架构杂记(2)
-
每次JVM启动以后都是单独虚拟的一块内存空间,所以程序第一次打印 System.out.println( new Object() );的结果是一样,不管运行多少次,如果不干别的事,第二次,第三次答应,也分别可另一一次启动的JVM结果一样。我们说的hash是内存地址,是Java虚拟的内存的地址。
-
Java程序执行的过程编译-->加载-->解释-->分配内存-->执行命令,Java文件编译成为class字节码文件,通过classLoader加载到内存,然后有解释器解释成汇编码,汇编码被计算机翻译成为机器码。解释执行是一行一行的读,即时编译预先解释病缓存热点代码,缓存在堆外缓存codeCache中,大约占有20%。
-
一个请求占用多少带宽?一个1Mb的带宽可以支撑多少请求?一个Long是8个byte,用字符形式表示是19个byte(为了避免js上面的丢失精度,一般吧Long单做Spring处理),算上key和结构数,按照30算。假设一个响应有10个响应头,响应体里面20个字段的json 数据。这一个响应就是900byte,约1KB。实际过程中,也有响应体体远小于20字段的,也有表数据这种,远大于1KB的,更具实际情况,大多数一般都在0.5KB-10Kb的之间。按照1KB算,1Mb的带宽实际最大下载速度是128KB/s,也就是说1Mb的带框约可以撑起 128个响应。10Mb可以支撑1280个请求,100Mb可以支撑12800请求/s.如果按照5KB算100Mb的带宽可以支撑2560个请求的并发。请求比响应速度低的多,所以我们一般只考虑响应带宽。也就是100W并发,起码需要万兆光纤才行。
-
redis 的 每秒10W次读写的单机速度是有前提的,要带宽足够,假设我们读写的对象平均20个字段,字段名字+字段的值25字节,一个对象也就是0.5K,10W个对象,0.5*100000/1024x8=390.625兆的带宽(带宽计算单位不是 Byte 子字节,所以要乘8)。所以在在ECS之类的云服务器上的redis不可能达到这个效率,另外10W每秒是redis 官方说的,可能有些水分,如果官方说的没有水分,带宽不够400M是理论上都行不通。
-
redis 如果处理太多的大值,可能会造成内存负载倾斜,也可能会触发缓存回收,大大的频繁的loadDB,导致系统性能降低,甚至雪崩,所以不要大量的在redis中存大值对象。
-
本地缓存能有效的减少redis全局缓存的压力,本地缓存可以是EHcache,并且redis6 客户端默认就自带了本地缓存,通过事件监听可以很方便的实现本地缓存和redis全局缓存的一致性。
-
rdb_bigkeys 这个 GO语言写的工具可以很方便的帮我查找RDB文件中是否有大Key。
-
Oauth2.0授权码模式的过程
客户端请求资源(请求类型是code,带上回调地址,权限范围)-->授权服务器放回是否同意授权的页面-->客户点击同意(如果权限范围很小可能不需要用户确认直接默认同意)-->授权服务器放回从顶下请求到前面参数带有的重定向地址并且参数带上授权码-->重定向地址一般是三方服务器端,也可能是三方前端页面,然后三方服务器端拿到授权码向授权服务器请求token-->授权服务器放回token-->用token请求向资源服务器请求资源 -
OAuth2.0 最复杂的是授权码模式(最安全适合三方应用),然后有简化模式(直接获取token,不通过授权码,这个模式我不知道用在什么情况,而且它不需要秘钥),还有用户名密码模式(适合前端是我们自己的才安全)和客户端认证方式(适合内部服务之间完全信任)。
-
TIDB 一个时间顺序的数据库,在特定场景可以考虑使用。
-
skywalking 是 基于 java agent 的 APM 监控软件,用它可以接受用java应用上报的信息,并以图表的方式展示,能轻松的看到拓扑图,jvm情况,链路追踪等等信息。
-
一致性哈希(哈希环),是分布式扩容的常见用法。原理就是按照节点数把哈希环分出若干个圆弧,只要哈希模运算的值落在这个圆弧内,就存储到对应的服务器。扩容的时候针对对应的圆弧扩容就行,大部分数据依旧是可以访问的。我们只要有个映射表管理着物理服务器和虚拟哈希环上的范围区间就可以了。
-
SOA 面向服务架构,早期是各服务之间通过 ESB( 企业服务总线来)来完成通信的,企业服务器中线充当了服务注册中心,和请求请求格式转换器的的角色。现在的微服务架构师通过注册中心和并且统一传输格式来代替(JSON)。ESB容易被ESB服务提供商绑架,并且很贵,一般小公司用不起,大公司不削用。
-
服务化,可以看出2个阶段,第一是横向拆分,主要针对单体架构,第二是纵向拆分,纵向拆分也就是分布式架构了,基于ESB的分布式架构和分布式微服务架构是分布式架构的解决方案。
-
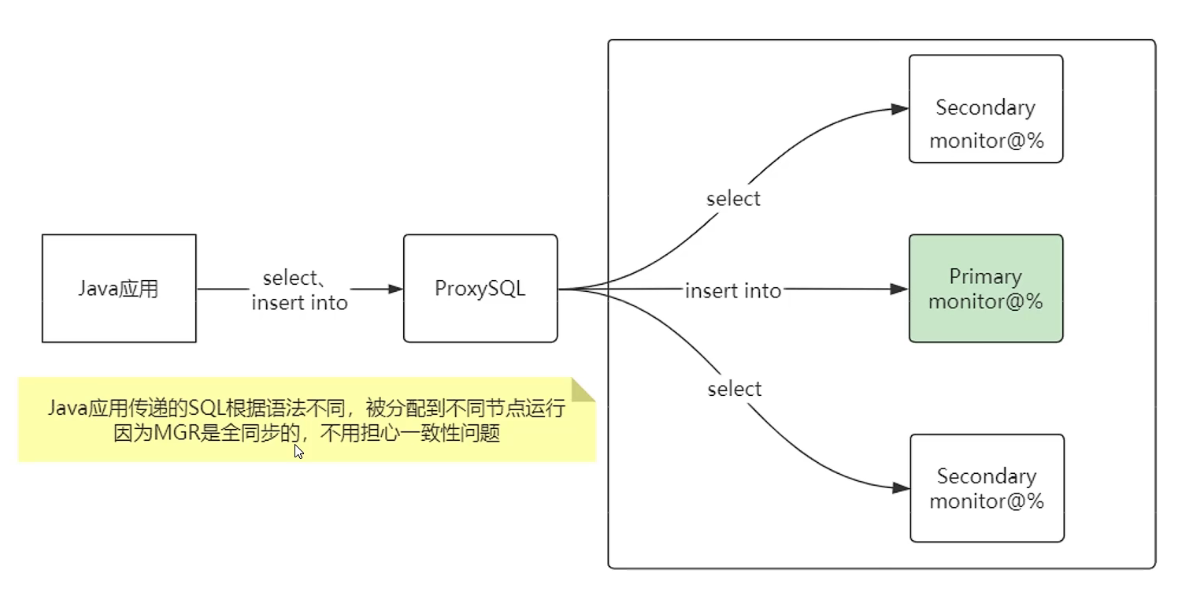
proxySQL和MGR配合使用,可以方便的识别MGR的那个节点是主,那个是从。
识别的过程是查询一个关于当前节点是否是readOnly的视图。并且通过 发送简单查询语句判断节点是否活着,能对宕机的节点自动剔除。
![]()
-
网络分区(脑裂)以后,单主集群出现了多主,怎么解决?
-
看集群的做法,有些集群的做法是降级的节点,不会在加入节点变成从,那么我们可以通过比对数据,把没有同步的部分写入集群,然后把它改成从。
-
如果集群做法是老主自动降级位从,并且同步当前新主的数据,那么我们只能通过历史日志,或者老主的数据备份来恢复数据了。
-
可以设置对外提供服务的集群数量是超过一半才提供写服务,否则只提供读服务,这时候网络分区以后,节点少的那个集群的主节点是不能继续写入的。
-
-
CAP 三选2,实际是网络分区的时候CA只能二选一,P网络分区,不是一个结果,是一个条件,不是说解决了网络分区,而是会不会有网络分区的问题。分布式集群一定会有网络分区的可能,单体架构不会有网络分区的可能,这是条件,CA 一个是 强一致性,强调的结果,A 是可用性,强调结果。所以CAP,说的是在网络分区的前提下,在一定时间内强一致性的处理完并且返回不是一定可以确保的。
-
BASE 描述的 是两个选择
-
BA 是描述的CP模式下,对可用性的处理,要在保证强一致性的前提上,让系统基本可用,如果一定时间内等不到数据同步,超过一定时间,就应该给用户一定的提示,而不是让用户在哪里死等。
-
SE 是描述 AP模式下,对于一致性的处理,一定时间内做不到完成的同步,但是我们可以把主线做了,支线依赖系统最终一致性慢慢完成,这时候出现一些或多或少的中间状态也就成了必然的结果。
-
-
ACID
-
A 是原则性 想要达到C效果的一个条件
-
C 一致性 强调结果
-
I 隔离性 想要达到C效果的一个条件
-
D 持久性 想要达到C效果的一个条件
-
如果理解够深入可以很明显的看出,事务的4个特性是不对等的,C才是主角,是我们要的结果,AID都是配角,是告诉我们满足了这三个条件以后能到达的效果C一致性。
-
-
CAP 里面有 事务的 ACID 中的 AID吗? 有,只在 CP模式下有,如果是舍弃了C的AP模式,没有AID,但是也不是完全没有,分布式事务很多都是2段式的,不满足原子性质,分布式事务很多都有脏读,软状态,隔离性也被打破。D持久性看起是满足了,但是主从复制,并且主写,从读的集群中,如果网络分区,产生两个可写的主,在网络分区恢复以后老主本降级为从的时候,可能会抹去部分持久化了的数据,D也被破。
-
mysql 读写分离以后怎么保证 读数据的一致性
-
使用全节点同步复制(MGR)。
-
有数据依赖的这种地方去主读,不要去读从。shardingJDBC就是这么干的
-
查询不到可以阶梯的重试,延时消息,或者Spring 的@Retryable注解,如果一定次数查不到,可以认为这条数据是不合法,根据业务要求可以舍弃,或者记录下来人工核对。
-
-
redis做全局缓存的时候,由于网络影响,有些时候我们还需要本地缓存,数据更新以后,集群里面别的节点的缓存修改是的解决方案
-
通过mq通知别的节点删除缓存。需要所有节点介入mq,并且类似广播的方式关注这个事件。
-
通过redis 客户端可以通过 监听接口监听 的key 过期事件删除本地缓存。
-
redis6 支持可本地缓存,这种需要客户端缓存的可以直接放到redis的客户端缓存。
-
redis 的删除 key 事件是基于发布订阅机制,redis 的发布订阅没有重试,网络抖一下就收不到,redis6提供的客户端缓存也是基于发布订阅机制,没有mq可靠性高。尤其是对缓存时间较长的key。个人认为走mq是更好的选择。
-
-
docker 的两个主要作用
-
程序间环境隔离
-
提供统一的打包,允许方式,位自动化部署提供基础
-
如果这两个特性你都用不上,那么没必要非得上docker
-
-
如果我们有保存全量历史修改记录的需求
-
可以考虑修改数据的时候双写插入到历史表(双写降低写入效率,能用但是耦合高),少量修改选这个。
-
可以考虑触发器(不推荐,但是也不是不能用),小项目没有迁移风险,也可以用。
-
使用canal监听mysql 的 binlong,然后写另外的存储节点(mongoDB 或者 直接就是mysql 历史记录表 ),这种方式异步插入,耦合低,修改历史可能比原表数据多得多,mongodb比mysql更加适合,mysql支持千万级别,mongodb支持佰亿级别,但是引入了更多的组件,麻烦,如果有大量需要记录历史修改的地方,这是首选。
-
-
如何应对 瞬时高并发?提升单点程序支持的并发数(通过缓存,降低锁粒度)达到瓶颈以后我们还能做的事情
-
预热
-
限流
-
缓冲
-
分流
-
-
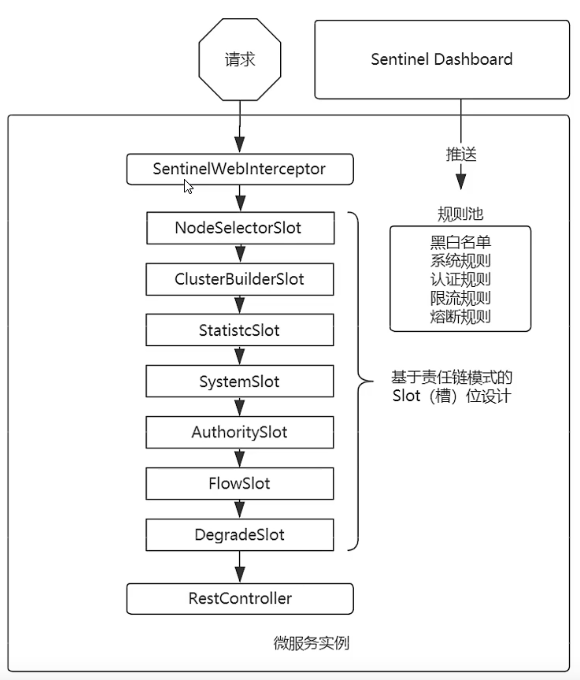
sentinel 是一个外置的流控软件,比内置的流控软件灵活,并且不是分布式应用也能用,是一款流控功能比较全面的工具(单机的时候 流控规则可以考虑保存到mysql,而不是nacos).
下面是sentinel拦截器链顺序
![]()
-
分库分表,一般认为单标行数高了1000W条或者数据量大于(.idb)超过20BG性能就会考试明显的下降了,所有这个一个分库分表的依据,这个依据不是固定的,随着CPU性能提升,内存容量的扩大,SDD硬盘速度的提升这个上限也在逐步提升。几年前,业界普遍认为mysql的单表数据新能瓶颈在百万级别,现在普遍认为千万级别。mysql 单表性能瓶颈不止和数据行数,而且和每行数据量有关。每行数据量很少的索引结构就越矮胖,行数上线也高。
-
分库分表的方式
-
单库单表(中小型应用的常见做法)
-
单库多表,比如做年份分表,每年都产生一张新的表,比如按照数据量拆表.比如用表记录excel的格子数据,这种一般需要按照数据量分表。
-
多库多表,但单库多表 不能满足需求的时候才考虑的方案。
-
多库单表,微服务的默认做法,把服务按照业务才分以后,每个业务的数据库表都可以有自己的物流资源。即便很多小公司分微服务架构,才分了服务,然后也按照服务才分了数据,但是不同数据放到同台物理机子上,这实际已经给后面每个库单独物理机提供了条件,这时候有些跨库join的做法,是绝对不允许的,不能因为自己省事,或者时间紧,就妥协用这种买坑的做法,这种事情做了,后面大概率不会去填,直到后面问题爆发。
-
拆分力度越细,开发难度以次增加,带来的问题越来越多,所以使用的优先级应该是下面这样 单库单表>单库多表>多库单边>多库多表
-
-
为什么要分库分表,导致数据库检索效率变低主要是两个方面
-
第一是,数据结构和数据量的带来的瓶颈。b-tree的检索效率是对数级增长的,不是hash这种常量级的,数据增大检索时间会变长,如果只是这种数据结构和数据量带来的问题,单库多表就行了。
-
第二种,硬件限制。除了数据结构和数据量带来的瓶颈,更多时候带来瓶颈的是磁盘IO,其次是内存和CPU。只要是这种物理资源的瓶颈,多库才能解决,让每个数据库都有独立的计算资源。多库单表,多库多表都能使用到多台计算物理机。
-
-
读写分离是很常见的分库分表策略,也是其中最简单的一种,他能明显的提高数据库的读取并发量。
-
跨库分表带来的最严重问题之一就是分页排序问题,必须要多个库查询然后再组合数据。在深分页的时候计算量和数据量都会大大增加。比如说你要查询第1000页,每页10条。那么要做的是是在 每个节点取出 第 1001页的数据,然后再组合带一起,IO,CPU,内存消耗都极大。单机我们字需要取出通过索引查询出第1001页数据就完了,这两个不是一个级别的。
-
UUID不适合最索引的除了无序会导致频繁的页分裂,还有一个问题就是String类型比Longoing类型长的多,索引字段越长b-tree就越高手。
-
b-tree 和 b+tree 的 区别,b+tree在在叶子节点存数据,b-tree在根节点也存资源。
b-tree不是B减树,而B树。b+tree是B树对数据库的优化版,没有B减数。b+tree也许应该叫做b-treeplus,只在叶子节点存数据是为了数据库排序分页查询的方便。按照索引找到数据以后,如果是按照索引排序的,那么直接读取N个连续行就行了,这种读取一般是顺序读取,如果是还要去计算下一个数据在哪里那就随机读取,要移动磁头,效率很低。并且大多数时候读到我们查询的一页数据都在一个存储的数据页里面。如果没有这种结构,数据库的效率会明显降低。
-
redison 的锁支持重入的,通过value计数器来实现。
-
redis 哨兵模式主节点挂掉以后,从节点顶上这个过程可能会丢数据,也可能丢锁。redis的主从复制都是异步复制,没有提供同步服务的配置。
-
redis LUA 脚本的作用,比如库存扣减以后,需要在已购买用户列表里面记录一个数据,防止这个用户重复购买,这种2个操作我们需要是原子的,但是2次redis修改不会是原子的。这时候我们能怎么办?
-
获取一个分布式锁,然后再这个分布式锁里面发起2次命令。
-
给redis发送一个LUA脚本,就能让2个操作变成原子的。
-
上面的2种做法LUA脚本方式少了一次网络请求,效率更加高。
-
-
redis 是单线程的,指的是从命令执行队列里面取出命令然后执行的过程是单线程的,一个LUA脚本里面的内容会被当做一个命令,所以 LUA脚本能保证原子性的根本原因redis执行命令单线程串行并且还LUA脚本还是占用一格。
![]()
-
通过 macvlan 可以让docker 容器绑定到对应局网IP,有点类似桥接的效果。 默认的端口映射只能映射一个端口,macvlan 需要在网卡上配置。可以认为mavvlan是 ip映射。
-
分库分表以后CRUD会出现的问题
-
删除,和修改,这其实是一个查询,然后做修改的问题,和查询使用同样的做法
-
查询,通过分库列(一般是Id)能快速的算出对应数据库,然后做查询,非分库列,需要通过一些别的手段来提高查询效率,否者只能都执行查询然后合并。
-
插入,数据库自增肯定不能用了,id应该通过与生成,然后算出对应数据库,在进行插入
-
-
分库以后,如果是按照Id分库,然后通过非Id的字段查询和修改数据怎么办?
-
每个库发送一条sql,每个库对查询字段建立索引,然后把结果组合在一起
-
基因发,id是后几位是分库分表的依据,并且这几位来自需要查询的字段算出来的,比如是查询字段二进制hash的最后几位。这样通过查询字段和id都可以算出来保存数据的分库位置。这种做扩容很麻烦并且id和查询字段耦合的。这种做法支持的查询字段只能有1-2个,多了Id长度不够用,而且也会导致更多的页分裂。
-
倒排索引发,在另外一个库或者redis之类的地方,维护这个 查询字段和 ids的关系。并且 查询字段通过 索引或者hash 这样方式高效命中。这种方式通用,和扩容无关,但是每次修改 查询字段的时候需要维护 倒排索引。
-
-
DDOS又称为分布式拒绝服务,全称是Distributed Denial of Service。DDOS本是利用合理的请求造成资源过载,导致服务不可用,从而造成服务器拒绝正常流量服务.
-
带宽攻击(把带宽占等等)
-
协议攻击,TCP 请求 三次握手,值发第一次,把请求连接占满
-
应用流量攻击,发送大量请求,把程序负载占满。
-
-
怎么应对DDOS攻击?
-
低级的DDOS 攻击,可以通过ID,MAC地址过滤
-
高级的DDOS,使用的N多肉鸡,不能轻易的识别那些是真实客户,那些是黑客肉鸡请求。一般做法可以提高自己程序的负载,通过更高的硬件,带宽,更多的你分布式集群,来分担压力,只要你的服务器负载能力高于黑客肉机产生的压力,他的攻击就无效了。如果顶不住,也可以考虑限流保护自己的服务器。这个病毒全球蔓延一样,提高自己的体抗力,扛过去活,抗不过去死。
-
-
redis 的一些建议
-
key的建议, 要见名知意的前提下,长度不要超过39个字符,39 以内有特殊要压缩算法,效率更高。建议模块名:业务名:id
-
存储的建议,接送存对象,比较适合不怎么修改的情况,hash 存对象合适有单独的属性修改的情况,经常变动的大对象,不合适存redis,如果一定要存,可以考虑分块存储,相对固定的历史按照固定规则拆分成多个小可以存储。
-
redis 的安全,不要允许所有网络访问,只能bind 指定IP。不要用默认端口6379。不要用root 启动。对外的服务一定要设置密码,除非只是内网。如果有需要,可以通过linux的定时任务,定期备份。防火墙不能随意关闭,只放行最小的端口。
-
-
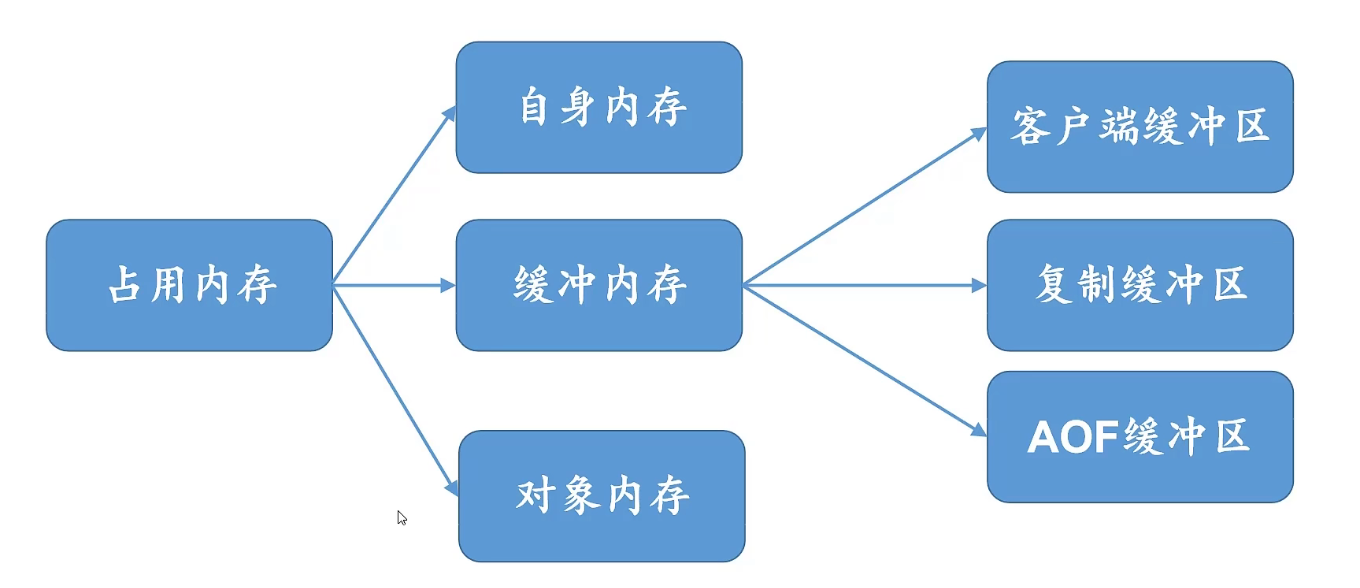
redis内存分区
![]()
-
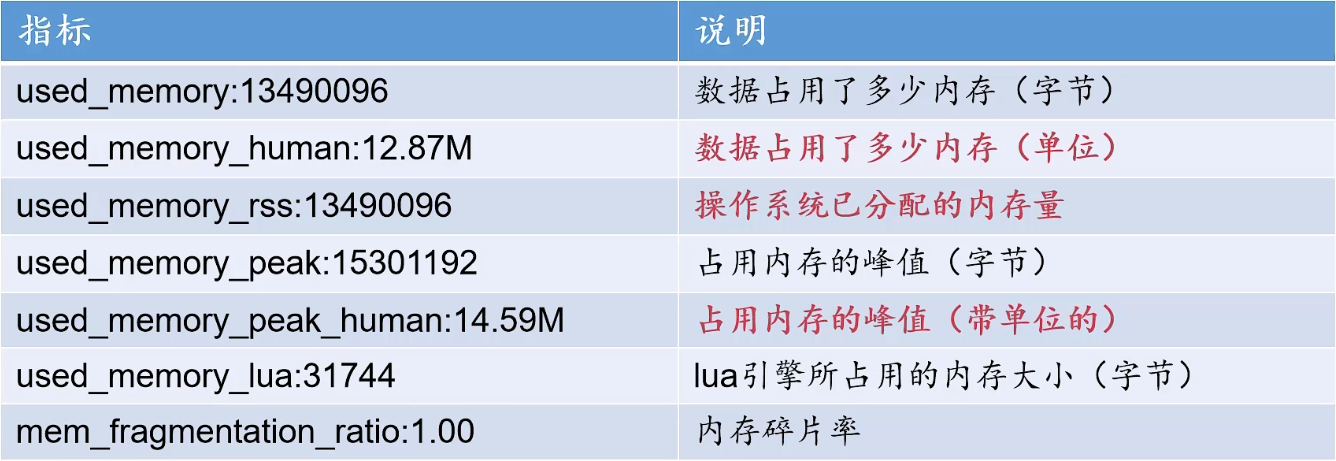
可以通过 info memory查看redis 内存占用
![]()
-
redis 可以通过设置 maxmemory 设置最大使用的内存,一般位预估使用内存的130-150% ,不能大于最大物理内存,并且redis可以使用的最大内存支持动态扩展。不需要重启。
-
redis在内存满了以后会触发内存淘汰策略,下面是redis的内存淘汰策略
-
no_eviction(默认),不驱逐,返回内存满了添加不进去的错误提示
-
volatile-lru(推荐),在有过期时间的key中,删除最近最少使用的
-
volatile-lfu,在有过期时间的key中,删除最少使用的
-
volatile-random,在有过期时间的key中,随机删除
-
volatile-ttl,在有过期时间的key中,删除过期时间最短的
-
allkeys-lru(推荐),在所有key中,删除最近最少使用的
-
allkeys-lfu,在所有key中,删除最近最少使用的
-
allkeys-random,在所有的key中,随机删除
-
-
redis的内存淘汰策略可以分成2个维度
-
淘汰key类型,allkeys或者volatile
-
淘汰算法,LRU(Least Recently Used),LFU(Least Frequently Used),Random(随机),TTL(过期时间)
-
2*4=8种,永不过期的key没有按照ttl 时间的算法,所以7种,加上不淘汰也算是一种一共8总淘汰策略。
-
-
mysql json + 虚拟列索引,可以实现非结构数据的快速快速查询,前提是你们用的5.7以上,并且公司部门领导可能接受这种比较新的语法,更好的解决办法也许是ES,或者mongodb。
-
RocketMq的存储和索引方式
-
默认保存root/store 目录下面,有commitlog,cosumequeue,index,存的是消息和索引相关的结构。
-
commitlog:这里面按照存储着消息的数据文件,默认每个文件1G,文件名默认是当前文件块内第一个消息的offset,这样通过offset就可以快速的定位消息在那个文件里面。我觉得应该还有一个索引结构里面定长的存着消息ID和数据文件磁盘位置。
-
消息ID里面包含了offset的基因(borkerId+offset)。所以通过消息ID也可以快速的找到offset。
-
cosumeQueue里面第一级是toppic名字,toppic名字下面是队列编号,然后下面的数据文件存着 tag(的Hash) + size + offset信息,拿到offset以后就可以可以去commitlog里面查询消息内容了。cosumeQueue提供了按照toppic和tag能够快速找到消息内容的方式。
-
index 里面放在 通过 我们指定的 message key 来查询消息 offset的 结构,原理就是以一个hash 结构,默认500W个hash槽,链表长度4,
-
-
VRRP(Virtual Router Redundancy Protocol),是由IETF提出的解决局域网中配置静态网关出现单点失效现象的路由协议,1998年已推出正式的RFC2338协议标准.
-
什么是服务网格( service mesh),一种把通信模块从服务中剥离出来单独管理的架构方案。
-
通信模块位于服务中有那些问题,通信服务我们一般会使用 openFeign,httpClient,服务熔断限流,重试,类似的东西,这些东西有些只是对指定指定或者常见语言才有的,微服务,架构本质上是不限制使用语言的。使用了这些带有特定功能的通信层,就我们的微服会内部使用的语言会受到一定程度的限制。服务网格要做的就是把这块剥离出来。
-
服务网格用了sidecar(三轮摩托,一个人开车,一个人战斗)思想,服务只关心业务,通信模块有单独的模块来完成。
-
另一一个角度来看,我们真的需要服务网格吗?大型公司服务集群庞大,不同情景有偏向的语言,并且有资金有技术有人力来这样做,但是真的有那么多异构平台吗?真的愿意话这么多精力来干这个冒失有点伪需求的事情吗?如果是中小公司,我们完全没有这么多业务情景的需要这样的模式,而且很多中小公司微服务都还没搞清楚,考虑多语言异构通信耦合是没有必要的。
-
Domain Driven Design,简称DDD
-
REST 和 RESTful
-
rest(Representational State Transfer),表现形式状态转换,是一种规范,一种对请求uri,请求动作,相应格式的一种规范。强调URI确定资源,请求方式决定行为,并且严格按照请求地址 +状态码+响应体的格式返回。比如 user/{id}表示的用户资源,user/1表示用户id=1的用户,get 表示查询这个用户,delete表示删除这个用户,put 表示幂等的修改这个用户的数据,post,非幂等的修改这个数据。
-
restFul,是一种风格,如果资源地址和控制资源的行为都是按照rest建议的来做的,你使用的就是restful 风格。
-
个人觉得 rest 是强迫症的福音,格式整齐划一,uri 的定义很好,但是请求方式的类型http协议限制的太死了。对一份资源部不只有增删改查,同一份资源的查询和修改是有很多种方式的,比如查询用户列表,可以查询平铺或者树形,修改可以是冻结,解冻,审核,拒绝等等,删除可以是级联删除,和单个删除,添加可以是全量添加或者部分添加,明显rest 所要求的统一格式不能满足这些特定的业务。get 对查询数据其实很不友好,比如复杂查询数据用json 请求可以明显的提高开发效率和沟通成本。如果大家都用 post 请求,都用json 格式,通过URI名字来区分行为不是更加合理统一吗? user/行为,然后请求体里面带上参数。
-
-
RPC 远程过程调用,RMI(java独有)远程方法接口。强调的都是远程调用,远程调用都可以叫做 RPC,REST 是http数据交互的规范建议。RPC 和 REST 不是 同类型的东西。
-
对于共性需求,有些时候使用注解可能比使用aop切方法更加好。 申明事务,两种都提供,但是我们现在应该都只用注解的方式了。
-
FST(Finite State Transducers) 一种搜索数据结构,百度好像用的就是这种。ES的 completion suggester 也是用的这种。
-
如果有些情况不能用上索引(左like,正则查询 )只能全表扫描,并且数据行数很多,然后内存有比较多的情况,可以考虑momory存储引擎,默默日语存储引擎不支持事务,不能持久,但是支持sql查询。内存比硬盘可快多了。
-
redlock出现的目的是解决主获取了锁,然后还没有同步给从的时候,主挂了,然后从顶上,另外一个客户端获取到这把锁的问题。
-
redlock的过程是串行的向每个master 发送请求,如果过半节点锁定成功,就算成功,并且锁定时间按照所有写节点中最后一个计算。有些极端情况redlock 会出问题的。
-
如果ABC三个节点,客户端1获取了AB,认为获取锁成功,这时候客户端2获取了C,然后B的时间跳跃,导致锁的key过期,客户端2也获取到了B,这时候两个客户端获取到了锁。时间跳跃可能是人为,也可能是网络对时。redlock的作者建议,人祸不管,网络对时应该少量多次。
-
客户端1获取了AB,这时候B的master挂了,从顶上来,客户端2获取了B,然后获取了C。这个问题redlock 作者建议把重启的时间延长。保证前面的锁过期。
-
-
redslock 为啥要用 hset 不是普通的 色 setnx,为了锁重入并且标记客户端。 用hash 结构的 key标志客户端(锁范围内,客户端保持同一个uuid),用value标识重入次数。
-
spring boot3 以后默认使用 gradle 7 和 jdk 17。
-
docker 的网络模式
-
brige模式(默认),需要手动指定物理机端口和容器的映射关系。
-
host 模式,相当于自动映射容器的端口到物理机的指定端口,这时候不容容器不能使用同样的端口。
-
container模式。访问一个容器端口的时候,可以转发给另外一个容器。
-
macvlan。相当于IP映射
-
-
mongodb的优缺点
-
优点
-
4.2以后支持分布式事务
-
mongodb自带读写分离
-
自带数据分片.
-
自带故障转移(主挂了,从顶上)。
-
-
缺点
-
mongodb 目前可能替换关系型数据库最大的问题在于反范式设计,这种设计不能支持多表查询,如果冗余的话级联变化也变得困难.
-
不支持sql也是不符合老程序员的习惯。这两点应该是mongodb成为主要主存的最大阻碍。
-
-
-
常见限流算法计数器算法,滑动窗口算法,令牌桶算法,漏桶
-
单位指定后添加容量的是计数器算法
-
单位时间中,阶段的添加容量的是滑动窗口是有大窗切换的容量重置
-
单位时间中匀速的添加容量的令牌桶,没有容量重置。
-
带有缓冲,更加适合业务允许异步的 是漏桶
-
-
http2的新特点
-
头部压缩
-
双向留,多路复用
-
二进制帧
-
服务区推送
-
-
Huffman编码 是用5个二进制位来表示,8位的ascii码。所以能节省一定的空间。http2的头部压缩,是基于静态表和huffman编码加服务区端缓存一定数量的请求头来实现的。
-
客户端负载均衡和服务器端负载均衡的优缺点
-
服务器负载均衡的优势在于容易做统一的故障转移,缺点在服务器点负载均衡器压力比较大,需要做高可用处理。
-
客户端负载均衡好处在于故障转移需要客户端实现,优点是不会有类似服务器点服务器均衡器吞吐量压力。
-
微服务架构使用的就是客户端负载均衡。很多支付分布式集群的中间件也都是使用的客户端负载均衡。服务器端负载均衡适合前后端分离的情况,这时候我们不能信赖前端一定会负载均衡的请求服务,并且服务器端负载均衡可以隐藏那个很多细节。
-
-
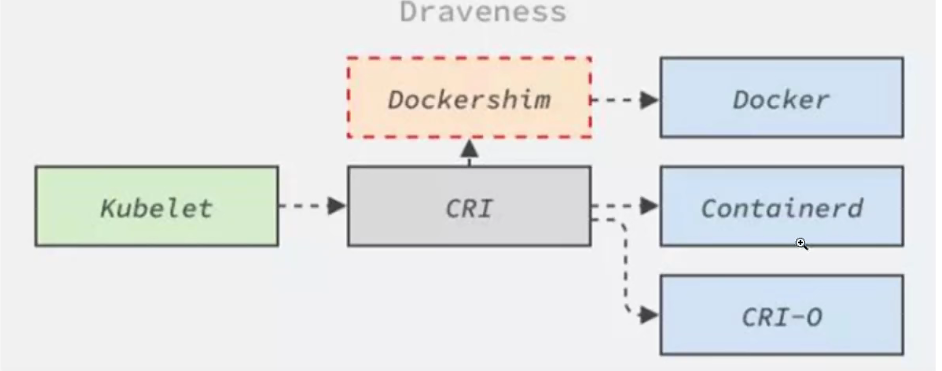
kubernetes 1.20已经原生不支持Docker了,但是可以通过 Dokcershim 中间层来支持docker,kubernetes1.24 连Dockershim都移除了,原因是 Docker没有兼容 CRI 容器化标准,Dokcershim 是google做的支持 CRI标准的 Docker中间件,kubernetes1.24已经不能用了,三方出了一个叫做cri-dockerd的插件支持docker。除了Docker以外,Containerd,CRI-O,Podman也是容器化服务器软件,他们都是支持CRI标准的。
![]()
-
podman 使用方法和docker及其相识,并且支持CRI标准。kubenetes作为主流容器编排工具已经彻底的放弃了Docker,可能后面podman会成为主流的容器化工具。
-
对于数据量多的数据,查询统计是很慢的,但是有些数据是发生了就不会变的,比如注册用户数,账户流水,这种数据可以做成日结算,来帮助我们后面快速统计。有些数据就不能做陈结算,比如活跃用户,只能做成趋势图,不能做成日结算。日结算是软件设计中提高运算效率的常见方式,前提是这些数据是静态数据。
-
淘宝的平均日订单数量大约3000W笔,347笔/秒,如果不算双十一但是考虑20倍的那个峰值流量约7000笔/秒。(按照适龄用户占中国人口一半(15-50岁),我这个年级算淘宝用的比较多的,平均值算我的一半。我平均一个月3笔,平均算1.5,然后我得出这个结论以后也查询过,淘宝订单确实在3000W/日的样子,京东 美团在1000-2000W)
-
OLTP 和OLAP数据库是什么?
-
OPTP (Online Transaction Processing) 联机事务处理系统,也就是支持事务的数据库,面向业务人员和用户。比如mysql ,oracle之类的
-
OPAP(Online Analytical Processing) 联机分析处理系统,存的数据是面向数据分析人员的。比如 clickHouse,hbase + hive。
-
-
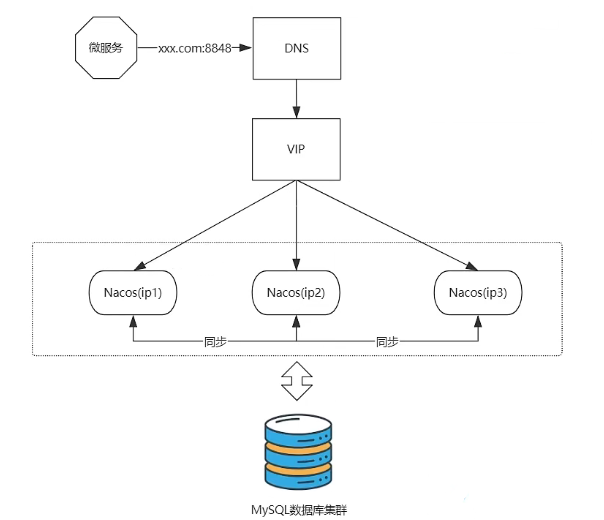
nacos2.X 使用看了 grpc 和 NIO,性能比1.X 提升了3-5倍。2.X可服务器端和1.X的客户端是完全兼容的,建议都使用2.X。
-
OGNL 配合 json转map 可以方便的通过表达式提取 多层嵌套 json 中的属性值。
-
junit的测试只能是测试普通方法,StringbootTest 可以测试spring容器环境下面的接口, 使用MockMVC 可以方便的测试Controller层的接口。
使用 MockMvc 需要在测试类上写上 @AutoConfigureMockMvc 然后注入在变量 MockMvc 类。
-
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT) 可以让测试类使用随机端口,避免断就占用。
-
分布式架构的三种调用方案
-
基于服务端的反代理的负载均衡方案( 没有 注册中心,通过 nginx 之类的 方向代理实现负载均衡)
-
基于注册中心的客户端负载均衡的微服务架构方案(nacos + springcloud alibaba)
-
istio+Envoy 服务网格方案,依旧是基于注册中心的客户端负载均衡,不通点在于服务间通信和负载均衡使用了 envoy 的独立进程来实现。耦合性更低。
-
-
监控套件的选择
-
springboot admin ,如果只监控java 进程选它
-
ELK,偏向日志的收集和分析。
-
prometheus+grafana,日志收集并且收集指标主机,软件运行指标(mysql,es,ngxin,redis,mq,java的的指标)。
-
-
spring-boot-admin-server 提供图形用户界面,可以方便的显示 spring-boot-admin-client 上报的java程序的 actuator指标。spring-boot-admin不是spring 官方出的。
-
jdk17 加入的 密封类对类的继承给出了限制条件
-
父类和子类必须要在一个包路径下
-
父类使用 sealed 关键字修饰是密封类,使用 permits 关键字修饰那些子类可以继承
-
子类可以使用 final(不能在向下继承),non-sealed(不限制向下机制),sealed+permits(向下只有部分继承)限制向下的密封状态。
-
-
DevOps(Development和Operations的组合词),它是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。说白了就是开发运维按照指定规范来完成 软件的交互,部署,运维,以尽可能的自动化操作为目标。
-
针对树形结构的快速查询辅助方法
结构图如下:
![]()
-
除了p_id和level以外,在用left,right存排序编号来实现预排序(注意left,right存的不是id,只是排序编号)
-
查询所有子孙节点:where left between c.left and c.right(c表示当前节点)
-
查询子孙节点数:count = (right-left-1)/2
-
判断是否是叶子节点:right-1=left
-
查询所有父祖节点:where left <c.left and right>c.right
-
确定层级:select count(星) +1 from treee where left <c.left and right>c.right
-
查询所有子节点:where left between c.left and c.right and level = c.level+1
-
新增的时候时候需要后续节点left,right+2,然后再添加,注意如果是在非叶子节点删个添加,需要找到它最右一个子节点作为插入点。
set left = left +2 where left >c.left
set right = right+2 where right >=c.rightinsert into tree(left,right) values( c.left+1,c.left+2 )
-
删除是插入的逆操作,修改父子关系可以看出是删除一个,然后插入一个
-
这种结构查询很快但是修改很复杂,每次修改都几乎是重建全部排序字段,只适合变动比较少查询比较多的树形结构。
-
-
什么是开窗函数?和 group by 相反,group by 分组以后行数减少,over 开窗函数相当于分组但是 不减少行数,然后对组内的 行数据做运算,可以对组内上下N行做统计,也能对组内所有行做统计。mysql 8以后支持 开窗函数了。oracle很早就有了这个函数。
-
mysql 8 提供的 lag 函数可以 配合 over函数方便的算出环比,同比,均差数据。lag函数可以得到当前行 前面N行的内容。
-
Quarkus 对比 spring boot
-
编译启动速度,Quarkus 比 springboot 块很多
-
内存占用 Quarkus 比 springboot 占用的内存少
-
CPU 占用,两者差不多
-
相应速度,Springboot 比 Quarkus 块
-
Quarkus在容器化,k8s等自动化方面有天然的支持。
-
-
什么是云原生?腾讯,阿里,华为,亚马逊等云服务商提供了云服务器,动态带宽,云存储,云计算,mqsql,redis ,mq,es,dns,cdn,负载均衡器,安全组件等等可伸缩的基础服务。他们做的是就是云原生,我们可以使用云原生提供的基础组件来构建我们的应用,相比传统的机房,基于云原生的应用在构建,部署,扩容方面都极其方便。缺点也很明显,数据不是在自己机房里,cpu内存硬盘带宽上限都很有限。做云原生和用云原生不是一回事,奴隶主和奴隶不是一回事,为什么推云原生?应为互联网巨头为了应对特定场景的并发压力采购了大量服务器等设备,在没有活动的时候,这些设备处于低负载,把这些设备租出去世最好的选择。一个人如果有有一张健身卡,一张游泳卡,但是他它今天去健身就不回去游泳,健身房的老板和游泳馆的老板如果有共同利益关系,那么他们肯定愿意8折优惠出售2张卡,而不是只卖掉一张10折的卡。
-
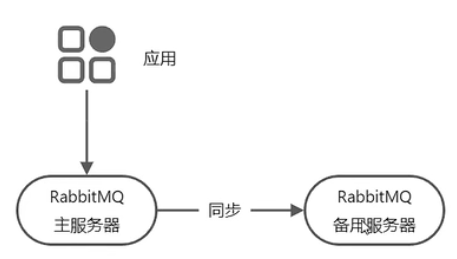
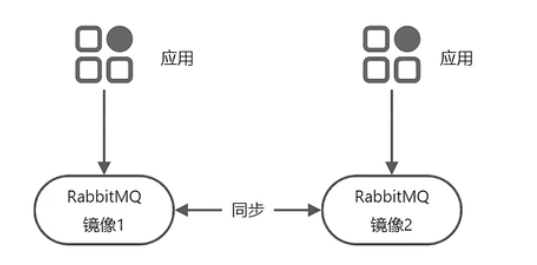
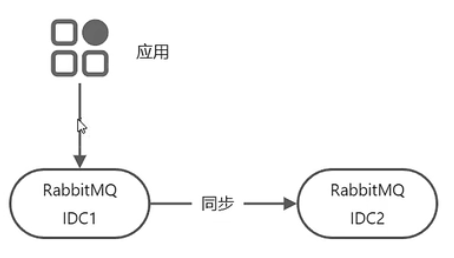
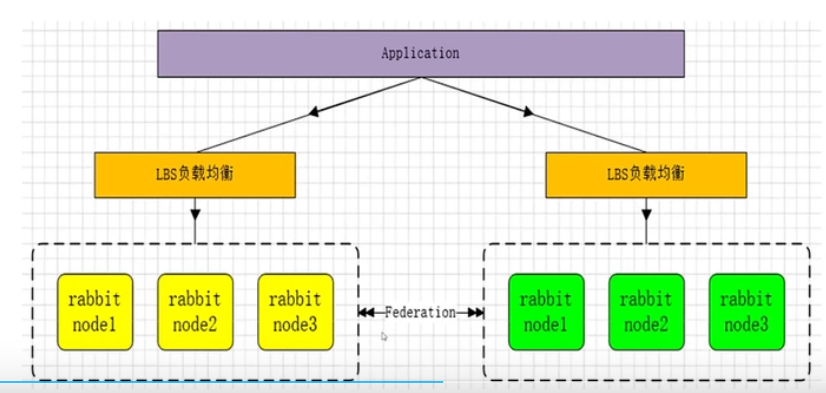
rabbitMQ集群方案
-
主备模式,一个对外工作,另外一个只作为备份服务器,主挂了以后备顶上
![]()
-
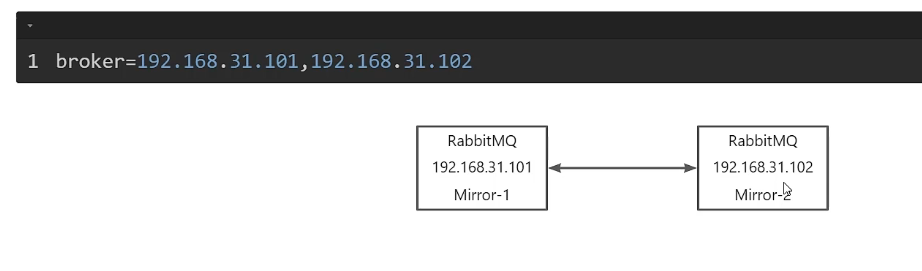
镜像模式,多主强一致性模式,镜像间同步完成以后才会想应用返回处理结果(推荐)。
![]()
-
远程模式(shovl模式),跨IDC机房,远端异步确认,近端同步确认。
![]()
-
多活模式(通过federation插件)
![]()
-
-
rabbitmq镜像模式高可用,因为多个写入节点,单一个节点挂掉的时候,我们要去使用另外 一个
-
客户端负载均衡化,一来客户端调用节点失败的时候自动切换到下一个节点。
-
服务器点负载均衡,rabbitMq是 TCP 协议,nginx 1.9以后使用 with-stream 模块也能支持 TCP的 负载均衡,或者选支持第4层的负载均衡器如Haproxy,LVS,F5,或者云服务厂商的SLB。使用了 Haproxy,ngxin 以后也带来了负载均衡器的单点故障,可以考虑 keppalive+vip方案。如果只有mq需要负载均衡,那么直接挂VIP+DNS轮询也是可以的。
-
-
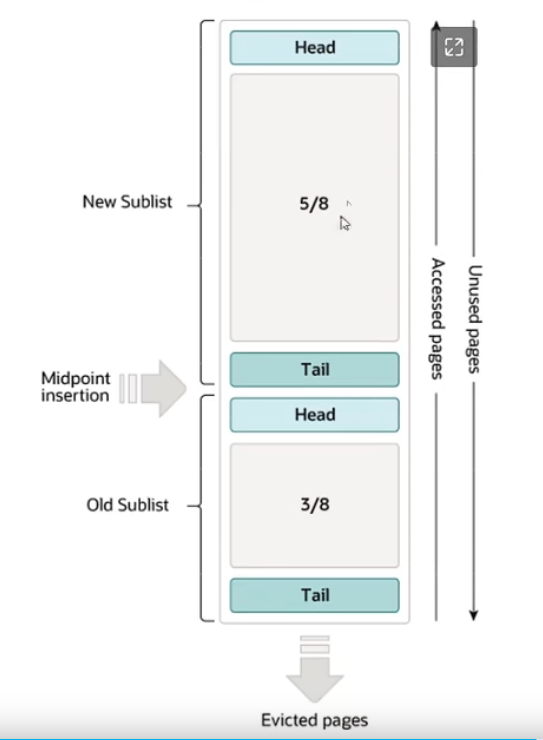
mysql 的 buffer pool 结构如下图,分成新旧两个部分,加载一个新页的时候插入到中间位置,并且吧老叶向下顶,最下面的老叶就被驱逐。然后buffer pool 里面的页被再次访问的时候就会被向上提。mysql的 索引,排序,临时表,join等等操作消耗的都是 buffer pool 的内存,如果偶然的大量载入新页(join,全表扫描,字段排序,临时表等等),会导致前面构建的有效缓存过期,后面要重新构建缓存,影响系统效率。mysql可以通过一些配置,让缓存池具有抵抗性。
![]()
-
redis3 开始支持集群模式,但是那时候的集群模式默认没有支持读写分离,需要集群的读写分离需要客户端实现。redis 6以后默认支持 集群模式的读写分离,通过 redis-cluster-proxy 代理中间件 来分发读写请求,redis-cluster-proxy 不仅提供了读写分离节点选择,还提供了集群写入节点路由选择。
-
mysql in的上限是1000 个。
-
字符串的Long占用的空间约比long大2.4倍。所以能用long 就要用long。一个Long用字符串表示需要19个字符,一个字符用ascii编码占用1个字节,Long 8 个字节。
-
mysql的单表瓶颈,建议的单表数据1000W是怎么算出来的?
-
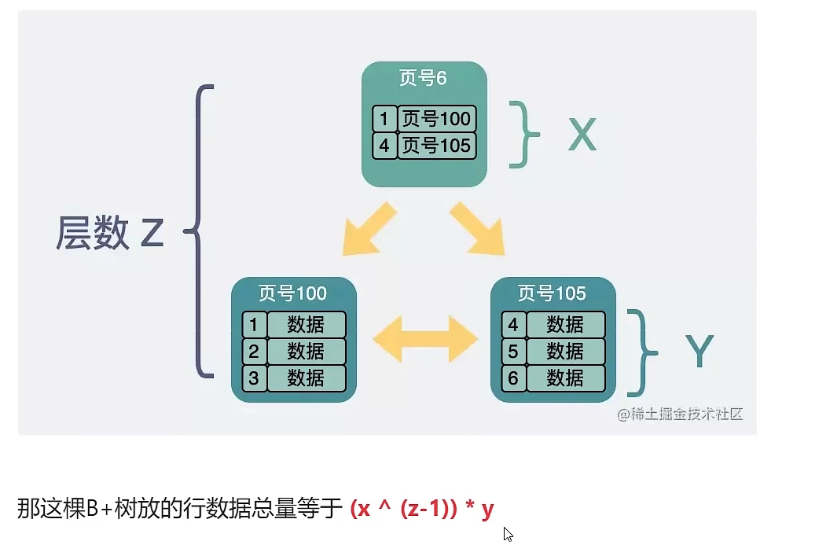
1000W 是根据,单行数据在2K,然后用Long作为主键,b+tree的层高3层的基础上算出来的。层高每多一层就多一次磁盘IO,而且mysql 的 b+tree最顶上的根节点是缓存到内存的,3层树实际只有2次IO,4层树3次IO,查询耗时提升50%。图上只有2个分叉,实际mysql的分叉数量远不止2个,大概1000 多个。
![]()
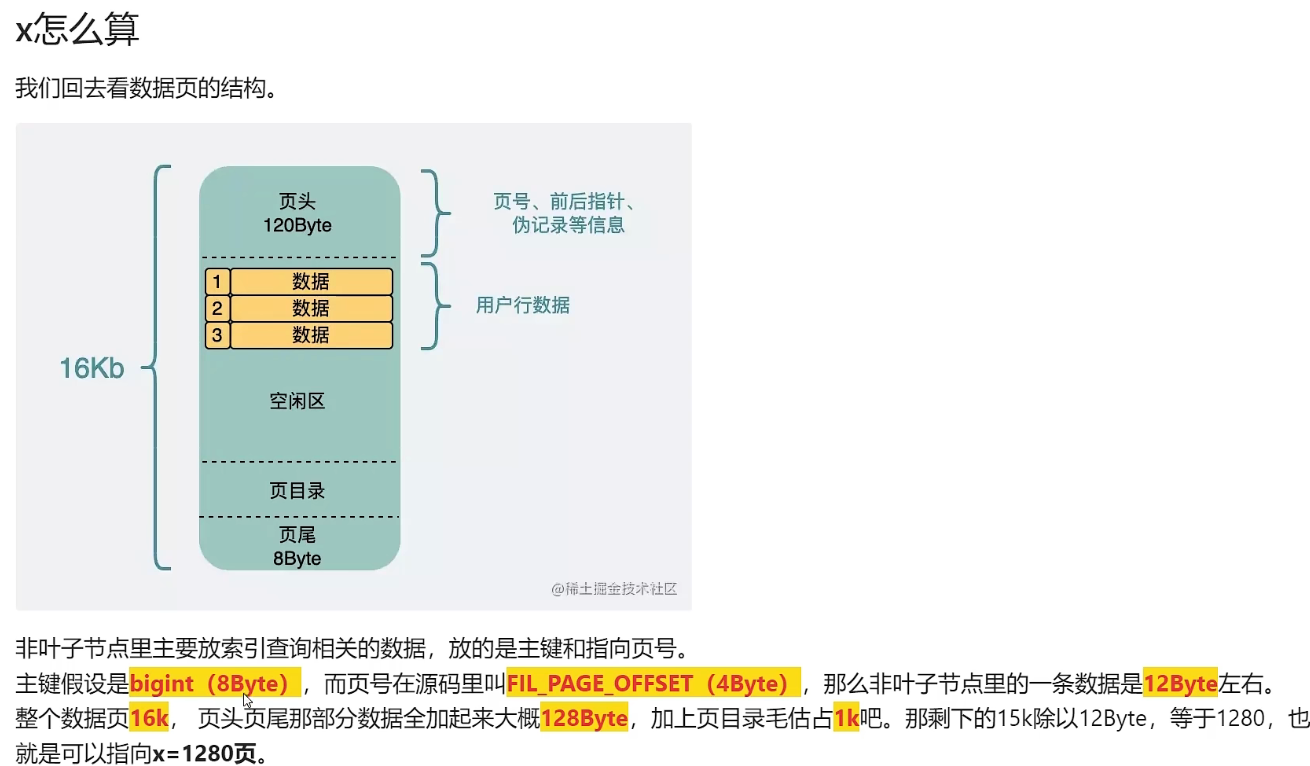
-
b+tree的结构,只有叶子节点存数据,一页16K,页里面除了放数据还有页头120byte,页尾8byte,页目录,剩下的才是数据区。我们假设数据区是15K,叶子节点放1K的数据可以放15条。根节点放的都是索引,主键8byte,页码(page_offset)4byte,放一个索引一个需要12byte,15K 就是1280.树形结构的叶子节点数=根节点可以存的子节点数量 ^(层高-1),每个叶子节点存15条。3层就是 1280^2*15≈2457W,如果是4层约可以存314亿数据。也就是如果用ssd如果检索3次的效率能和hdd 2次效率一样,岂不是314亿数据都能保证目前的效率?实际扫描一次非叶子节点也要差1000多个索引,每多一层,就要多1000多个,所以对cpu性能也多50%。
![]()
![]()
-
为啥数据库是b+tree?为了非叶子节点不存数据,只有非叶子节点不存数据,才能存更多条索引记录,查询下旬效率才越高。
-
上面计算的是聚簇索引的3层索引的,如果是非聚簇索引3层数,能存的数据更多,但是这里叶子节点找到的不是数据,而是数据的存放位置,真实取数据还要检索一次磁盘,非聚簇索引的3层树效率等价于聚簇索引的4层树效率。
-
-
token的一些建议
-
token 里面最好不要包含用户的敏感信息,尤其是通过签名校验token值是否被修改的情况。
-
token 里面最好要包含客户端标志信息,比如mac地址,ip,客户端类型之类的。以防止token被盗用。网络ip可能随时变化,一般用mac地址摘要是比较合理的。
-
-
http 接口安全的一些注意项
-
后端的接口参数一定要校验。前端传过来的数据是不靠谱的,调用接口不只是前端也可能是攻击者,比如用于网页显示的数据一定要html脱敏。
-
后台数据要尽量放弃规律。如果别人知道了规律那就就能通过规律获取额外信息,比如userId 是自增的,资源Id是自增的。
-
性能瓶颈明显的接口需要考虑限流。
-
能修改关键数据的接口一定要认证操作人权限。比如支付回调,请求数据异步回写接口一定要验签。
-
如果token没有做客户端标志,那么有些敏感接口需要做客户端相关的none值认证。一般建议在token上做,比如QQ微信,系统备份以后在别的电脑上恢复,记住的密码依旧会过期。
-
生产要使用https。http的明文现在很少有在生产用了。
-
即便有https 有些敏感数据我们也要考虑自定义加密,https的加密只要用户客户端植入证书就能获取到铭文,虽然在用户客户端植入证书已经算用户授权了,正常不应该考虑。但是有些时候,重要数据多一层保护总是好的。
-
-
springboot 可以通过 -Dloader.path=xxx 指定而外的classPath
-
SPI(Service Provider Interface),是java提供的 一个 服务接口拓展机制。使用SPI 可以轻松的修改接口的实现方式。mysql 驱动,java的日志,都是用这个SPI接入。
-
定义一个接口
-
然后再别的项目实现这个接口,并且在classpath下面创建 META-INF/services,然后定义一个名为接口全类名的文件,文件里面写上实现了的全类名。
-
只要实现类的jar以任意方式加入到接口当前项目的classPath就能通过 ServiceLoder.loder(接口名)方法获取所有实现。
-
-
写锁,有索引,但是索引过滤性差,走了全表扫描的时候,会使用表锁,这时候可以通过 缩小查询访问来让mysql走索引,或者通过 force index() 来强制走索引。
备注:for update的情况更加容易出, for update 的时候会走主键索引。 -
redis6 以后默支持json对象了。要求json嵌套不能超过128层。
需要通过 redis-server --loadmodule ./target/release/librejson.so 来开启这个功能docker 镜像 redis/redis-stack redis6 以后默认开启了 json模块。
-
5种构造模式使用场景
-
单例模式:需要构造一个全局唯一的一个对象。
-
原型模式:按照一定模板复制一个对象。
-
单工厂:构造参数比较多,并且需要构造指定几种指定类型的一类对象。强调有几种固定的方法来构造对象。
-
抽象工厂模式:构造参数比较多,并且需要2个维度的来构造一类对象。
-
建造者模式:构造构造参数比较多,并且参数的组合有一定限制,强调构造以后传入的参数不可变(不可变对象)。
-
速记口诀:建造者单例原型工厂(建造者单挑两个拷贝工厂)
-
-
7种结构模式使用场景
-
外观模式:提供统一的高层接口,屏蔽底层复制的调用关系。
-
适配模式:屏蔽多于实现或者方法名修改/出参入参加工
接口适配器-适配器类空实现所有接口方法,屏蔽不需要实现的接口
类的适配器-适配器类继承逻辑实现类并且实现指定接口,接口实现方法里面调用逻辑类的实现方法。对象适配器-适配器类组合逻辑实现类并且实现指定接口,接口实现方法里面调用逻辑类的实现方法。
-
代理模式:代理和装饰器基本一回事,用于对原对象的功能增强,无限套娃,强调语意不同,代理强调原始对象不需要存在,装饰器强调原始对象依旧要存在。
-
装饰模式:和代理的区别,在于强调不丢失原始对象,或者说 装饰器用的是聚合原始对象,代理用的是组合原始对象。
-
桥接模式:解决2个维度变化类爆炸问题,如果是继承的话,两个维度会产生笛卡尔积,如果是组合的话,被两个维度都可以任意变化,是一种抽象类和接口,接口类的变化维度可以任意拓展,抽象类维度的变化。桥接模式强调用组合代替继承。
-
享元模式:叫做池模式更加合理,连接池,线程池用的都是享元模式。
-
组合模式:组合模式,就是树形结构,或者活dom 结构。组合模式 是自己组合自己,桥接模式是自己组合别的变化维度。
-
速记口诀:外观适配代理装饰,桥接享元组合(外面穿着和代理商一样的装饰,去桥上接享元组合)
-
-
11种行为模式
-
迭代器模式:
-
责任链模式:
-
模版方法模式:
-
命令模式:
-
策略模式:
-
访问者模式:
-
观察者模式:
-
备忘录模式:
-
中介者模式:
-
解释器模式:
-
状态模式:
-
速记口诀:迭代器责任,模板命令策略,访问者观察备忘录,中介者解释状态(迭代器的责任链是,让模板命令策略,让访问者观察备忘录,让中介者去解释自己的状态)
-
-
单例模式和建造者模式经常会限制构造方法的公开。
-
rabbitmq 死信队列做延时消息过程
消息发送到死信队列——>消息积压在死信直到过期——>死信队列把消息转投给别的队列——>消息被延迟消费 -
使用NFS可以实现不同主机之间的文件共享(类似磁盘共享的效果)。文件服务器主机安装 nfs-util和rpcbind,客户端主机安装 nfs-utils,然后挂载文件服务器主机的目录。
-
oauth2.0 授权码模式,是一个三方授权协议
-
需要获取授权时,三方应用前端引导客户打开授权服务器授权地址(需要带上三个重要参数,授权模式,三方Id,三方服务器地址)。
-
授权服务器检查权限以后提示用户相应的授权方式(点击同意,或者登录)
-
客户授权后(点击同意,或者输入用户名密码后),授权服务器重定向到三方应用的服务器并且带上授权码。
-
三方服务器取出授权码,然后使用授权+三方密钥,获取token。
-
拿到token以后三方服务器就能访问客户的资源了,如果这个资源是唯一用户Id,那么我们就能确认授权用户的身份。
-
为什么要引导用户跳转到授权服务器的地址再输入账号密码?因为三方授权,用户名+密码不能让经过三方应用,只能跳转到授权服务器自己等登录界面才行,一句话授权服务器不让这么干。
-
为什么要获取授权码在获取token?因为获取授权码不需要三方密钥,获取token需要。三方密钥不能下发到前端,前端知道了,全世界就都知道了。
-
-
oauth2.0 授权码模式简化模式,对没有后端服务器的三方页面,这种授权模式极端不安全。客户端获取到的直接是token,并且获取token不需要客户端密钥。因为三方只有前端,保存客户端密钥也没啥用,浏览器调试什么都看得到。这种模式季度不安全,一般没人用。另外一般的授权服务器,重要资源也不开发这种授权模式。
-
oauth2.0 账号密码模式,通过 用户账号密码+客户端Id客户端密钥 来获取token。这种模式客户前端会持有用户的账号密码,所以这里的客户不可能是三方应用,只可能是授权服务器的内部应用。这种模式一般用来做分布式用户单点登录。
-
oauth 2.0 客户端认证模式,这种模式只要 客户端Id+ 客户端密钥正确就能获取token。和用户没关系,是内部服务之间授权的一种方式。
-
oauth2.0 4种协议,2种是三方的,简化模式极度不安全,2种是内部授权的,一种用户登录,一种内部机构之间授权。shiro 在分布式领域被 security 取代的主要原因就是 security 原生支持 oauth 2.0协议。
-
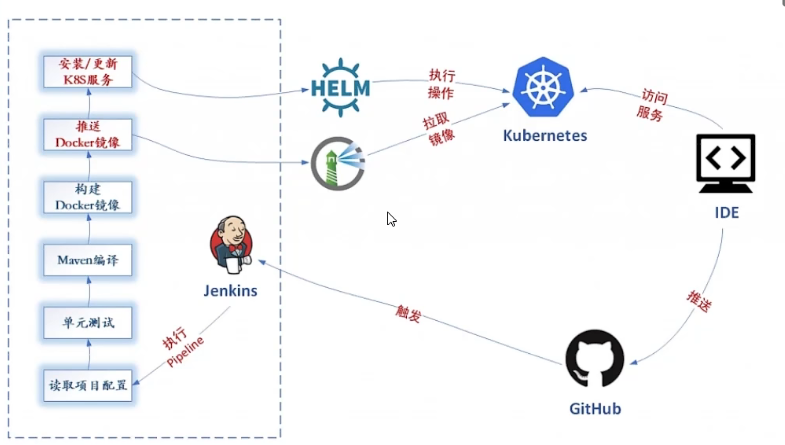
DevOps是一种减少开发和运维之间的代沟的思想,开发在自己开发环境能正常跑的程序运维拿到测试/生产环境去部署不一定能跑起来,即便运维是按照开发的要求部署的,但是这里面也可能存在理解不同,产生问题。DevOps 是为了减少开发运维的代沟,如果按照统一的规范自动化的去集成,打包,测试,交付,然后按照一定的规范启动程序。那么出叫沟通不到位的概率就会大大降低。目前DevOps的常见落地方案是 jinkens+docker+k8s.
![]()




-
gitlib 也是支持CI+CD的,gitlib可以自动完成自动打包+自动测试+自动生成容器镜像,一般用的更多的是jenkins。
-
CICD流程图
![]()
-
数据迁移工具DataX 是多线程抽取原始数据库数据,然后把数据拆分成多个子任务,然后多线程的写目标数据库,效率比较高。迁移比较大的数据量的时候可以考虑。
-
RBAC(Role-Based Access Control),基于角色的访问控制,模型是20世纪90年代研究出来的一种新模型,但其实在20世纪70年代的多用户计算时期,这种思想就已经被提出来,直到20世纪90年代中后期,RBAC才在研究团体中得到一些重视,并先后提出了许多类型的RBAC模型。其中以美国George Mason大学信息安全技术实验室(LIST)提出的RBAC96模型最具有代表,并得到了普遍的公认。
-
RBAC4级权限
-
0级,我们常用的角色权限加两个中间表
-
1级,在0级的基础上,角色分级
-
2级,在0级的基础上职责分离,可能存在互促角色,需要考虑角色冲突的情况怎么处理,动态责任分离需要程序兼容冲突角色应该在处理,静态职责分离是选定一个角色以后在做某件事情,二级有有角色数量的限制,并且考虑角色升级需要预制条件
-
3级,角色分级+责任分离,并且需要权限审计
-
-
ABAC(Attribute-Based Access Control),基于属性的权限控制,基于属性的权限控制指的是根据用户的属性来判断拥有那些权限。
-
开发组件选型应该考虑那些因素
-
功能方面:是否可靠,是否高可用,适合的业务场景,软件偏向的业务场景。
-
性能方面:负载,高并发的支持
-
使用方面:安装,使用,维护的难以程度,配套的软件是否容易操作。
-
软件稳定性:技术文档支持获取难易程度,是否有稳定的团队对他进行维护更新。
-
市场占有率:市场占有率,掌握人员比例。
-
收费或者开源协议:收不收费,怎么收费,开源节软件用的什么 开源协议?能不能随意的修改软件源码等等。
-
-
后端去状态换的三种方式
-
依赖web容器的session同步方案
-
用户有关数据存在token里面,并且token内容需要加密(加密不是转码和签名)
-
使用容器无关的独立存储来存储session 信息。
-
实际使用更多的是 token + 容器无关的独立存储来存储session,这种方式token里面一般不会放重要的信息,只是作为识别session的一个标志,对比sessionId + session机制,token里面可以存一些前端用户登录时候的唯一标志,比如设备mac地址这样可以避免sessionId被盗用。并且相对sessionId,token是自己维护的,可控制性更强,可以做到多设备登录,剔除登录用户等复杂操作。这种toke不一定需要加密,一般做一个签名,保证被篡改就行了。
-
-
SOA(Service-Oriented Architecture) 面向服务架构,SOA 做早提出来的时候使用ESB(企业服务总线),现在一般都用微服务,基于ESB的 SOA 对 oracle 之类的大厂依赖太严重。
-
IAAS,Infrastructure(基础设施)-as-a-Service;E租用别的虚拟服务器就是使用IAAS,但是这是租别的 做IAAS的才是牛逼。自己的硬件虚拟化以后动态分割才是牛逼。
-
PAAS,Platform(平台)-as-a-Service;租别的服务组件,比如mysql,ES,OSS之类的。用别人的不牛逼,给别人提供才牛逼。
-
SAAS,Software(软件-as-a-Service。租别人的在线软件,就是使用SaaS,给别人提供SaaS服务那才是做Saas。
-
发布线上版本建议打标签,而不是创建分支,并且 允许环境不应该和分支绑定。比比如预生产可能会作为生产问题修复分支的运行环境。很多时候发现生产问题已经是几个版本以后的事情了,这样才能灵活的基于上线tag来修复问题。有些时候问题只能在指定版本修复,比如给不同用户搭建了多套环境,有的是不能升级到最新版本的,只能在指定版本修复。
-
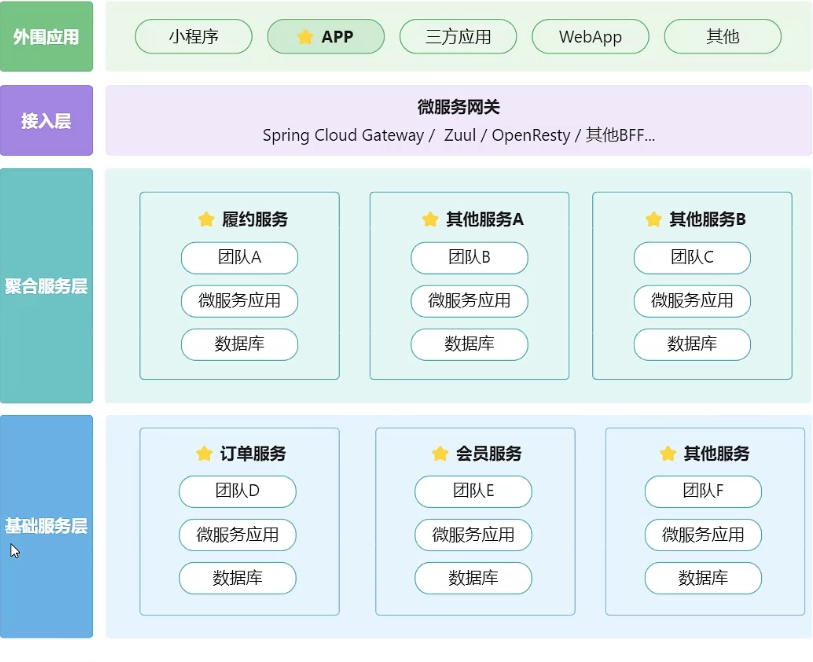
微服务架构组件示意图
![]()
![]()
![]()
-
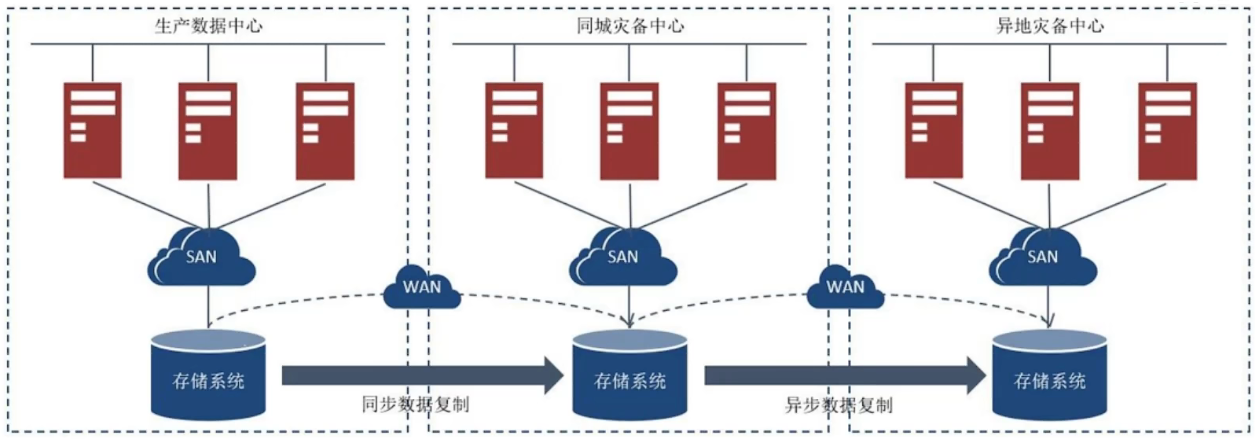
两地三中心,一个主数据中心,一个同城备份中心,一个异地备份中心,在主中心出问题的时候同城备份中心顶上,如果整个城市网络都出了问题,还有异地备份中心可用。两地三中心可以很大程度的保证数据不丢失。
![]()
-
两地三中心,如果只有一个中心对外提供服务是资源浪费是很严重的。两个备用中心也可以利用起来,这就就构建了多活机房,可以最大程度的利用资源。
-
多活数据中心,因为有异地节点,所以一般需要数据专线才能保证数据的传输效率。并且要做到用户就近防范,多节点数据写入,数据一致性也需要考虑。
-
服务之间接口调用出错怎么办?
-
重试+ 幂等,要重试,必须在下游接口是幂等的。
-
使用超时自动返回,而不是无限的让用户等待(服务降级),这是一个安快速失败的处理方案
-
如果连续调用失败,可以直接熔断一段时间。熔断可以减少雪崩出现的概率,大量请求积压很容易导致雪崩。
-
对主干业务影响不大的,可以直接放回成功,异步调用+重新唤起。
-
-
BFF(Backend for Frontend) 是一种对后端接口进一步处理,提取封装前端多端应用需要的数据,BFF 一般是前端在做。
-
http认证方式
-
基础认证,基础认证是无状态的,统一标准是在请求头Authorization里面里面写上认证信息,基础认证需要每次从请求头中取出认证信息,并且核对用户身份,基础认证适合对外提供接口服务。
-
表单认证,表单认证一般是有状态的,会后端缓存session信息。用户一次登录后面通过sessionId或者 token 可以取到 session,一般用于用户登录以后需要频繁操作的场景。
-
-
认证和授权的区别,都会检查用户信息,但是登录强调检查玩以后会做一些信息的记录,一般是有状态的,认证一般是只是检查身份信息,认证是登录的前半部分。
authentication,认证
authorization,授权 -
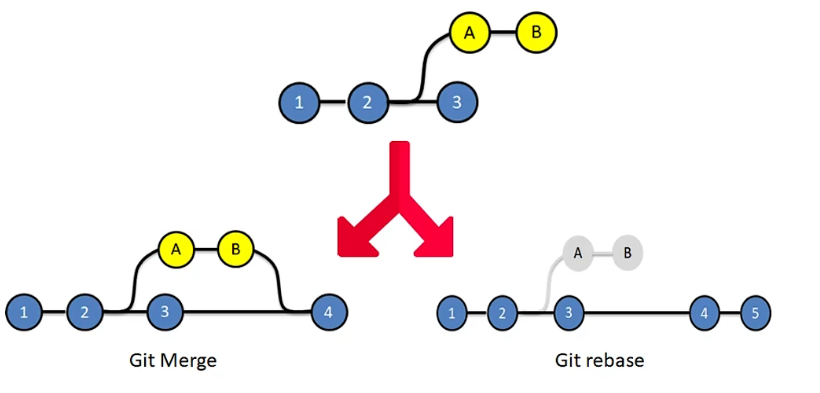
git 的 merge 和 rebase 的区别
![]()
-
rebase类似在在指定分支上重放另外一条分支的类容,合并图上是一条直线,没有合并的分叉,会丢失这段代码是来自那个分支的细节。
-
merge,会记录别的分支合并过来的过程,合并线路图上可以那些修改是在旁支上的,也能看到是什么时候开发分叉,什么时候合并过来的。
-
merge保留的细节更多,建议使用,rebase会丢失细节,建议在个人分支,特色分支等旁需要获取公用分支变动的时候使用。这样可以减少一段分叉,这个旁支合并到公用分支以后会少一次分叉。
-
-
https 安全通信的原理,首先我们明确,http能安全通信不是双方的事情,是三方的事情。
-
App 服务器方向CA中心申请证书,附带自己域名等信息公钥等信息。
-
CA中心下发证书,证书里面包含域名和公钥,并用CA的私钥给证书摘要进行加密(专业叫做签名),然后把签名打包到证书里面。
-
用户浏览器里面保存有CA的公钥。
-
用户请求app 服务器,app服务器下证书包。
-
浏览器拿到证书检查,通过浏览器内置CA公钥对证书签名解密,然后和证书的摘要做对比,一防止证书被篡改,如果被改过,或者请求的域名和证书里面的域名对不上,就会在浏览器上提示。验签过程通过说明证书包没有被篡改,如果域名对的上,说明访问的网站是授权网站。
-
证书里面有app网站的公钥,这个公钥已经不可被篡改的传递给了浏览器,浏览器通过这个公钥加密一个随件的对称加密算法的密钥,然后发送给app服务器。
-
公钥加密的内容只有私钥才能解码,可以保证数据不被泄露,然后app服务器安全的拿到了浏览器的对称密钥,后面的通信通过这个对称加密就行了。
-
对称加密的速度比非对称加密块的多,非对称加密只适合加密少量数据比如原味的摘要,或者原文很短的情况。
-
-
https 抓包工具的原理
-
抓包有两个大前提,客户端操作系统植入指定的证书公钥,用以冒充CA官方的公钥。
-
第二请求要通过一个代理服务器,这个代理服务在浏览器看来就是APP 服务器。在APP服务器看来它就是一个浏览器。代理服务器和通过拆包和封包,得到两边的加密数据。
-
为什么我们的用了 https F12 还是能看到明文?因为浏览器本来就持有密钥,浏览器是知道传输内容的,但是如果中间有个代理来转发数据是看不到内容的,抓包工具中间转发能看到内容的前提是在客户端浏览器加入了证书。所以不要轻易的在自己设备上加入证书,很危险。
-
-
分布式监控应该有哪些东西
-
日志监控
-
硬件指标监控
-
调用过程链路追踪
-
-
http推送除了websocket 以外,还可以考虑SEE(server sent events),但是SSE,但是SSE只服务器到客户端的单向通信。
-
SSE基于http协议的,websocket使用http协议完成部分握手,单通讯过程不是http协议
-
SSE只能支持服务器->客户端的单向通信
-
SEE只支持文本,不支持二进制数据,二进制数据需要转码以后发送
-
SEE默认支持断线重连
-
SEE不需要引入其他任何插件,开发成本低
-
-
websocket是全双工的通信协议
-
ZK是强一致性的,不是特别适合高并发场景,但是很适合强一致性的场景,卡夫卡3.0 开始,逐步弃用zk改用内部kraft选举主节点。
![]()
-
OIDC( openId connect),OIDC 与 OAuth 2.0 相比,多了认证的能力。不但能够返回用户的 access_token,让第三方通过 access_token 调用用户授权过的接口(用户授权),还可以返回用户的 id_token,第三方可以将 id_token 用作用户身份标识(用户认证)。
-
OAuth2.0 Open Authorization(开放授权)2.0的缩写。 Oauth描述的是授权方式,没有描述认证方式OIDC描述的认证方式。
-
metadata 元数据,描述数据的数据或者说数数据的说明书。比如文件的修改时间,数据表的结构,照片的拍摄信息。
-
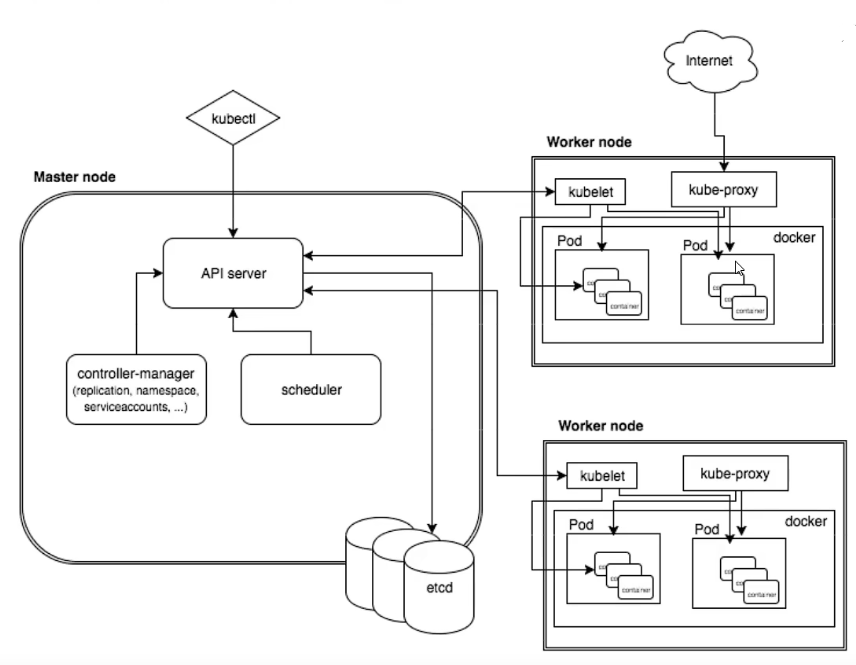
kubernetes架构图
![]()
-
mysql高可用方案
-
MMM(Multi master replication manger),多主节点副本管理,这个是单主写入的,别的不对外提供服务,通过监控节点和VIP来切换可用主节点。
-
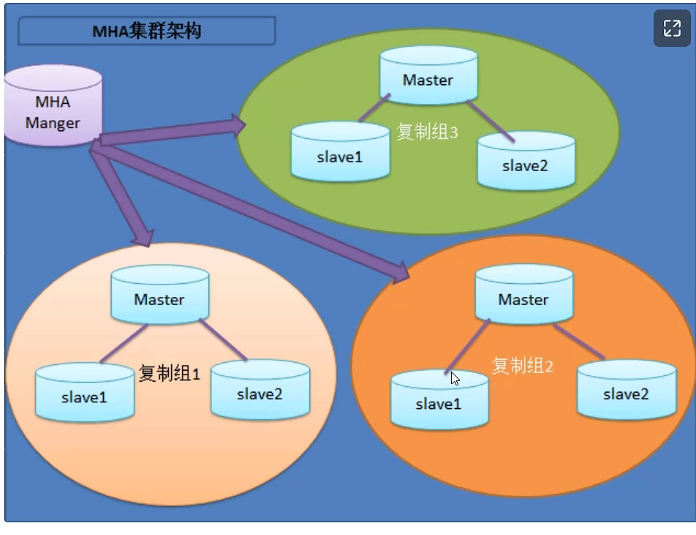
MHA( mysql high available),和MMM 类似依赖监控节点(MHA manger)+VIP,是一主多从,依赖mysql 的半同步复制。
![]()
-
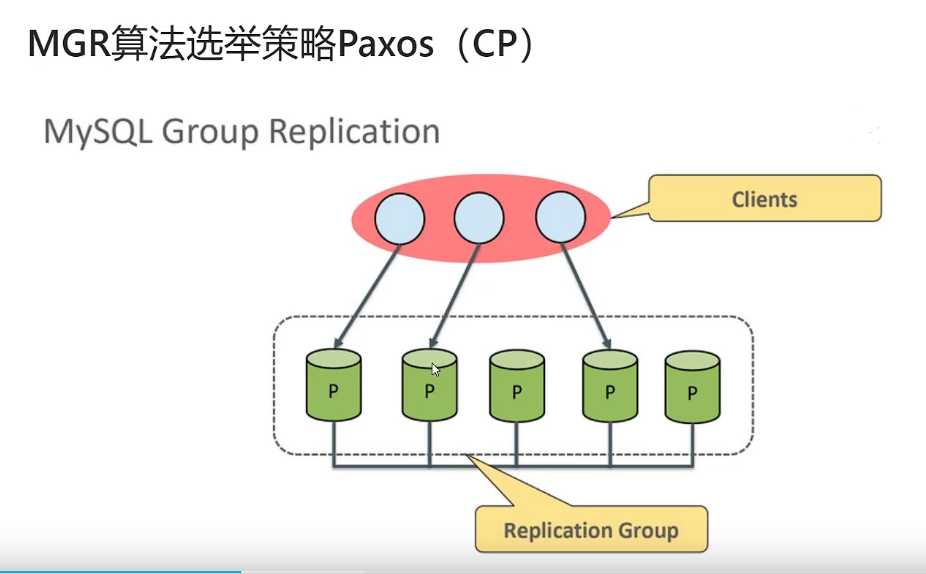
MGR,mysql 官方支持的,依赖全同步复制,支持多个写入节点,多节点写入建议配合支持mysql写一致性的版本使用。限制比较多。故障转移依赖 paxos算法。
![]()
-
mysql cluster,mysql官方的一群模式,多主,但是存文件共享,mysql7 就是 mysql cluster的版本。底层写入通过NDB的存储引擎来的。是一种统一的分布式存储方案。
-
Galera Cluster,三方优秀的多主高可用,多主,文件分别存储在本地。
-
PXC(percona XtraDb cluster),比Galera Cluster出现的早,比Galera Cluster性能差。
-
-
spring native 是使用GraalVm 把java程序编译成 可以linux 上直接运行的程序,有点失启动非常快,占用内存少等优点,缺点是允许效率比不过jvm,而且对运行时动态织如的切面程序兼容不好,只能支持静态的,或者代理模式。spring5 开始默认使用的代理模式不再是cglib而是java的动态代理。要使用spring native导入 spring native的依赖,并且导入 spring-aot-maven-plugin 插件就能生成可以在linux上直接运行的镜像包。
-
SAAA的多住户可以考虑的实现方式
-
数据库物理层面隔离,只是共享应用服务器集群
-
通过scheme逻辑上隔离不同租户数据
-
只在数据库字段上通过租户Id来隔离数据
-
之前我们真实情况是,通过字段隔离多租户,但是大多数真实租户会提供硬件,我们在这上面给他们部署一个支持多租户的,但是只有一个租户的私有环境。我们也对外保留一个共用的多租户saas平台,供部分用户使用,或者新用户体验。
-
-
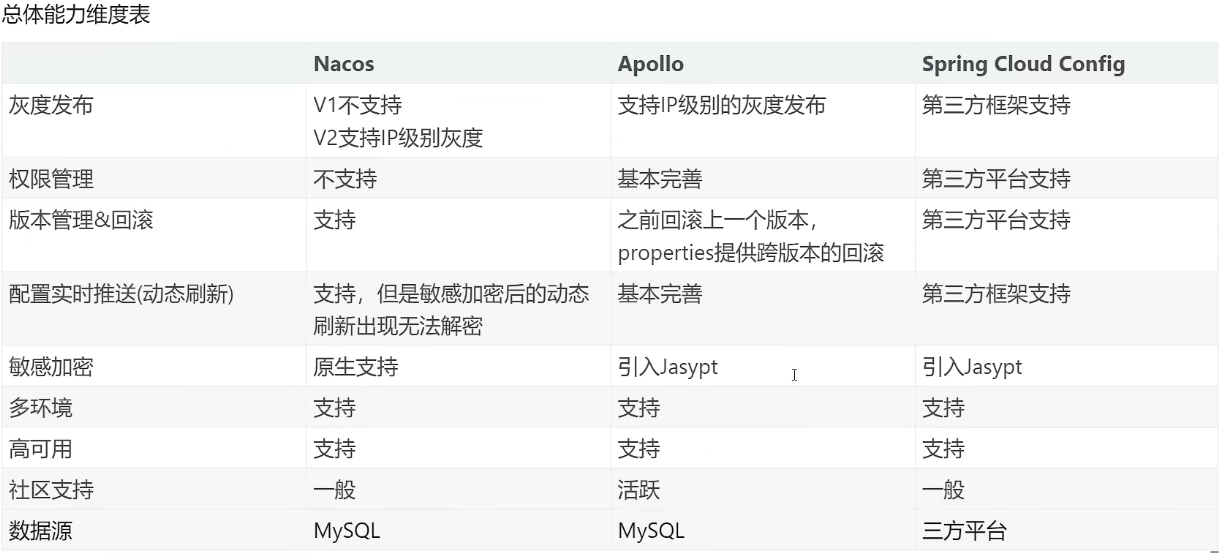
分布式配置中心横向对比
![]()
![]()
-
springcloud config,依赖git之类的工具做版本控制和文件存储。配置推送需要依赖webhook.环境隔离不够细,依赖profile和分支。
-
nacos,效率高 和 springcloud alibaba 是一套,支持配置版本,支持mysql存储。支持推送。环境隔离做的比较细。
-
apollo,支持配置版本,支持常见数据库存储,支持推送,环境隔离做的很细。
-
-
MGR多主节点写入问题怎么解决的?MGR 通过参数 group_replication_consistency 来控制写一致性。
-
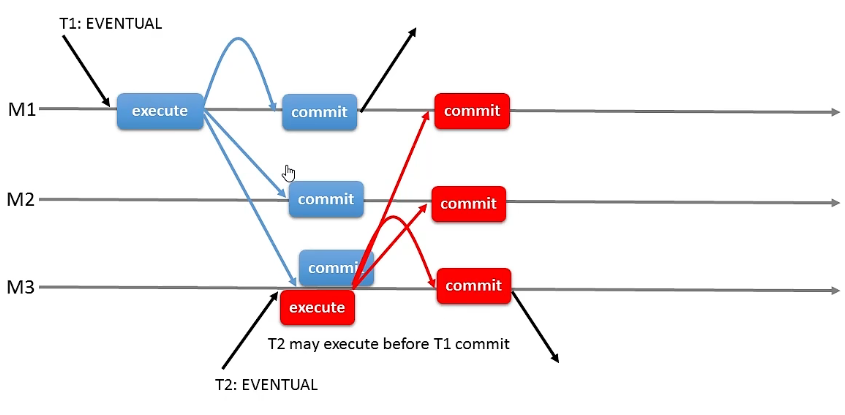
eventual(默认值),这时候多主节点之间可能有写入先后问题。
下面的图,T2在M3上执行的数据版本是T1执行之前,但是提交在T1之后,T2在M1,M2上执行的数据版本基准实在T1以后。eventual最终结果是啥就是啥,即便它可能已经错了。![]()
-
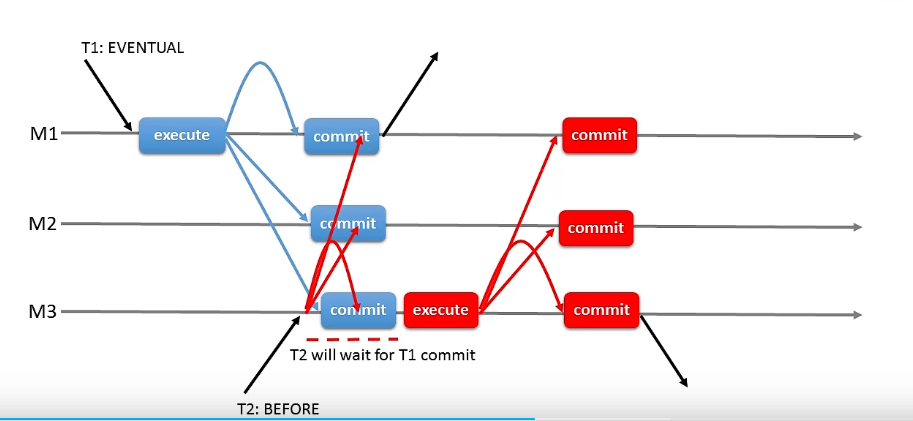
before:如果出现并发问题,那么挂起T2事务,暂时先不执行,等待T1执行完成以后以此为数据基础执行T2,这里面如果T2执行了一半没提交应该怎么做?回退->挂起->等T1执行完成以后重做。before的意思是出了问题以后我在想法办法解决,是乐观锁的思想。
![]()
-
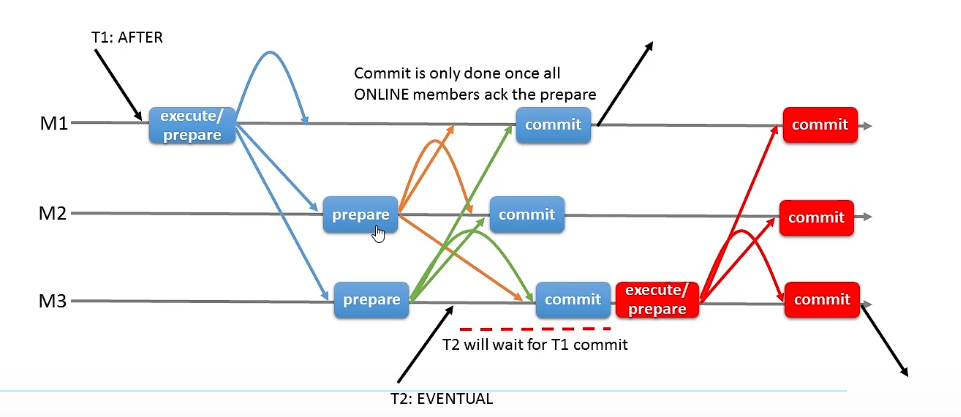
after:在执行以前我就认为会出问题,提前锁定,锁定到 commit 的 阶段别的只能排队到后面去。after可以理解成我预先就认为会出问题,是悲观锁的解决方案。
![]()
-
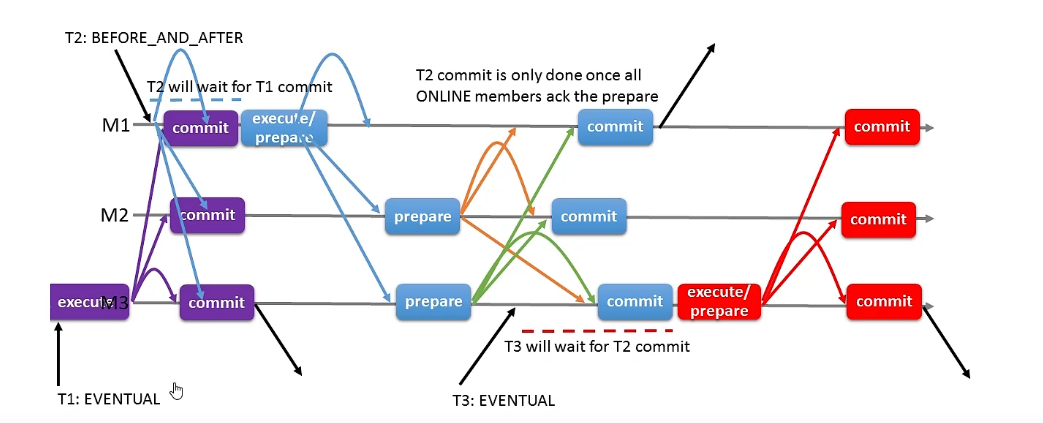
before_and_after: before+after,感觉是前两个策略加起来,我的乐观锁+ 悲观锁,第一次乐观的认为不会出问题,如果出了我就回退+重试,但是乐观锁有如果一致冲突会一致重试无限循环,所以干脆重试一次以后就悲观的锁定以后在执行。
![]()
-
有人觉测试过before>after>before_and_after,但是我觉得从理论上来看,应该是before(乐观)>before_and_after(先乐观在悲观)>after(悲观),理论和测试都有一定的数据基础为准,比如并发概率会影响测试力度。写入数据节点分布不,需要锁的资源分布也活影响结果。
-
-
ICP(index condition pushdown) 索引下推。是一种尽量使用索引已到达减少回盘次数为目的的技术。
-
开启索引下推:index_condition_pushdown=off.
-
mysql 索引下推是一般是默认打开的。
-
ICP的特殊决定它只能在复核索引中,前面一段索引命中,后面通过遍历索已经命中索引的后面一段,然后筛选出可用数据行,减少回盘次数。
-
-
MySQL在其最新的8.0版本中,删除了查询缓存(Query Cache)区域,就此,MySQL的Query Cache彻底的退出了历史舞台。在5.7版本中,MySQL已经将Query Cache的选项(query_cache_type)的缺省值设为了关闭,并在5.7.20版本中,将该配置标记为了Deprecated。
-
mysql的 查询缓存只有sql hash 来命中的,只有sql 完全一样才能命中,id 都不能变,命中率比较低,mysql去掉查询缓存后,推荐使用外置查询缓存,比如proxysql。
-
oauth2.0拿到的token一定是授权用户的token,然后通过token拿到信息一定是用户信息,比如openId,所以我们可以通过token来获取用户的唯一标志来识别用户,能识别用户就是一种认证方式。通过token来识别用户的方式是被OIDC使用,这种方式是对oauth2.0的补充,补充的认证部分的功能,oauth2.0 原始协议只是描述授权。
-
nacos Raft 使用的选举算法故障转移(AP)方式
![]()
-
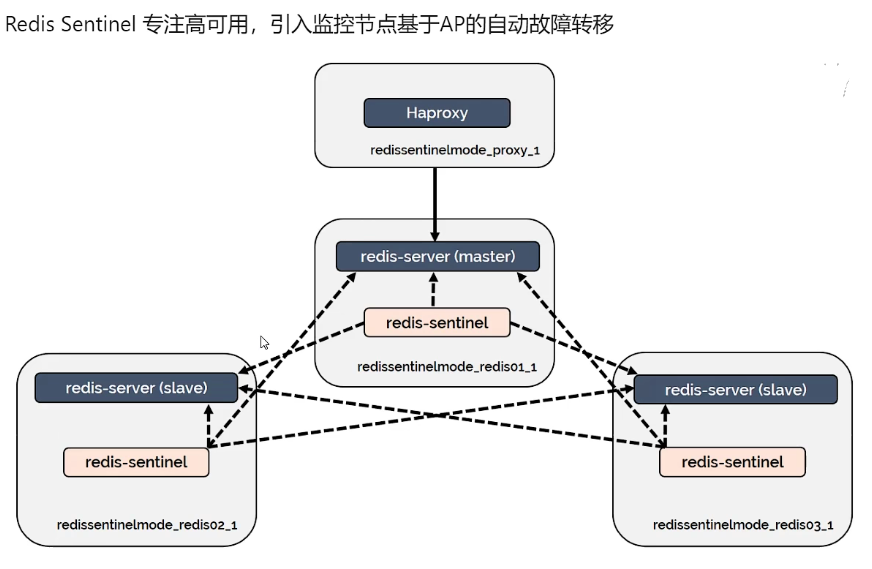
redis sentinel 高可用示意图,sentinel之间通过raft选举主sentinel,然后有他发起投票确定redis的主节点。
![]()
-
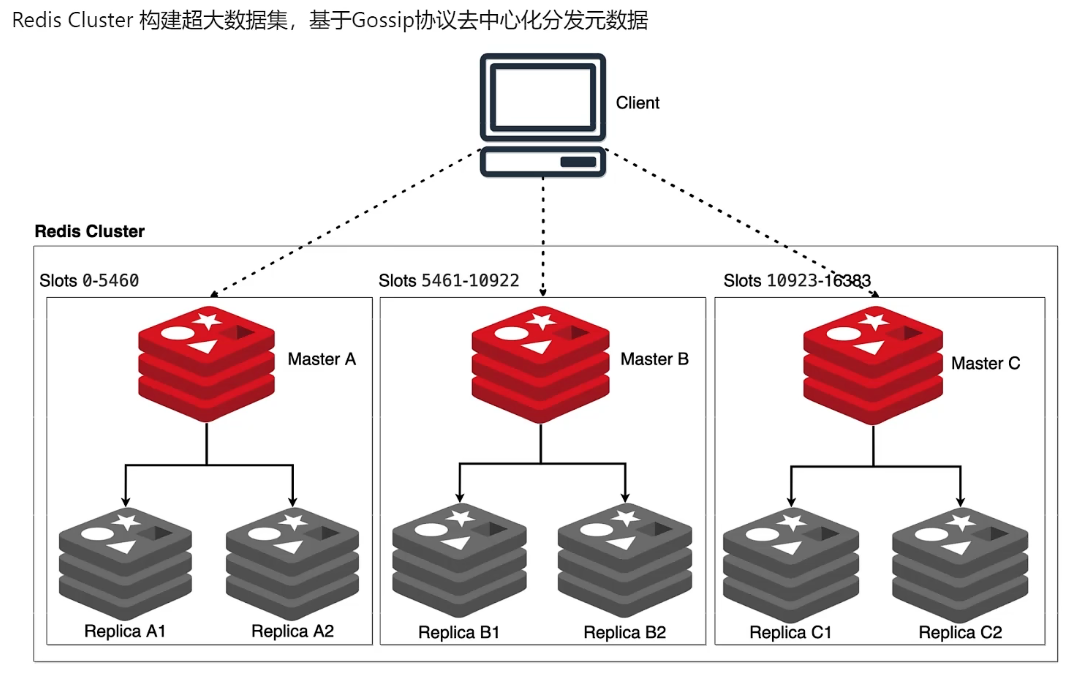
redis 集群模式示意图,集群模式只是数据分片,高可用由分片内部搞定(节点内部可以使用哨兵)
![]()
-
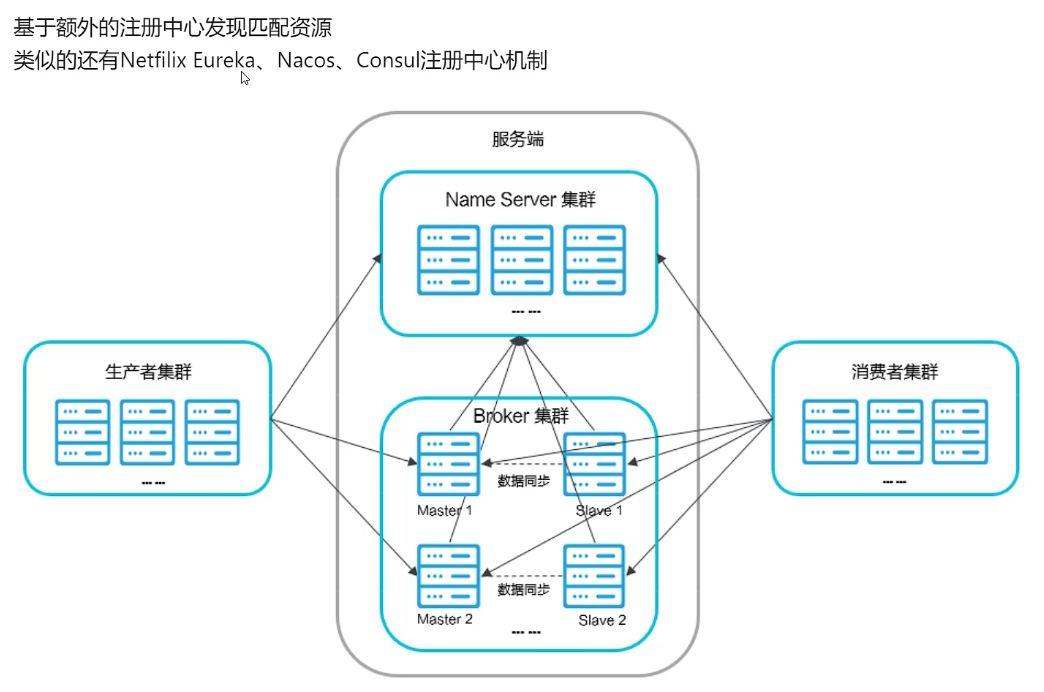
RocketMq 示意图,broker通过nameServer注册中心来保证高可用,而nameServer本身是本身是通过raft算法选举主节点来保证的高可用。
![]()
-
rabbimq客户端静态路由表实现高可用方案
![]()
-
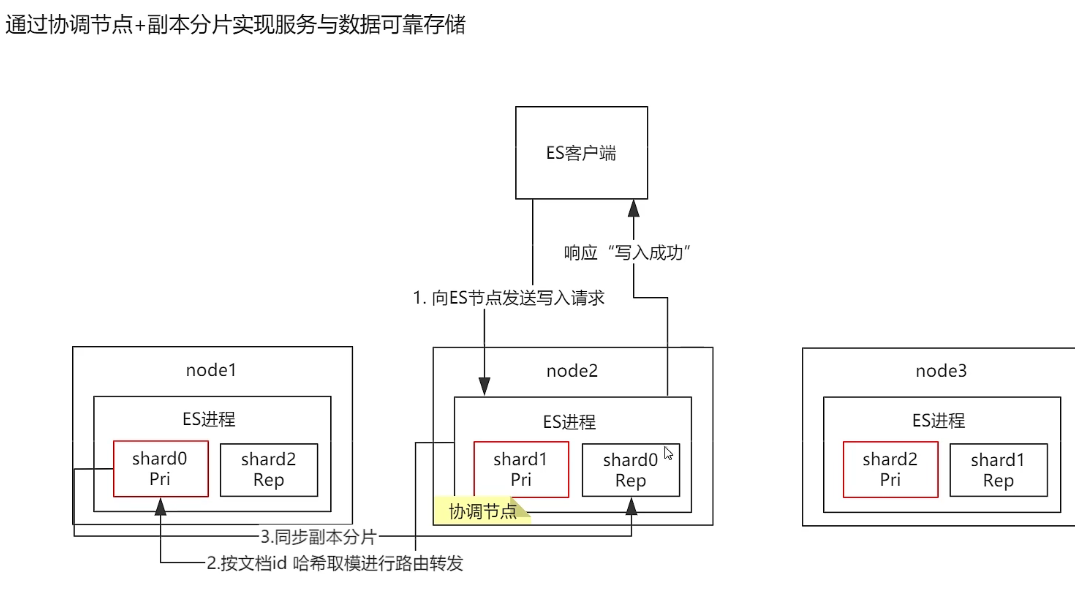
ES通过 多节点和多数据副本来保证高可用
![]()
-
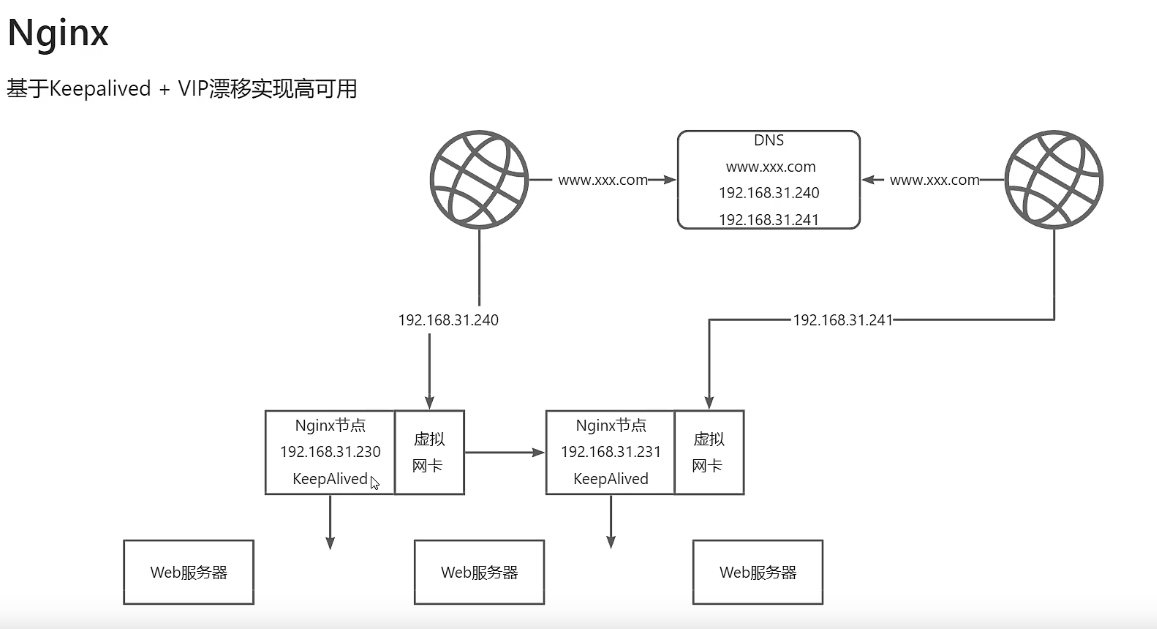
ngxin 高可用方案 keppalived+VIP,keppalived+VIP 不止是对ngxin 可用,它是一种通用的高可用方案。
![]()
-
高可用模式总结
-
通过主从心跳感知主状态,通过选举算法主节点(单主写入的情况)
-
通过协调节点监控主节点是否异常,然后选出新的主节点(单主写入的情况)
-
通过注册中心心跳来自动剔除异常节点,保证高可用(对节点读写,对等节点的情况)
-
通过数据切片,和多节点冗余副本切片保证高可用(多节点读写入,不对等节点)
-
客户端静态路由+服务端数据同步(对等节点,数据同步)
-
-
幂等的处理方案
-
通过唯一标志加锁,保证幂等(唯一标志可能是主键Id,可能是主键Id+状态或者生成的唯一流水Id,或者唯一令牌 )
-
通过参数摘要加锁,保证幂等(有hash碰撞的风险,可以考虑hash+参数大小+请求方法名字等多维度判断,降低可能性)
-
-
MRR(Multi Range Read),mysql5.6引入的新特性默认开启,是mysql 读取范围文件的一种优化策略,二级索引查询的结果是主键ID,按照二级索引得到的id是乱序的,通过Id乱序的去读取磁盘文件是随机读取,如果是顺序的话是连续读取,所以mysql会自动判断id够不够乱,如果比较乱,随机读写比较多就会对id排序以后,尽量通过顺序读取来获取数据。如果使用了MRR执行计划extra 里面会显示using mrr。MRR默认就是开启的,能不能用上看索引得到的id分布。
![]()
-
NLJ(nested loop join)mysql使用join方式。选定驱动表,然后循环的使用驱动表记录里面的关联字段,去被驱动表里面查询数据。join的数据关联方式类似两层的嵌套循环。
-
BKA(batched key accesss),mysql 5.6引入的新特性,默认关闭。在NLJ的过程中,使用MRR思想,从驱动表上一次取出多条,然后通过关联字段排序以后,去被被驱动表查询。
-
mysql 和 ES 数据同步问题,建议程序启动的时候全量同步,之后增量同步,比如通过canel或者直接是异步修改,有时候数据异常是难免的,这时候可能需要提供重新载入ES数据的接口,然后再指定时间调用一次,比如凌晨4点。
-
redisSearch 提供全文检索,基于内存据说速度比mongoDB ES 一个数量级,应该是内存可以完成装下数据的时候才能有这样的效果。
-
http3 使用了 基于UDP的 QUIC 协议。而不是TCP,减少了网络切换的握手时间。
-
JDK19引入了虚拟线程,类似是GO 的协程。java以前的线程和操作系统的线程是一一对应的,现在的虚拟线程和操作系统的线程是多对一的。虚拟线程是轻量级的,它的调度有jVM中间层完成,而不是操作系统。甚至一定程度代替了线程的作用。
-
mysql5.7 mysql8.0 效率对比高吗?我感觉挺高的,但是别人的测试结果好像没太多提升?
-
mysql8 支持降序索引,也就是创建索引的时候传入的 desc 终于生效。使用索引排序的前提索引的顺序和排序的顺序要完全一致或者完全相反(完全相反的时候是反向查询,先便利树的右边),单字段索引,怎么排序都可以,多字段索引,如果排序的时候一个生一个降序在mysql 8 以前是不能命中索引的,这时候在mysql 中中只要创建索引的指定的升降规则和排序的时候完全一样(或者完全相反)就能命中,甚至你可以对两个字段建立不同升降序规则的多条索引。




能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2023-01-20 19:40 zhangyukun 阅读(212) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号