数据采集第五次大作业
作业五
作业1
1.1内容
- 要求
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架爬取京东商城某类商品信息及图片。
- 候选网站: http://www.jd.com
- 关键词: 手机
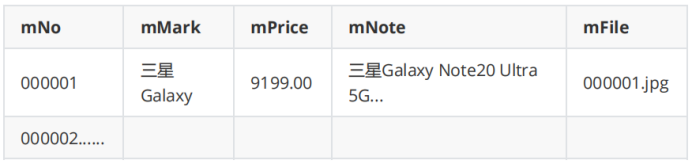
- 输出信息: MYSQL的输出信息如下:
1.2过程&结果
1.2.1发送请求
chrome_options = Options()
# 设置启动时浏览器不可见
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.get(url)
1.2.2单页面解析
首先是模拟浏览器键入关键词搜索,找到搜索框,利用send_keys输入关键词手机并回车:


keyInput = self.driver.find_element(By.ID, "key") # 查找输入框
keyInput.send_keys(key) # 输入关键词
keyInput.send_keys(Keys.ENTER) # 输入回车键代替点击
然后查找商品信息,每个商品对应一个li标签:
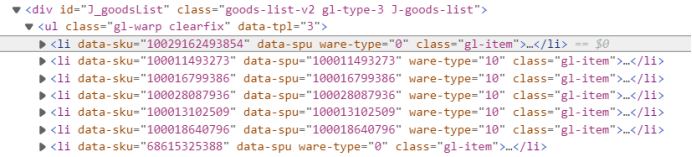
在每个li标签下,查找商品信息,商品名称为em标签下文本的第一部分,note为em下的全部文本,这里需要注意的是图片链接可能在img标签的src属性里或data-lazy-img里,要对它进行处理。
还需要注意execute_script("window.scrollTo(0, document.body.scrollHeight);")模拟滑块滑动到页面底端,因为不滑动时每页只能爬取到30项商品信息,滑动后能加载出其余30个商品。

# 滑动到页面底端,爬取滑动鼠标时才能见到的商品信息
self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # 滑动后要等待一段时间以加载信息
lis = self.driver.find_elements(By.XPATH, "//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# 图片链接在src或data-lazy-img下
try:
src1 = li.find_element(By.XPATH, ".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element(By.XPATH, ".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
# 价格
price = li.find_element(By.XPATH, ".//div[@class='p-price']//i").text
except: # 空值处理
price = "0"
try:
note = li.find_element(By.XPATH, ".//div[@class='p-name p-name-type-2']//em").text
# 品牌名只取note的一部分,以空格分割,取第一段
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "") # 数据清洗
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "") # 数据清洗
note = note.replace(",", "")
except: # 空值处理
note = ""
mark = ""
1.2.3翻页操作
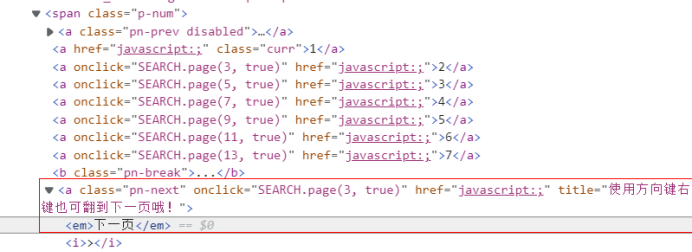
找到翻页按钮,nextPage.click()实现翻页,要注意翻页后需要等待一段时间,以等待页面响应。
if self.page <= 2: # 在此只爬取3页
self.page += 1
# 翻页处理
time.sleep(5)
# 寻找翻页按钮,并点击
nextPage = self.driver.find_element(By.XPATH, "//span[@class='p-num']//a[@class='pn-next']")
nextPage.click()
self.processSpider()
1.2.4信息存储
图片信息下载并保存指定文件夹,这里利用了多线程下载,加快速度;其他信息保存在mysql数据库。
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:] # 根据计数和图片链接末端的.jpg/.png等给图片命名
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2: # 有图片链接则下载
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else: # 没有图片链接则记图片名为空白,不下载
mFile = ""
self.insertDB(no, mark, price, note, mFile)
def download(self, src1, src2, mFile): # 下载图片
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data: # 如果爬取到图片信息则下载
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def insertDB(self, mNo, mMark, mPrice, mNote, mFile): # 插入数据
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print(err)
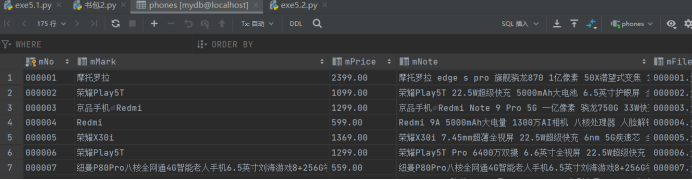
1.2.5结果展示

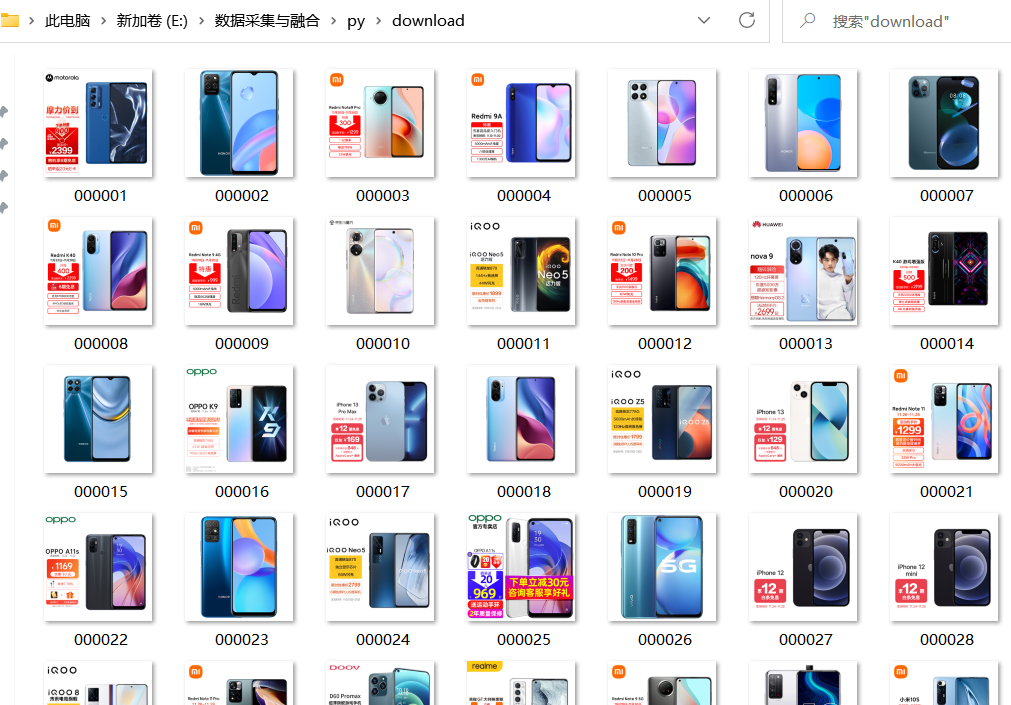
1.3心得
- 巩固了selenium框架爬取网站信息,selenium要注意等待网站响应,否则可能爬取不到信息,还需要注意滚动页面以加载完整信息等。
- 学习了使用send_keys(Keys.ENTER)来键入回车键,代替点击操作,send_keys还有“删除多输入的一个字符send_keys(Keys.BACK_SPACE)”、“输入空格键send_keys(Keys.SPACE)”等用法。
1.4代码链接
https://gitee.com/cxqi/crawl_project/tree/master/实验5/作业1
作业2
2.1内容
- 要求
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
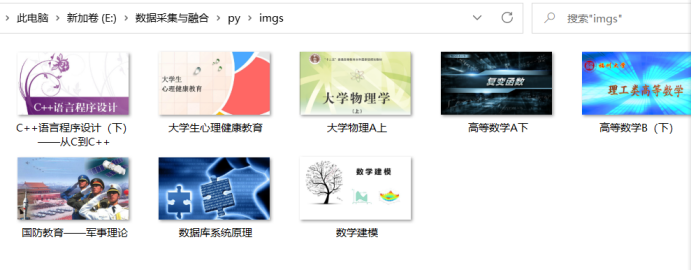
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。
- 候选网站: 中国mooc网:https://www.icourse163.org
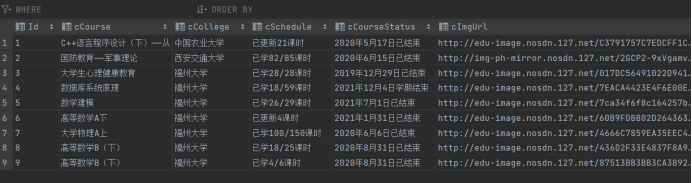
- 输出信息: MYSQL数据库存储和输出格式,表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义设计表头:
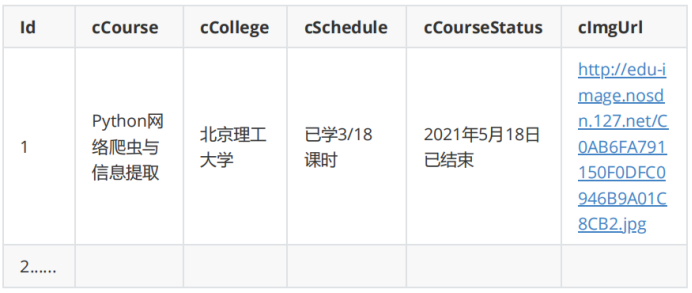
2.2过程&结果
2.2.1发送请求:与作业1相似
2.2.2模拟用户登录
查找登录按钮、其他方式登录、手机号登录,输入手机号、密码,选择登录,完成用户登录。


# 等待登录按钮可以点击时点击它
self.wait.until(EC.element_to_be_clickable(
self.driver.find_element(By.XPATH, "//div[@class='_2yDxF _3luH4']//div[@class='_3uWA6']"))).click()
# 进一步点击其他登录方式
self.wait.until(EC.element_to_be_clickable(
self.driver.find_element(By.XPATH, "//div[@class='mooc-login-set']/div/div[2]/span"))).click()
# 点击手机号登录
self.wait.until(EC.element_to_be_clickable(
self.driver.find_element(By.XPATH,"//div[@class='mooc-login-set']//ul[@class='ux-tabs-underline_hd']/li[2]"))).click()
time.sleep(0.5)
要注意登录框在iframe标签下,需要切换到iframe下才能找到输入手机号和密码的输入框,并键入手机号和密码实现用户登录。
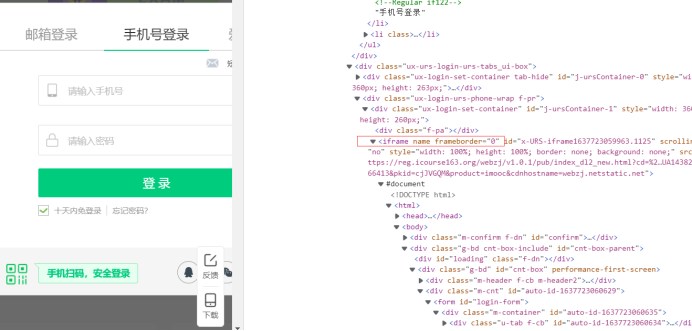


# 切换到iframe登录框
f = self.driver.find_elements(By.TAG_NAME, "iframe")[1]
self.driver.switch_to.frame(f)
# 键入手机号、密码,然后选择登录
self.driver.find_element(By.XPATH, "//input[@type='tel']").send_keys(self.phoneNum)
self.driver.find_elements(By.XPATH, "//input[@type='password']")[1].send_keys(self.passwd)
self.driver.find_element(By.XPATH, "//a[@id='submitBtn']").click()
time.sleep(2)
2.2.3单页面解析
用户登陆后,进入个人中心,发现有MOOC和SPOC板块下都有课程,对于每个板块都是一样的处理方法:每个div标签对应一门课程,进一步对每个课程进行信息爬取。

# 处理爬取的数据
def processSpider(self):
try:
# 进入个人中心
self.driver.find_element(By.XPATH, "//div[@class='web-nav-right-part']/div[3]//a/span").click()
# 进入时默认为MOOC课程,即可进行此页课程爬取
self.process_onepage()
# 点击SPOC课程
self.driver.find_element(By.XPATH, "//div[@class='u-selectTab-container']/div[2]/a/span").click()
# 爬取SPOC课程信息
self.process_onepage()
except Exception as err:
print(err)
def process_onepage(self): # 爬取一个页面
time.sleep(2)
# 课程列表
courses = self.driver.find_elements(By.XPATH, "//div[@class='course-card-wrapper']")
for course in courses:
# 课程名
name = course.find_element(By.XPATH, ".//div[@class='body']//div[@class='text']/span[2]").text
# 开课学校
college = course.find_element(By.XPATH, ".//div[@class='body']//div[@class='school']/a").text
# 课程进度
schedule = course.find_element(By.XPATH, ".//div[@class='body']//div[2]//div[@class='text']/a/span").text
# 课程状态
courseStatus = course.find_element(By.XPATH,
".//div[@class='body']//div[@class='personal-info']/div[2]").text
# 课程封面图片链接
imgUrl = course.find_element(By.XPATH, ".//div[@class='img']/img").get_attribute('src')
# 插入数据库
print(self.count, name, college, schedule, courseStatus, imgUrl)
# 插入数据库
self.insertDB(self.count, name, college, schedule, courseStatus, imgUrl)
# 多线程完成图片下载
T = threading.Thread(target=self.download, args=(imgUrl, name))
T.setDaemon(False)
T.start()
self.threads.append(T)
self.count += 1 # 爬取数量增加1
2.3.4信息存储:与作业1相似
2.3.5结果展示
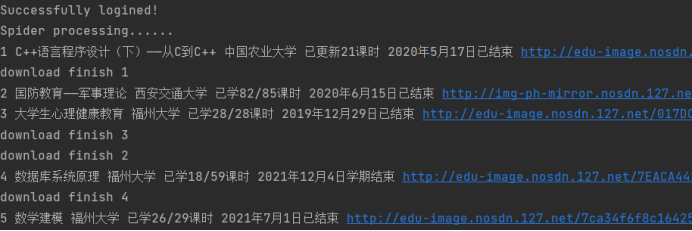
2.3心得
- selenium框架爬取时要特别注意对页面的处理,比如这题要切换到iframe,否则就无法找到输入框进行后续登录操作;还需注意等待页面响应,否则也无法获得信息。
2.4代码链接
https://gitee.com/cxqi/crawl_project/tree/master/实验5/作业2
作业3
3.1要求:
- 理解Flume架构和关键特性,掌握使用Flume完成日志采集任务。
- 完成Flume日志采集实验。
3.2结果:
-
任务一:开通MapReduce服务
按照ppt步骤开通MapReduce服务:
-
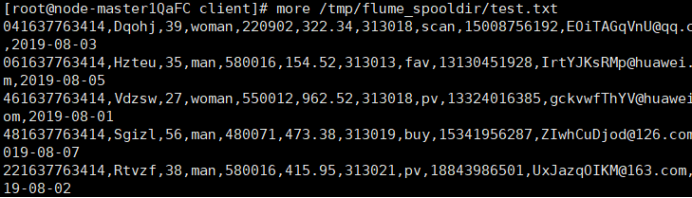
任务二:Python脚本生成测试数据
用xftp7将本地的autodatapython.py文件上传至服务器/opt/client/目录下;执行Python命令,测试生成100条数据。

查看数据:
-
任务三:配置Kafka
首先设置环境变量,执行source命令,使变量生效;在kafka中创建topic;查看topic信息。
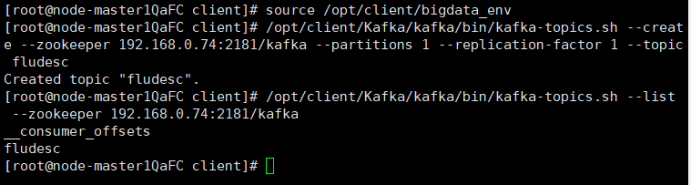
-
任务四:安装Flume客户端
使用Xshell7登录到上步中的弹性服务器上,进入/tmp/MRS-client目录;执行以下命令,解压压缩包获取校验文件与客户端配置包;校验文件包,显示OK则校验成功。
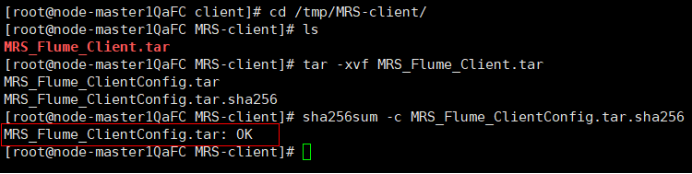
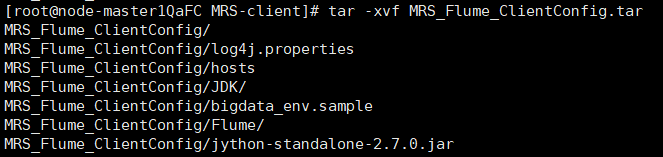
解压“MRS_Flume_ClientConfig.tar”文件。
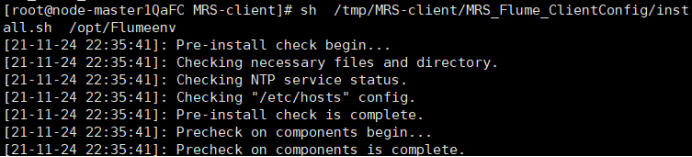
安装客户端运行环境到新的目录“/opt/Flumeenv”,安装时自动生成目录。查看安装输出信息,如有以下结果表示客户端运行环境安装成功:
安装Flume到新目录”/opt/FlumeClient”,安装时自动生成目录(sh /tmp/MRS-client/MRS_Flume_ClientConfig/Flume/install.sh -d /opt/FlumeClient);重启Flume服务。

-
任务五:配置Flume采集数据
新开一个Xshell 7窗口,执行Python脚本命令,再生成一份数据。

查看Kafka中是否有数据产生,可以看到,已经消费出数据,表明Flume到Kafka目前是打通的。
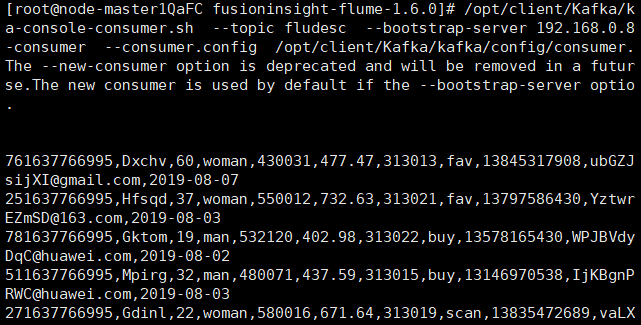
-
031904132 陈晓淇

 浙公网安备 33010602011771号
浙公网安备 33010602011771号