窗从句格式:range/rows between 间隔 preceding and current row,间隔可以是时间,可以是数字,可以是unbounded开窗从句的上边界只能是 current row(当前行)
开窗从句默认值:unbounded preceding and current row--开窗函数(时间开窗) select *,count(user_id) over( partition by action order by action_time range between interval '5' second preceding and current row ) as num from source; --开窗函数(数量开窗) select *,count(user_id) over( partition by action order by action_time rows between 5 preceding and current row ) as num from source; --开窗函数可以独立定义 select *,count(user_id) over w1 as num,max(id) over w1 as m from source window w1 as( partition by action order by action_time rows between 5 preceding and current row ); -
flink over 开窗函数和 TVF 的窗口函数的区别
- 两者本质上都对数据的分区,然后进行区内数据的计算
- over是按照字段分区同一分区的数据是不连续的,TVF的窗口把一段连续的数据数据划为一个区,一定时间内,或者连续多少个。
-
执行模式
一般设置成流模式,如果设置成批模式不能用无界流查询。# 执行环境 # 默认: streaming, 或 batch SET execution.runtime-mode=streaming;当设置成流模式的时候有些有界流处理结果和预期不一样
流模式结果下的开窗结果和批模式的开机结果相比,前面少了几条?
待确认....批模式结果没用指定了水位线的表
-
flinksql 查询记录 op列 +I -U +U -D解释
- +I 是新增的一行记录
- -U 是回撤一条数据
- +U是添加了一条数据(在回撤的基础上新增了一条数据),-U和+U两条 合起来就是一次更新
- -D 是删除了数据
-
使用 row_number() over 实现topN
-- topN select * from (select row_number() over( partition by action order by action_time ) as rownum,* from source ) where rownum <=5; -- topN 的开窗排序字段可以是非时间字段,并且可以倒叙 select * from (select row_number() over( partition by action order by user_id desc ) as rownum,* from source ) where rownum <=5; -
top1等于去重
--top1可以的效果等于去重 select * from (select row_number() over( partition by action order by user_id desc ) as rownum,* from source ) where rownum = 1; -
join
join依赖状态的保存,如果不设置 ttl很可能保存的状态超出内存限制,但是如果设置的ttl太短 会导致结果不精确。-
join
如果设置了不续期的TTL 10秒,那么就相等10秒的滚动窗口join--join select * from source t1 join source_fs t2 on t1.id = t2.id; --left join select * from source t1 left join source_fs t2 on t1.action = t2.action; --right join select * from source t1 right join source_fs t2 on t1.action = t2.action; --outer join select * from source t1 full outer join source_fs t2 on t1.action = t2.action; --多字段关联join select * from source t1 ,source t2 where t1.id = t1.id and t1.action_time = t2.action_time; -
间隔join
--间隔join1,和多字段等值条件的join类似 select * from source t1 ,source t2 where t1.id = t1.id and t1.action_time = t2.action_time; --间隔join2,id相等, t2.action_time<t1.action_time<t2.action_time+10s select * from source t1 ,source t2 where t1.id = t1.id and t1.action_time > t2.action_time and t1.action_time < t2.action_time + interval '10' second; --间隔join2,t2.action_time<t1.action_time<t2.action_time+10s select * from source t1 ,source t2 where t1.id = t1.id and t1.action_time between t2.action_time and t2.action_time + interval '10' second; -
lookup 查询
效果是 通过左表里面右表的主键Id,去查询数据关联
需要右表有主键,并且右表的主键和左表关联。
要求时间字段类型一样
语法 join table for system_time as of 左表时间字段-- look up join select * from source join source_fs for system_time as of source.action_time on source.id = source_fs.id;
-
-
hint 可以在本次sql中临时修改连接器属性
sql/*+ OPTIONS('属性key'='属性值') */select * from source/*+ OPTIONS('rows-per-second'='10') */; -
并集 交集 差集 in 子查询
-- unoin(取重复) select * from source_fs t1 union select *from source_fs t2; -- unoin all(不去重复) select * from source_fs t1 union all select *from source_fs t2; -- 交集(去重复) select * from source_fs t1 intersect select * from source_fs t2; -- 交集(不去重复) select * from source_fs t1 intersect all select *from source_fs t2; -- 差集(去重复) select * from source_fs t1 except select *from source_fs t2; -- 差集(不去重复) select * from source_fs t1 except all select *from source_fs t2; -
flink字符串拼接使用的 ||
select *, 'a'||'b' from source_fs; -
其他系统函数
列出可用函数列表 show functions;具体用法,可以查官方文档
![image-20240315182312638]()
-
使用模块hive
去flink官网下载对应版本的hive连接器jar包(flink-sql-connector-hive-3.1.3_2.12-1.17.2.jar),然后放到flink的lib目录下面
重启flink,然后加载hive#加载hive模块,名字是hive,版本是3.1.3 load module hive with('hive-version'='3.1.3'); #卸载hive模块 unload hive;-- 查看启用的模块 show modules; -- 查看所有模块 show full modules;加载hive模块以后就能使用hive的函数了select split('a-b','-'); flink 没有 solit 函数。
有的flink版本需要hadoop-mapreduce-client-core.jar才能加载hive,hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.6.jar 到flink的lib目录下(添加jar以后需要重启flink)。实测1.17.2没有这个问题。
-
导入hive 连接器jar包以后,文件系统连接器使用异常问题
hive连接器的jar包用的老版本的 planner,老版本的planner位于flink/opt/flink-table-planner_2.12-1.17.2.jar
用flink/opt/flink-table-planner_2.12-1.17.2.jar 替换 flink/lib/flink-table-planner-loader-1.17.2.jar,然后重启flink
-
读取kafka数据,和fixed分区器
kafkaCREATE TABLE t1( `event_time` TIMESTAMP(3) METADATA FROM 'timestamp', --列名和元数据名一致可以省略 FROM 'xxxx', VIRTUAL 表示只读 `partition` BIGINT METADATA VIRTUAL, `offset` BIGINT METADATA VIRTUAL, id int, ts bigint , vc int ) WITH ( 'connector' = 'kafka', 'properties.bootstrap.servers' = 'hadoop103:9092', 'properties.group.id' = 'atguigu', -- 'earliest-offset', 'latest-offset', 'group-offsets', 'timestamp' and 'specific-offsets' 'scan.startup.mode' = 'earliest-offset', -- fixed 为flink 实现的分区器,一个并行度只写往kafka 一个分区 'sink.partitioner' = 'fixed', 'topic' = 'ws1', 'format' = 'json' ) -
kafka upsert 流, kafka-upsert 才能插入数据
'connector' = 'upsert-kafka', -
mysql连接器
需要导入连接器驱动mysql-connector-java.jar和mysql驱动包
如果有主键就会一upset方式自动添加或者修改数据,如果没有主键,就只会添加新数据,所以一般都要有主键
也就是说有主键以后插入一条同id 的数据,效果是更新,没有主键会在flink的 任务里面报错,flink sql 客户端不会报错。--连接器mysql create table `user`( id bigint, action string, action_time timestamp(3), user_id bigint, val varchar(255), primary key(id) not enforced, watermark for action_time as action_time - interval '5' second ) with( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://192.168.100.66:3306/hl', 'table-name' = 'user', 'username' = 'root', 'password' = 'root' ); --插入 insert into `user`(id,action,action_time,user_id,val) values(1,'add',TO_TIMESTAMP('2024-03-15 11:11:11'),1,'val1'); --mysql中的建表语句 CREATE TABLE `user` ( `id` bigint(0) NOT NULL, `action` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, `action_time` datetime(0) NULL DEFAULT NULL, `user_id` bigint(0) NULL DEFAULT NULL, `val` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;mysql连接器目前是不支持update 操作的,只能查询和插入,通过upset更新。
Flink SQL> update `user` set action = 'update' where id =1; [ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.TableException: UPDATE statement is not supported for streaming mode now. Flink SQL> delete from `user` where id = 1; [ERROR] Could not execute SQL statement. Reason: org.apache.flink.table.api.TableException: DELETE statement is not supported for streaming mode now. -
查看fink作业列表
show jobsFlink SQL> show jobs +----------------------------------+---------------------------------------------------+----------+-------------------------+ | job id | job name | status | start time | +----------------------------------+---------------------------------------------------+----------+-------------------------+ | 5dd39a4c0438c56d301746052a6e6f80 | insert-into_default_catalog.default_database.sink | RUNNING | 2024-03-13T08:07:47.326 | | ffe15de5bd70b584d496402fcdbd3e0d | collect | CANCELED | 2024-03-13T09:30:56.385 | | f90e22af4fd557ea597f75add358aff8 | insert-into_default_catalog.mydb.sink_table | RUNNING | 2024-03-13T08:50:37.762 | | 2f49985e92615b934436dd1e4825515b | collect | CANCELED | 2024-03-13T09:31:18.168 | | 8f5cd2597bc2c2f122bee3576b4bf869 | insert-into_default_catalog.mydb.sink_table | RUNNING | 2024-03-13T08:55:30.906 | | 4461f799a00107f4f8fc070708068205 | collect | CANCELED | 2024-03-13T09:32:29.566 | | e4bc1d83f6c2ddb8f0d05bcee5a4f223 | collect | FINISHED | 2024-03-13T09:33:14.391 | | 7b7125b0c166f55ede9ef274c8ee5e99 | collect | CANCELED | 2024-03-13T09:28:15.859 | | 5cde4597b763417686e033cbfdbd1c67 | collect | CANCELED | 2024-03-13T09:29:28.039 | +----------------------------------+---------------------------------------------------+----------+-------------------------+ 9 rows in set -
创建保存点和从保存点恢复
-- 建立保存点 stop job '038ecadc25a01448a6c886bb1197d848' with savepoint; -- 设置状态保存目录(如果没有配置默认保存点目录) set state.savepoints.dir='hdfs://vm200:9000/flinkHistory/state'; -- 设置从savepoint 恢复的路径,后面执行的所有sql会使用这个保存点,所以用了以后要及时reset SET execution.savepoint.path='hdfs://vm200:9000/flinkHistory/state/savepoint-038eca-113feb01a577'; -- 去掉sql使用保存点 RESET execution.savepoint.path; -- 允许跳过无法还原的保存点状态 set 'execution.savepoint.ignore-unclaimed-state' = 'true'; -
catalog介绍
catalog是数据库之上的一层是一个目录,目的是打通flink和外部数据的映射,不需要我们一张表一张表的映射,直接就能查询catalog 目前支持hive和jdbc(mysql和postgresql)
我们可以通过 catalog名字.database名字.table名字,使用别的catalog下面的表,可以查询可以连接。
我们可以在初始化sql中映射catalog,然后就能直接使用外部数据库的表了。catalog和数据库的操作
-- 查看catalog show catalogs; -- 查看当前的CATALOG show current catalog; -- 使用指定catalog use catalog xxx; -- 查看当前catalog下面有哪些数据库 show databases; -- 查看当前默认使用的数据库 show current database; -- 使用指定数据库 use hl; -- 查询别的catalog下面的数据 select * from default_catalog.default_database.source; -
使用catalog映射 mysql,是只读的,不能建表
create catalog mysql_hl WITH( 'type' = 'jdbc', 'default-database' = 'hl', 'username' = 'root', 'password' = 'root', 'base-url' = 'jdbc:mysql://192.168.100.66:3306' ); -
使用catalog 链接 hive,这是创建表和读取数据的,并且这里创建的表是可以持久化到hive里面,但是catalog不能持久化,需要每次使用初始化脚本创建
甚至可以在 hive 的catalog 里面创建映射到mysql的表,并且它也是可以持久化的。CREATE CATALOG myhive WITH ( 'type' = 'hive', 'default-database' = 'default', 'hive-conf-dir' = '/opt/apache-hive-3.1.3-bin/conf' );flink 是连接到 hive 的metastore上读取数据的
-
在Java代码中使用flink sql
依赖这里的依赖是一个 Java 的“桥接器”(bridge),主要就是负责 Table API 和下层DataStream API 的连接支持,按照不同的语言分为 Java 版和 Scala 版。 <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge</artifactId> <version>${flink.version}</version> </dependency> 如果我们希望在本地的集成开发环境(IDE)里运行 Table API 和 SQL,还需要引入以下依赖: <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-loader</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-runtime</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-files</artifactId> <version>${flink.version}</version> </dependency> -
自定义函数
标量函数表函数
聚合函数
表聚合函数

能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2024-03-13 21:32 zhangyukun 阅读(1357) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号