Assignment1词向量
提前导包:
1 import sys 2 assert sys.version_info[0]==3 3 assert sys.version_info[1] >= 5 4 5 from gensim.models import KeyedVectors 6 from gensim.test.utils import datapath 7 import pprint 8 import matplotlib.pyplot as plt 9 plt.rcParams['figure.figsize'] = [10, 5] 10 import nltk 11 from nltk.corpus import reuters 12 import numpy as np 13 import random 14 import scipy as sp 15 from sklearn.decomposition import TruncatedSVD 16 from sklearn.decomposition import PCA 17 18 START_TOKEN = '<START>' 19 END_TOKEN = '<END>' 20 21 np.random.seed(0) 22 random.seed(0)
Tip:from nltk.corpus import reuters这一句需要提前下载reuters,解压后放置C:\Users\Administrator\nltk_data\corpora目录下,这样不用运行时再下载。
1.基于共现矩阵得到的词向量
1.1加载语料,给每句话都加上start_token和end_token
1 def read_corpus(category="crude"): 2 """ Read files from the specified Reuter's category. 3 Params: 4 category (string): category name 5 Return: 6 list of lists, with words from each of the processed files 7 """ 8 files = reuters.fileids(category) 9 return [[START_TOKEN] + [w.lower() for w in list(reuters.words(f))] + [END_TOKEN] for f in files]
测试一下:
1 reuters_corpus = read_corpus() 2 pprint.pprint(reuters_corpus[:1], compact=True, width=100) #pprint美观打印
[['<START>', 'japan', 'to', 'revise', 'long', '-', 'term', 'energy', 'demand', 'downwards', 'the',
'ministry', 'of', 'international', 'trade', 'and', 'industry', '(', 'miti', ')', 'will', 'revise',
'its', 'long', '-', 'term', 'energy', 'supply', '/', 'demand', 'outlook', 'by', 'august', 'to',
'meet', 'a', 'forecast', 'downtrend', 'in', 'japanese', 'energy', 'demand', ',', 'ministry',
'officials', 'said', '.', 'miti', 'is', 'expected', 'to', 'lower', 'the', 'projection', 'for',
'primary', 'energy', 'supplies', 'in', 'the', 'year', '2000', 'to', '550', 'mln', 'kilolitres',
'(', 'kl', ')', 'from', '600', 'mln', ',', 'they', 'said', '.', 'the', 'decision', 'follows',
'the', 'emergence', 'of', 'structural', 'changes', 'in', 'japanese', 'industry', 'following',
'the', 'rise', 'in', 'the', 'value', 'of', 'the', 'yen', 'and', 'a', 'decline', 'in', 'domestic',
'electric', 'power', 'demand', '.', 'miti', 'is', 'planning', 'to', 'work', 'out', 'a', 'revised',
'energy', 'supply', '/', 'demand', 'outlook', 'through', 'deliberations', 'of', 'committee',
'meetings', 'of', 'the', 'agency', 'of', 'natural', 'resources', 'and', 'energy', ',', 'the',
'officials', 'said', '.', 'they', 'said', 'miti', 'will', 'also', 'review', 'the', 'breakdown',
'of', 'energy', 'supply', 'sources', ',', 'including', 'oil', ',', 'nuclear', ',', 'coal', 'and',
'natural', 'gas', '.', 'nuclear', 'energy', 'provided', 'the', 'bulk', 'of', 'japan', "'", 's',
'electric', 'power', 'in', 'the', 'fiscal', 'year', 'ended', 'march', '31', ',', 'supplying',
'an', 'estimated', '27', 'pct', 'on', 'a', 'kilowatt', '/', 'hour', 'basis', ',', 'followed',
'by', 'oil', '(', '23', 'pct', ')', 'and', 'liquefied', 'natural', 'gas', '(', '21', 'pct', '),',
'they', 'noted', '.', '<END>']]
1.2得到词典(去掉重复词)
1 def distinct_words(corpus): 2 """ Determine a list of distinct words for the corpus. 3 Params: 4 corpus (list of list of strings): corpus of documents 5 Return: 6 corpus_words (list of strings): list of distinct words across the corpus, sorted (using python 'sorted' function) 7 num_corpus_words (integer): number of distinct words across the corpus 8 """ 9 corpus_words = [] 10 num_corpus_words = -1 11 12 # ------------------ 13 # Write your implementation here. 14 corpus_words = sorted(list(set([word for wordlst in corpus for word in wordlst]))) 15 num_corpus_words = len(corpus_words) 16 # ------------------ 17 18 return corpus_words, num_corpus_words
测试一下:
1 # Define toy corpus 2 test_corpus = ["{} All that glitters isn't gold {}".format(START_TOKEN, END_TOKEN).split(" "), "{} All's well that ends well {}".format(START_TOKEN, END_TOKEN).split(" ")] 3 test_corpus_words, num_corpus_words = distinct_words(test_corpus) 4 5 # Correct answers 6 ans_test_corpus_words = sorted([START_TOKEN, "All", "ends", "that", "gold", "All's", "glitters", "isn't", "well", END_TOKEN]) 7 ans_num_corpus_words = len(ans_test_corpus_words) 8 9 # Test correct number of words 10 assert(num_corpus_words == ans_num_corpus_words), "Incorrect number of distinct words. Correct: {}. Yours: {}".format(ans_num_corpus_words, num_corpus_words) 11 12 # Test correct words 13 assert (test_corpus_words == ans_test_corpus_words), "Incorrect corpus_words.\nCorrect: {}\nYours: {}".format(str(ans_test_corpus_words), str(test_corpus_words)) 14 15 # Print Success 16 print ("-" * 80) 17 print("Passed All Tests!") 18 print ("-" * 80)
--------------------------------------------------------------------------------
Passed All Tests!
--------------------------------------------------------------------------------
1.3计算共现矩阵
举个栗子: Co-Occurrence with Fixed Window of n=1
Document 1: "all that glitters is not gold"
Document 2: "all is well that ends well"
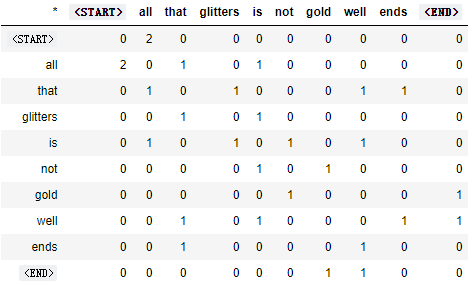
1 def compute_co_occurrence_matrix(corpus, window_size=4): 2 """ Compute co-occurrence matrix for the given corpus and window_size (default of 4). 3 4 Note: Each word in a document should be at the center of a window. Words near edges will have a smaller 5 number of co-occurring words. 6 7 For example, if we take the document "<START> All that glitters is not gold <END>" with window size of 4, 8 "All" will co-occur with "<START>", "that", "glitters", "is", and "not". 9 10 Params: 11 corpus (list of list of strings): corpus of documents 12 window_size (int): size of context window 13 Return: 14 M (a symmetric numpy matrix of shape (number of unique words in the corpus , number of unique words in the corpus)): 15 Co-occurence matrix of word counts. 16 The ordering of the words in the rows/columns should be the same as the ordering of the words given by the distinct_words function. 17 word2Ind (dict): dictionary that maps word to index (i.e. row/column number) for matrix M. 18 """ 19 words, num_words = distinct_words(corpus) 20 M = None 21 word2Ind = {} 22 23 # ------------------ 24 # Write your implementation here. 25 M = np.zeros((num_words, num_words)) 26 word2Ind = dict(zip(words, range(num_words))) 27 28 for sen in corpus: 29 for i in range(len(sen)): #sen[i]为中心词 30 center_idx = word2Ind[sen[i]] #center_idx为中心词对应的索引 31 for w in sen[i-window_size : i] + sen[i+1 : i+window_size+1]: #遍历中心词的上下文 32 context_idx = word2Ind[w] #context_idx为上下文对应的索引 33 M[center_idx, context_idx] += 1 34 # ------------------ 35 36 return M, word2Ind
测试一下:
1 # Define toy corpus and get student's co-occurrence matrix 2 test_corpus = ["{} All that glitters isn't gold {}".format(START_TOKEN, END_TOKEN).split(" "), "{} All's well that ends well {}".format(START_TOKEN, END_TOKEN).split(" ")] 3 M_test, word2Ind_test = compute_co_occurrence_matrix(test_corpus, window_size=1) 4 5 # Correct M and word2Ind 6 M_test_ans = np.array( 7 [[0., 0., 0., 0., 0., 0., 1., 0., 0., 1.,], 8 [0., 0., 1., 1., 0., 0., 0., 0., 0., 0.,], 9 [0., 1., 0., 0., 0., 0., 0., 0., 1., 0.,], 10 [0., 1., 0., 0., 0., 0., 0., 0., 0., 1.,], 11 [0., 0., 0., 0., 0., 0., 0., 0., 1., 1.,], 12 [0., 0., 0., 0., 0., 0., 0., 1., 1., 0.,], 13 [1., 0., 0., 0., 0., 0., 0., 1., 0., 0.,], 14 [0., 0., 0., 0., 0., 1., 1., 0., 0., 0.,], 15 [0., 0., 1., 0., 1., 1., 0., 0., 0., 1.,], 16 [1., 0., 0., 1., 1., 0., 0., 0., 1., 0.,]] 17 ) 18 ans_test_corpus_words = sorted([START_TOKEN, "All", "ends", "that", "gold", "All's", "glitters", "isn't", "well", END_TOKEN]) 19 word2Ind_ans = dict(zip(ans_test_corpus_words, range(len(ans_test_corpus_words)))) 20 21 # Test correct word2Ind 22 assert (word2Ind_ans == word2Ind_test), "Your word2Ind is incorrect:\nCorrect: {}\nYours: {}".format(word2Ind_ans, word2Ind_test) 23 24 # Test correct M shape 25 assert (M_test.shape == M_test_ans.shape), "M matrix has incorrect shape.\nCorrect: {}\nYours: {}".format(M_test.shape, M_test_ans.shape) 26 27 # Test correct M values 28 for w1 in word2Ind_ans.keys(): 29 idx1 = word2Ind_ans[w1] 30 for w2 in word2Ind_ans.keys(): 31 idx2 = word2Ind_ans[w2] 32 student = M_test[idx1, idx2] 33 correct = M_test_ans[idx1, idx2] 34 if student != correct: 35 print("Correct M:") 36 print(M_test_ans) 37 print("Your M: ") 38 print(M_test) 39 raise AssertionError("Incorrect count at index ({}, {})=({}, {}) in matrix M. Yours has {} but should have {}.".format(idx1, idx2, w1, w2, student, correct)) 40 41 # Print Success 42 print ("-" * 80) 43 print("Passed All Tests!") 44 print ("-" * 80)
--------------------------------------------------------------------------------
Passed All Tests!
--------------------------------------------------------------------------------
1.4使用奇异值分解对共现矩阵降维(降成二维是为了在坐标轴中展示)
1 def reduce_to_k_dim(M, k=2): 2 """ Reduce a co-occurence count matrix of dimensionality (num_corpus_words, num_corpus_words) 3 to a matrix of dimensionality (num_corpus_words, k) using the following SVD function from Scikit-Learn: 4 - http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.TruncatedSVD.html 5 6 Params: 7 M (numpy matrix of shape (number of unique words in the corpus , number of unique words in the corpus)): co-occurence matrix of word counts 8 k (int): embedding size of each word after dimension reduction 9 Return: 10 M_reduced (numpy matrix of shape (number of corpus words, k)): matrix of k-dimensioal word embeddings. 11 In terms of the SVD from math class, this actually returns U * S 12 """ 13 n_iters = 10 # Use this parameter in your call to `TruncatedSVD` 14 M_reduced = None 15 print("Running Truncated SVD over %i words..." % (M.shape[0])) 16 17 # ------------------ 18 # Write your implementation here. 19 svd = TruncatedSVD(n_components=k, n_iter=n_iters) 20 M_reduced = svd.fit_transform(M) 21 # ------------------ 22 23 print("Done.") 24 return M_reduced
测试一下:
1 # Define toy corpus and run student code 2 test_corpus = ["{} All that glitters isn't gold {}".format(START_TOKEN, END_TOKEN).split(" "), "{} All's well that ends well {}".format(START_TOKEN, END_TOKEN).split(" ")] 3 M_test, word2Ind_test = compute_co_occurrence_matrix(test_corpus, window_size=1) 4 M_test_reduced = reduce_to_k_dim(M_test, k=2) 5 6 # Test proper dimensions 7 assert (M_test_reduced.shape[0] == 10), "M_reduced has {} rows; should have {}".format(M_test_reduced.shape[0], 10) 8 assert (M_test_reduced.shape[1] == 2), "M_reduced has {} columns; should have {}".format(M_test_reduced.shape[1], 2) 9 10 # Print Success 11 print ("-" * 80) 12 print("Passed All Tests!") 13 print ("-" * 80)
Running Truncated SVD over 10 words...
Done.
--------------------------------------------------------------------------------
Passed All Tests!
--------------------------------------------------------------------------------
1.5使用matplotlib展示
1 def plot_embeddings(M_reduced, word2Ind, words): 2 """ Plot in a scatterplot the embeddings of the words specified in the list "words". 3 NOTE: do not plot all the words listed in M_reduced / word2Ind. 4 Include a label next to each point. 5 6 Params: 7 M_reduced (numpy matrix of shape (number of unique words in the corpus , 2)): matrix of 2-dimensioal word embeddings 8 word2Ind (dict): dictionary that maps word to indices for matrix M 9 words (list of strings): words whose embeddings we want to visualize 10 """ 11 # ------------------ 12 # Write your implementation here. 13 for word in words: 14 idx = word2Ind[word] 15 x = M_reduced[idx, 0] 16 y = M_reduced[idx, 1] 17 18 plt.scatter(x, y, marker='x', color='red') 19 plt.text(x, y, word) 20 # ------------------
测试一下:
1 print ("-" * 80) 2 print ("Outputted Plot:") 3 4 M_reduced_plot_test = np.array([[1, 1], [-1, -1], [1, -1], [-1, 1], [0, 0]]) 5 word2Ind_plot_test = {'test1': 0, 'test2': 1, 'test3': 2, 'test4': 3, 'test5': 4} 6 words = ['test1', 'test2', 'test3', 'test4', 'test5'] 7 plot_embeddings(M_reduced_plot_test, word2Ind_plot_test, words) 8 9 print ("-" * 80)
--------------------------------------------------------------------------------
Outputted Plot:
--------------------------------------------------------------------------------
1.6调用以上方法
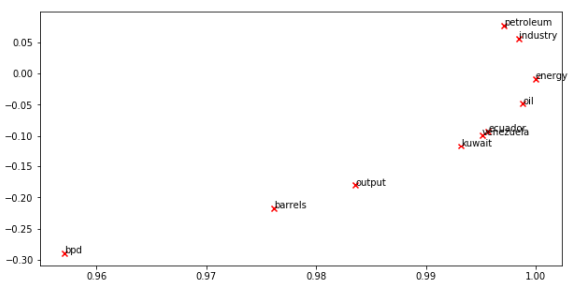
1 reuters_corpus = read_corpus() 2 M_co_occurrence, word2Ind_co_occurrence = compute_co_occurrence_matrix(reuters_corpus) 3 M_reduced_co_occurrence = reduce_to_k_dim(M_co_occurrence, k=2) 4 5 # Rescale (normalize) the rows to make them each of unit-length 6 M_lengths = np.linalg.norm(M_reduced_co_occurrence, axis=1) 7 M_normalized = M_reduced_co_occurrence / M_lengths[:, np.newaxis] # broadcasting 8 9 words = ['barrels', 'bpd', 'ecuador', 'energy', 'industry', 'kuwait', 'oil', 'output', 'petroleum', 'venezuela'] 10 11 plot_embeddings(M_normalized, word2Ind_co_occurrence, words)
Running Truncated SVD over 8185 words...
Done.
2.基于Glove得到的词向量
2.1加载向量模型
1 def load_embedding_model(): 2 """ Load GloVe Vectors 3 Return: 4 wv_from_bin: All 400000 embeddings, each lengh 200 5 """ 6 import gensim.downloader as api 7 wv_from_bin = api.load("glove-wiki-gigaword-200") 8 print("Loaded vocab size %i" % len(wv_from_bin.vocab.keys())) 9 return wv_from_bin 10 11 wv_from_bin = load_embedding_model()
[==================================================] 100.0% 252.1/252.1MB downloaded
Loaded vocab size 400000
2.2计算嵌入矩阵
1 def get_matrix_of_vectors(wv_from_bin, required_words=['barrels', 'bpd', 'ecuador', 'energy', 'industry', 'kuwait', 'oil', 'output', 'petroleum', 'venezuela']): 2 """ Put the GloVe vectors into a matrix M. 3 Param: 4 wv_from_bin: KeyedVectors object; the 400000 GloVe vectors loaded from file 5 Return: 6 M: numpy matrix shape (num words, 200) containing the vectors 7 word2Ind: dictionary mapping each word to its row number in M 8 """ 9 import random 10 words = list(wv_from_bin.vocab.keys()) 11 print("Shuffling words ...") 12 random.seed(224) 13 random.shuffle(words) 14 words = words[:10000] 15 print("Putting %i words into word2Ind and matrix M..." % len(words)) 16 word2Ind = {} 17 M = [] 18 curInd = 0 19 for w in words: 20 try: 21 M.append(wv_from_bin.word_vec(w)) 22 word2Ind[w] = curInd 23 curInd += 1 24 except KeyError: 25 continue 26 for w in required_words: 27 if w in words: 28 continue 29 try: 30 M.append(wv_from_bin.word_vec(w)) 31 word2Ind[w] = curInd 32 curInd += 1 33 except KeyError: 34 continue 35 M = np.stack(M) 36 print("Done.") 37 return M, word2Ind 38 39 40 M, word2Ind = get_matrix_of_vectors(wv_from_bin) 41 M_reduced = reduce_to_k_dim(M, k=2) #M_reduced.shape= (10010, 2) 42 43 # Rescale (normalize) the rows to make them each of unit-length 44 M_lengths = np.linalg.norm(M_reduced, axis=1) #求L2范数,M_lengths.shape= (10010,) 45 M_reduced_normalized = M_reduced / M_lengths[:, np.newaxis] # broadcasting,np.newaxis插入新维度 46 47 words = ['barrels', 'bpd', 'ecuador', 'energy', 'industry', 'kuwait', 'oil', 'output', 'petroleum', 'venezuela'] 48 plot_embeddings(M_reduced_normalized, word2Ind, words)
Shuffling words ...
Putting 10000 words into word2Ind and matrix M...
Done.
Running Truncated SVD over 10010 words...
Done.
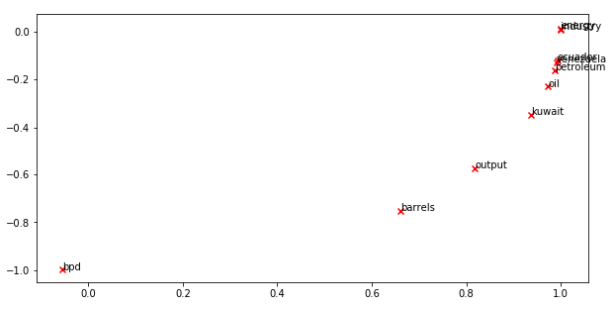
和共现矩阵得到的结果类似。
2.3前十个最相似的单词,根据给定单词的余弦相似度对表中的其他单词进行排序
1 # ------------------ 2 # Write your implementation here. 3 similarwords = wv_from_bin.most_similar('leaves') 4 print(similarwords) 5 # ------------------
[('ends', 0.6128067970275879), ('leaf', 0.6027014255523682), ('stems', 0.5998532772064209), ('takes', 0.5902855396270752), ('leaving', 0.5761634111404419), ('grows', 0.5663397312164307), ('flowers', 0.5600922107696533), ('turns', 0.5536050796508789), ('leave', 0.5496848225593567), ('goes', 0.5434924960136414)]
2.4计算两个单词间的余弦距离
1 # ------------------ 2 # Write your implementation here. 3 w1, w2, w3 = 'happy', 'cheerful', 'sad' 4 w1_w2_dis = wv_from_bin.distance(w1, w2) 5 w1_w3_dis = wv_from_bin.distance(w1, w3) 6 7 print("Synonyms {}, {} have cosine distance: {}".format(w1, w2, w1_w2_dis)) 8 print("Antonyms {}, {} have cosine distance: {}".format(w1, w3, w1_w3_dis)) 9 # ------------------
Synonyms happy, cheerful have cosine distance: 0.5172466933727264
Antonyms happy, sad have cosine distance: 0.40401363372802734
1 pprint.pprint(wv_from_bin.most_similar(positive=['woman', 'king'], negative=['man']))
[('queen', 0.6978678703308105),
('princess', 0.6081745028495789),
('monarch', 0.5889754891395569),
('throne', 0.5775108933448792),
('prince', 0.5750998258590698),
('elizabeth', 0.5463595986366272),
('daughter', 0.5399125814437866),
('kingdom', 0.5318052172660828),
('mother', 0.5168544054031372),
('crown', 0.5164473056793213)]
2.5嵌入向量存在偏见
1 pprint.pprint(wv_from_bin.most_similar(positive=['woman', 'worker'], negative=['man'])) 2 print() 3 pprint.pprint(wv_from_bin.most_similar(positive=['man', 'worker'], negative=['woman']))
[('employee', 0.6375863552093506),
('workers', 0.6068919897079468),
('nurse', 0.5837947130203247),
('pregnant', 0.5363885760307312),
('mother', 0.5321309566497803),
('employer', 0.5127025842666626),
('teacher', 0.5099577307701111),
('child', 0.5096741914749146),
('homemaker', 0.5019455552101135),
('nurses', 0.4970571994781494)]
[('workers', 0.611325740814209),
('employee', 0.5983108878135681),
('working', 0.5615329742431641),
('laborer', 0.5442320108413696),
('unemployed', 0.5368517637252808),
('job', 0.5278826951980591),
('work', 0.5223963260650635),
('mechanic', 0.5088937282562256),
('worked', 0.5054520964622498),
('factory', 0.4940453767776489)]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号