
循环序列模型-week2编程题2(使用词向量构建Emoji表情生成器)
构建一个模型,输入的是文字(比如“Let’s go see the baseball game tonight!”),输出的是表情(⚾️)。如果使用词向量,会发现即使训练集只明确地将几个单词与特定的表情符号相关联,模型也能够将测试集中的单词归纳、总结到同一个表情符号,甚至有些单词没有出现在你的训练集中也可以。
1.数据集预处理
数据集(X,Y)

1 import numpy as np 2 from emo_utils import * 3 import emoji 4 import matplotlib.pyplot as plt 5 6 X_train, Y_train = read_csv('datasets/train_emoji.csv') #(132,) 7 X_test, Y_test = read_csv('datasets/test.csv') #(56,) 8 9 #最长句子的单词数 10 maxLen = len(max(X_train, key=len).split()) 11 12 #查看训练集中的内容 13 for index in range(5): 14 print(X_train[index], Y_train[index], label_to_emoji(Y_train[index]))
never talk to me again 3 😞
I am proud of your achievements 2 😄
It is the worst day in my life 3 😞
Miss you so much 0 ❤️
food is life 4 🍴
2.实现Emojifier-V1
基准模型如下:
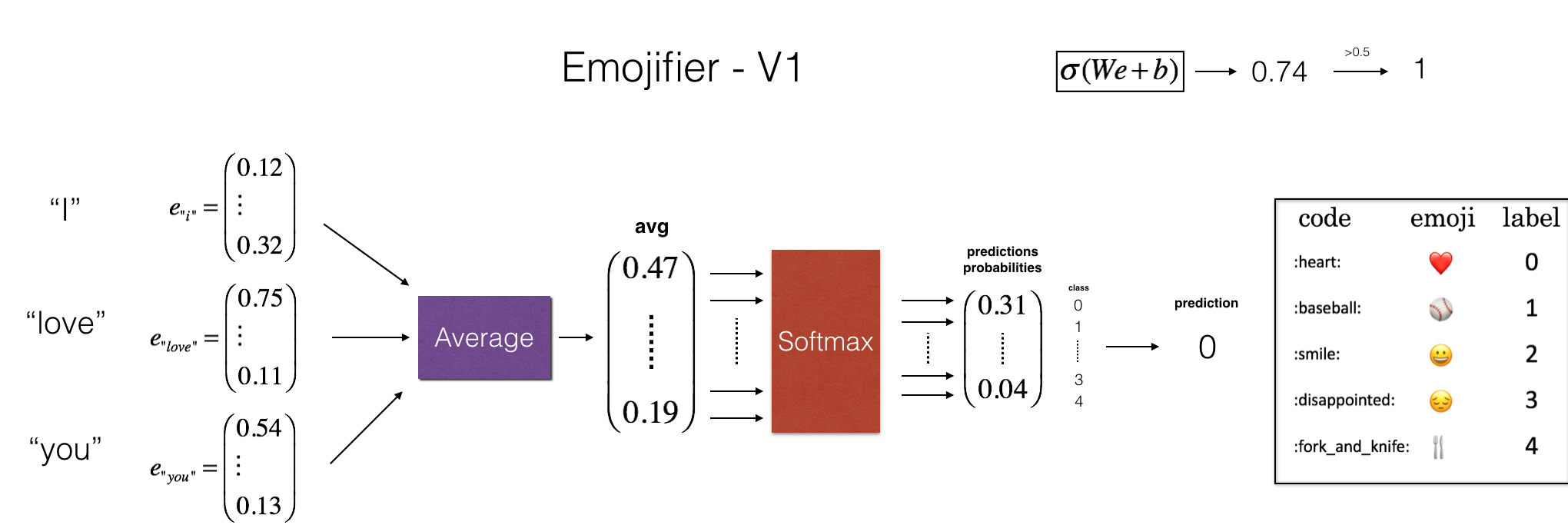
模型的输入是一段文字(比如“l love you”),输出的是维度为(1,5)的向量,即5个可能表情的概率值,最后在argmax层找寻最大可能性的输出。
将标签Y转换成softmax分类器所需要的格式,即从(m,1)转换为独热编码(m,5),每一行都是经过编码后的样本,其中Y_oh指的是“Y-one-hot”。
1 #标签Y单个数值转换成独热编码
2 Y_oh_train = convert_to_one_hot(Y_train, C = 5) #(132,5)
3 Y_oh_test = convert_to_one_hot(Y_test, C = 5) #(56,5)
4
5 for index in range(5):
6 print(Y_train[index], "is converted into one hot", Y_oh_train[index])
3 is converted into one hot [ 0. 0. 0. 1. 0.]
2 is converted into one hot [ 0. 0. 1. 0. 0.]
3 is converted into one hot [ 0. 0. 0. 1. 0.]
0 is converted into one hot [ 1. 0. 0. 0. 0.]
4 is converted into one hot [ 0. 0. 0. 0. 1.]
2.1把输入的句子转换为词向量,然后获取均值
1 #3个字典,{word:index},{index:word},{word:该word的嵌入向量} 2 word_to_index, index_to_word, word_to_vec_map = read_glove_vecs('datasets/glove.6B.50d.txt') 3 4 #测试数据集是否加载正确 5 word = "cucumber" 6 index = 113317 7 print("the index of", word, "in the vocabulary is", word_to_index[word]) #113317 8 print("the", str(index) + "th word in the vocabulary is", index_to_word[index]) #‘cucumber’
实现sentence_to_avg()函数,分为两个步骤:
- 把每个句子转换为小写,然后分割为列表。我们可以使用X.lower()与X.split()。
- 对于句子中的每一个单词,转换为GloVe向量,然后对它们取平均。
1 def sentence_to_avg(sentence, word_to_vec_map): 2 """ 3 Converts a sentence (string) into a list of words (strings). Extracts the GloVe representation of each word 4 and averages its value into a single vector encoding the meaning of the sentence. 5 6 Arguments: 7 sentence -- string, one training example from X 8 word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation 9 10 Returns: 11 avg -- average vector encoding information about the sentence, numpy-array of shape (50,) 12 """ 13 ### START CODE HERE ### 14 # Step 1: Split sentence into list of lower case words (≈ 1 line) 15 words = sentence.lower().split() 16 # Initialize the average word vector, should have the same shape as your word vectors. 17 avg = np.zeros(50,) 18 # Step 2: average the word vectors. You can loop over the words in the list "words". 19 for w in words: 20 avg += word_to_vec_map[w] 21 avg /= len(words) 22 ### END CODE HERE ### 23 24 return avg 25 26 avg = sentence_to_avg("Morrocan couscous is my favorite dish", word_to_vec_map) 27 print("avg = ", avg)
执行结果:
1 avg = [-0.008005 0.56370833 -0.50427333 0.258865 0.55131103 0.03104983 2 -0.21013718 0.16893933 -0.09590267 0.141784 -0.15708967 0.18525867 3 0.6495785 0.38371117 0.21102167 0.11301667 0.02613967 0.26037767 4 0.05820667 -0.01578167 -0.12078833 -0.02471267 0.4128455 0.5152061 5 0.38756167 -0.898661 -0.535145 0.33501167 0.68806933 -0.2156265 6 1.797155 0.10476933 -0.36775333 0.750785 0.10282583 0.348925 7 -0.27262833 0.66768 -0.10706167 -0.283635 0.59580117 0.28747333 8 -0.3366635 0.23393817 0.34349183 0.178405 0.1166155 -0.076433 9 0.1445417 0.09808667]
2.2实现model()函数,获取均值后进行前向传播,计算损失,再进行反向传播,最后更新参数。
计算公式:
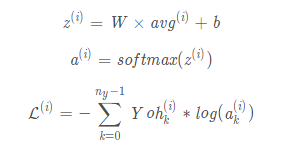
1 def model(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400): 2 """ 3 Model to train word vector representations in numpy. 4 5 Arguments: 6 X -- input data, numpy array of sentences as strings, of shape (m, 1) 7 Y -- labels, numpy array of integers between 0 and 7, numpy-array of shape (m, 1) 8 word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation 9 learning_rate -- learning_rate for the stochastic gradient descent algorithm 10 num_iterations -- number of iterations 11 12 Returns: 13 pred -- vector of predictions, numpy-array of shape (m, 1) 14 W -- weight matrix of the softmax layer, of shape (n_y, n_h) 15 b -- bias of the softmax layer, of shape (n_y,) 16 """ 17 np.random.seed(1) 18 19 # Define number of training examples 20 m = Y.shape[0] # number of training examples 21 n_y = 5 # number of classes 22 n_h = 50 # dimensions of the GloVe vectors 23 24 # Initialize parameters using Xavier initialization 25 W = np.random.randn(n_y, n_h) / np.sqrt(n_h) 26 b = np.zeros((n_y,)) 27 28 # Convert Y to Y_onehot with n_y classes 29 Y_oh = convert_to_one_hot(Y, C = n_y) 30 31 # Optimization loop 32 for t in range(num_iterations): # Loop over the number of iterations 33 for i in range(m): # Loop over the training examples 34 35 ### START CODE HERE ### (≈ 4 lines of code) 36 # Average the word vectors of the words from the i'th training example 37 avg = sentence_to_avg(X[i], word_to_vec_map) 38 39 # Forward propagate the avg through the softmax layer 40 z = np.dot(W, avg) + b 41 a = softmax(z) 42 # Compute cost using the i'th training label's one hot representation and "A" (the output of the softmax) 43 cost = -np.sum(Y_oh[i] * np.log(a)) 44 ### END CODE HERE ### 45 46 # Compute gradients 47 dz = a - Y_oh[i] 48 dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h)) 49 db = dz 50 51 # Update parameters with Stochastic Gradient Descent 52 W = W - learning_rate * dW 53 b = b - learning_rate * db 54 55 if t % 100 == 0: 56 print("Epoch: " + str(t) + " --- cost = " + str(cost)) 57 pred = predict(X, Y, W, b, word_to_vec_map) 58 59 return pred, W, b
测试训练结果:
1 print(X_train.shape) #(132,) 2 print(Y_train.shape) #(132,) 3 print(np.eye(5)[Y_train.reshape(-1)].shape) #(132, 5) 4 print(X_train[0]) #never talk to me again 5 print(type(X_train)) #<class 'numpy.ndarray'> 6 7 pred, W, b = model(X_train, Y_train, word_to_vec_map)
Epoch: 0 --- cost = 1.95204988128
Accuracy: 0.348484848485
Epoch: 100 --- cost = 0.0797181872601
Accuracy: 0.931818181818
Epoch: 200 --- cost = 0.0445636924368
Accuracy: 0.954545454545
Epoch: 300 --- cost = 0.0343226737879
Accuracy: 0.969696969697
2.3验证测试集
原测试集:
1 print("Training set:") 2 pred_train = predict(X_train, Y_train, W, b, word_to_vec_map) 3 print('Test set:') 4 pred_test = predict(X_test, Y_test, W, b, word_to_vec_map)
Training set:
Accuracy: 0.977272727273
Test set:
Accuracy: 0.857142857143
手动测试:
1 X_my_sentences = np.array(["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "not feeling happy"]) 2 Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]]) 3 4 pred = predict(X_my_sentences, Y_my_labels, W, b, word_to_vec_map) 5 print_predictions(X_my_sentences, pred)
Accuracy: 0.833333333333
i adore you ❤️
i love you ❤️
funny lol 😄
lets play with a ball ⚾
food is ready 🍴
not feeling happy 😄
由于词嵌入的原因,“adore”与“love”很相似,即使训练集中没有“adore”这个词汇,它仍然可以正确表达出“❤️”,但是在“you are not happy”中却表达了“❤️”,是因为这个算法使用均值,忽略了排序,所以不善于理解“not happy”这一类词汇。
对原测试集打印矩阵帮助理解哪些类让模型学习起来比较困难,横轴为预测,竖轴为实际标签:
1 print(Y_test.shape) #(56,) 2 print(' '+ label_to_emoji(0)+ ' ' + label_to_emoji(1) + ' ' + label_to_emoji(2)+ ' ' + label_to_emoji(3)+' ' + label_to_emoji(4)) 3 print(pd.crosstab(Y_test, pred_test.reshape(56,), rownames=['Actual'], colnames=['Predicted'], margins=True)) 4 plot_confusion_matrix(Y_test, pred_test)
执行结果:
1 ❤️ ⚾ 😄 😞 🍴 2 Predicted 0.0 1.0 2.0 3.0 4.0 All 3 Actual 4 0 6 0 0 1 0 7 5 1 0 8 0 0 0 8 6 2 2 0 16 0 0 18 7 3 1 1 2 12 0 16 8 4 0 0 1 0 6 7 9 All 9 9 19 13 6 56

3.在Keras中使用LSTM模块实现Emojifier-V2
这个模型可以解决上面的“not happy”这一类词汇的预测。
加载库
1 import numpy as np 2 np.random.seed(0) 3 from keras.models import Model 4 from keras.layers import Dense, Input, Dropout, LSTM, Activation 5 from keras.layers.embeddings import Embedding 6 from keras.preprocessing import sequence 7 from keras.initializers import glorot_uniform 8 np.random.seed(1)
实现的模型如下(一个两层的LSTM的序列分类器many-to-one):
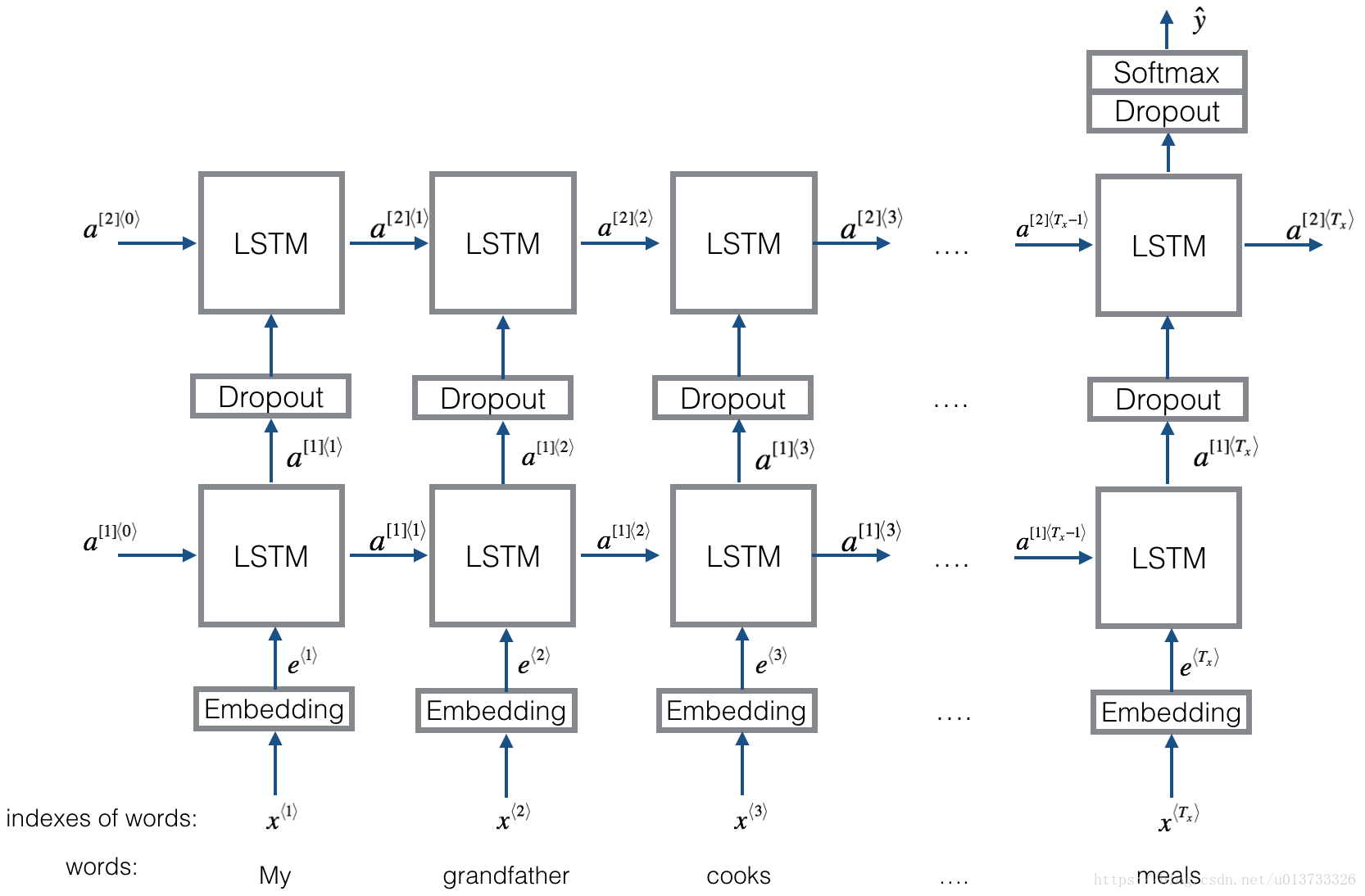
对于具有不同单词数目的句子,转化为向量后所需要的LSTM cell个数也不同,不可能对这些句子进行同时训练。
通用的解决方案是使用填充。指定最长句子的长度,然后对其他句子进行填充到相同长度。比如:指定最大的句子的长度为20,我们可以对每个句子使用“0”来填充,直到句子长度为20,任何一个超过20个单词的句子将被截取,所以一个比较简单的方式就是找到最长句子,获取它的长度,然后指定它的长度为最长句子的长度。
3.1嵌入层(Embedding)
本部分将学习如何在Keras中创建 Embedding层,将用 GloVe 50-dimensional vectors 初始化 Embedding layer。因为训练集很小,所以我们不会更新词嵌入,而是会保留词嵌入的值。
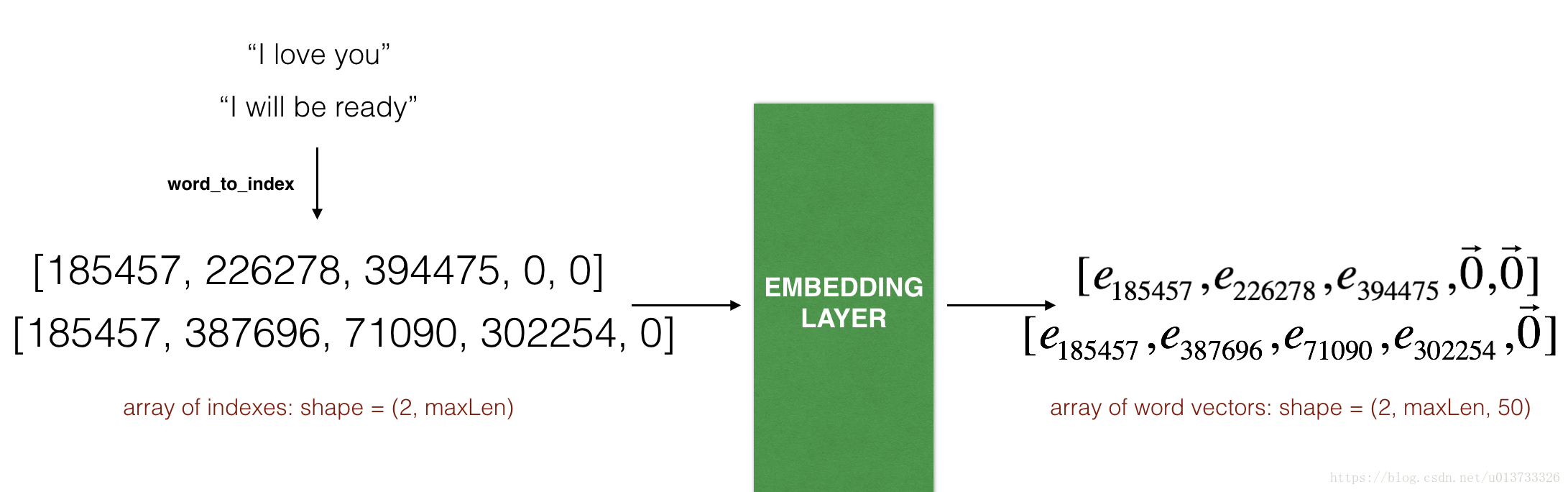
Embedding层输输入一个整数矩阵,维度为(batch的大小,最大的输入长度),输出的数组的维度为(batch的大小, 最大的输入长度, 词向量的维度)。
第一步就是把所有的要训练的句子转换成索引列表,然后对这些列表使用0填充,直到列表长度为最长句子的长度。
1 def sentences_to_indices(X, word_to_index, max_len): 2 """ 3 Converts an array of sentences (strings) into an array of indices corresponding to words in the sentences. 4 The output shape should be such that it can be given to `Embedding()` (described in Figure 4). 5 6 Arguments: 7 X -- array of sentences (strings), of shape (m, 1) 8 word_to_index -- a dictionary containing the each word mapped to its index 9 max_len -- maximum number of words in a sentence. You can assume every sentence in X is no longer than this. 10 11 Returns: 12 X_indices -- array of indices corresponding to words in the sentences from X, of shape (m, max_len) 13 """ 14 m = X.shape[0] # number of training examples 15 16 ### START CODE HERE ### 17 # Initialize X_indices as a numpy matrix of zeros and the correct shape (≈ 1 line) 18 X_indices = np.zeros((m, max_len)) 19 20 for i in range(m): # loop over training examples 21 # Convert the ith training sentence in lower case and split is into words. You should get a list of words. 22 words = X[i].lower().split() 23 # Initialize j to 0 24 j = 0 25 26 # Loop over the words of sentence_words 27 for w in words: 28 # Set the (i,j)th entry of X_indices to the index of the correct word. 29 X_indices[i][j] = word_to_index[w] 30 # Increment j to j + 1 31 j += 1 32 ### END CODE HERE ### 33 34 return X_indices 35 36 37 X1 = np.array(["funny lol", "lets play baseball", "food is ready for you"]) 38 X1_indices = sentences_to_indices(X1,word_to_index, max_len = 5) 39 print("X1 =", X1) 40 print("X1_indices =", X1_indices)
X1 = ['funny lol' 'lets play baseball' 'food is ready for you']
X1_indices = [[ 155345. 225122. 0. 0. 0.]
[ 220930. 286375. 69714. 0. 0.]
[ 151204. 192973. 302254. 151349. 394475.]]
下面构建Embedding()层,使用已经训练好了的词向量,在构建之后,使用sentence_to_indices()生成的数据作为输入,Embedding()层将返回每个句子的词嵌入。
实现pretrained_embedding_layer()函数,分为以下几个步骤:
- 使用0来初始化嵌入矩阵。
- 使用word_to_vec_map来将词嵌入向量填充进嵌入矩阵的每一行。
- 在Keras中定义嵌入层,当调用Embedding()的时候需要让这一层的参数不能被训练,所以我们可以设置trainable=False。
- 将词嵌入的权值设置为词嵌入的值
1 def pretrained_embedding_layer(word_to_vec_map, word_to_index): 2 """ 3 Creates a Keras Embedding() layer and loads in pre-trained GloVe 50-dimensional vectors. 4 5 Arguments: 6 word_to_vec_map -- dictionary mapping words to their GloVe vector representation. 7 word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words) 8 9 Returns: 10 embedding_layer -- pretrained layer Keras instance 11 """ 12 vocab_len = len(word_to_index) + 1 # adding 1 to fit Keras embedding (requirement) 13 emb_dim = word_to_vec_map["cucumber"].shape[0] # define dimensionality of your GloVe word vectors (= 50) 14 15 ### START CODE HERE ### 16 # Initialize the embedding matrix as a numpy array of zeros of shape (vocab_len, dimensions of word vectors = emb_dim) 17 emb_matrix = np.zeros((vocab_len, emb_dim)) 18 19 # Set each row "index" of the embedding matrix to be the word vector representation of the "index"th word of the vocabulary 20 for word, index in word_to_index.items(): 21 emb_matrix[index, :] = word_to_vec_map[word] 22 23 # Define Keras embedding layer with the correct output/input sizes, make it trainable. Use Embedding(...). Make sure to set trainable=False. 24 embedding_layer = Embedding(vocab_len, emb_dim, trainable=False) 25 ### END CODE HERE ### 26 27 # Build the embedding layer, it is required before setting the weights of the embedding layer. Do not modify the "None". 28 embedding_layer.build((None,)) 29 30 # Set the weights of the embedding layer to the embedding matrix. Your layer is now pretrained. 31 embedding_layer.set_weights([emb_matrix]) 32 33 return embedding_layer 34 35 36 embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index) 37 print("weights[0][1][3] =", embedding_layer.get_weights()[0][1][3])
weights[0][1][3] = -0.3403
3.2构建Emojifoer-V2
将上面构建的Embedding层的输出输入到LSTM中。
模型的输入是(m, max_len),定义在了input_shape中,输出是(m, C=5),即5个可能表情的概率值,需要参考Input(shape=...,dtype='...'), LSTM(), Dropout(), Dense(), 与 Activation().
LSTM参数:
- units:是输出的维度,假如units=128,就一个单词而言,你可以把LSTM内部简化看成 ,X为词向量比如64维,W中的128就是units,也就是说通过LSTM,把词的维度由64转变成了128。
- return_sequences:如果为False的话,只返回最后一个状态的输出,是一个(samples,output_dim)2D张量,如果是True,则是返回所有序列状态的输出,是一个(samples,timesteps,output_dim)3D张量。其中samples是样本个数,timesteps是每个样本的状态序列个数,input_dim是每个状态下的特征数
1 def Emojify_V2(input_shape, word_to_vec_map, word_to_index): 2 """ 3 Function creating the Emojify-v2 model's graph. 4 5 Arguments: 6 input_shape -- shape of the input, usually (max_len,) 7 word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation 8 word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words) 9 10 Returns: 11 model -- a model instance in Keras 12 """ 13 ### START CODE HERE ### 14 # Define sentence_indices as the input of the graph, it should be of shape input_shape and dtype 'int32' (as it contains indices). 15 sentence_indices = Input(shape=input_shape, dtype='int32') #(m,max_len) 16 17 # Create the embedding layer pretrained with GloVe Vectors (≈1 line) 18 embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index) 19 20 # Propagate sentence_indices through your embedding layer, you get back the embeddings 21 embeddings = embedding_layer(sentence_indices) 22 23 # Propagate the embeddings through an LSTM layer with 128-dimensional hidden state 24 # Be careful, the returned output should be a batch of sequences. 25 X = LSTM(128, return_sequences=True)(embeddings) #X.shape= (?, ?, 128) 26 # Add dropout with a probability of 0.5 27 X = Dropout(0.5)(X) #rate=0.5,设置需要丢弃的输入比例 28 29 # Propagate X trough another LSTM layer with 128-dimensional hidden state 30 # Be careful, the returned output should be a single hidden state, not a batch of sequences. 31 X = LSTM(128, return_sequences=False)(X) 32 # Add dropout with a probability of 0.5 33 X = Dropout(0.5)(X) 34 # Propagate X through a Dense layer with softmax activation to get back a batch of 5-dimensional vectors. 35 X = Dense(5)(X) #units=5,输出数组的维度为 (*, 5) 36 # Add a softmax activation 37 X = Activation('softmax')(X) 38 39 # Create Model instance which converts sentence_indices into X. 40 model = Model(inputs=sentence_indices, outputs=X) 41 42 ### END CODE HERE ### 43 44 return model 45 46 47 model = Emojify_V2((maxLen,), word_to_vec_map, word_to_index) 48 model.summary()
数据集中所有句子都小于10个单词,所以选择max_len=10。接下来的代码中有“20,223,927”个参数,其中“20,000,050”个参数没有被训练(这是因为它是词向量),剩下的是有“223,877”被训练了的。因为单词表有400,001个单词,所以是400,001∗50=20,000,050个不可训练的参数。
1 _________________________________________________________________ 2 Layer (type) Output Shape Param # 3 ================================================================= 4 input_2 (InputLayer) (None, 10) 0 5 _________________________________________________________________ 6 embedding_5 (Embedding) (None, 10, 50) 20000050 7 _________________________________________________________________ 8 lstm_1 (LSTM) (None, 10, 128) 91648 9 _________________________________________________________________ 10 dropout_1 (Dropout) (None, 10, 128) 0 11 _________________________________________________________________ 12 lstm_2 (LSTM) (None, 128) 131584 13 _________________________________________________________________ 14 dropout_2 (Dropout) (None, 128) 0 15 _________________________________________________________________ 16 dense_1 (Dense) (None, 5) 645 17 _________________________________________________________________ 18 activation_1 (Activation) (None, 5) 0 19 ================================================================= 20 Total params: 20,223,927 21 Trainable params: 223,877 22 Non-trainable params: 20,000,050 23 _________________________________________________________________
创建模型以后,需要编译并评估这个模型。
1 #编译模型,使用categorical_crossentropy损失,adam优化器与 [‘accuracy’] 指标 2 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) 3 4 #X_train转化为X_train_indices,Y_train转化为Y_train_oh 5 X_train_indices = sentences_to_indices(X_train, word_to_index, maxLen) #(132, 10) 6 Y_train_oh = convert_to_one_hot(Y_train, C = 5) #(132, 5) 7 8 #拟合模型 9 model.fit(X_train_indices, Y_train_oh, epochs = 50, batch_size = 32, shuffle=True)
执行结果:


1 Epoch 1/50 2 132/132 [==============================] - 1s - loss: 0.0283 - acc: 0.9848 3 Epoch 2/50 4 132/132 [==============================] - 0s - loss: 0.3319 - acc: 0.9394 5 Epoch 3/50 6 132/132 [==============================] - 0s - loss: 0.1317 - acc: 0.9621 7 Epoch 4/50 8 132/132 [==============================] - 0s - loss: 0.0577 - acc: 0.9848 9 Epoch 5/50 10 132/132 [==============================] - 0s - loss: 0.0205 - acc: 0.9924 11 Epoch 6/50 12 132/132 [==============================] - 0s - loss: 0.0164 - acc: 0.9924 13 Epoch 7/50 14 132/132 [==============================] - 0s - loss: 0.0219 - acc: 0.9848 15 Epoch 8/50 16 132/132 [==============================] - 0s - loss: 0.0028 - acc: 1.0000 17 Epoch 9/50 18 132/132 [==============================] - 0s - loss: 0.0017 - acc: 1.0000 19 Epoch 10/50 20 132/132 [==============================] - 0s - loss: 0.0079 - acc: 0.9924 21 Epoch 11/50 22 132/132 [==============================] - 0s - loss: 0.0036 - acc: 1.0000 23 Epoch 12/50 24 132/132 [==============================] - 0s - loss: 0.0015 - acc: 1.0000 25 Epoch 13/50 26 132/132 [==============================] - 0s - loss: 0.0017 - acc: 1.0000 27 Epoch 14/50 28 132/132 [==============================] - 0s - loss: 0.0045 - acc: 1.0000 29 Epoch 15/50 30 132/132 [==============================] - 0s - loss: 0.0011 - acc: 1.0000 31 Epoch 16/50 32 132/132 [==============================] - 0s - loss: 8.1594e-04 - acc: 1.0000 33 Epoch 17/50 34 132/132 [==============================] - 0s - loss: 0.0018 - acc: 1.0000 35 Epoch 18/50 36 132/132 [==============================] - 0s - loss: 8.9179e-04 - acc: 1.0000 37 Epoch 19/50 38 132/132 [==============================] - 0s - loss: 7.8024e-04 - acc: 1.0000 39 Epoch 20/50 40 132/132 [==============================] - 0s - loss: 8.1553e-04 - acc: 1.0000 41 Epoch 21/50 42 132/132 [==============================] - 0s - loss: 6.0965e-04 - acc: 1.0000 43 Epoch 22/50 44 132/132 [==============================] - 0s - loss: 7.9421e-04 - acc: 1.0000 45 Epoch 23/50 46 132/132 [==============================] - 0s - loss: 5.9728e-04 - acc: 1.0000 47 Epoch 24/50 48 132/132 [==============================] - 0s - loss: 0.0015 - acc: 1.0000 49 Epoch 25/50 50 132/132 [==============================] - 0s - loss: 6.5783e-04 - acc: 1.0000 51 Epoch 26/50 52 132/132 [==============================] - 0s - loss: 3.8151e-04 - acc: 1.0000 53 Epoch 27/50 54 132/132 [==============================] - 0s - loss: 7.5537e-04 - acc: 1.0000 55 Epoch 28/50 56 132/132 [==============================] - 0s - loss: 6.7794e-04 - acc: 1.0000 57 Epoch 29/50 58 132/132 [==============================] - 0s - loss: 8.7243e-04 - acc: 1.0000 59 Epoch 30/50 60 132/132 [==============================] - 0s - loss: 5.2032e-04 - acc: 1.0000 61 Epoch 31/50 62 132/132 [==============================] - 0s - loss: 0.0010 - acc: 1.0000 63 Epoch 32/50 64 132/132 [==============================] - 0s - loss: 5.7492e-04 - acc: 1.0000 65 Epoch 33/50 66 132/132 [==============================] - 0s - loss: 6.1675e-04 - acc: 1.0000 67 Epoch 34/50 68 132/132 [==============================] - 0s - loss: 4.4331e-04 - acc: 1.0000 69 Epoch 35/50 70 132/132 [==============================] - 0s - loss: 3.7460e-04 - acc: 1.0000 71 Epoch 36/50 72 132/132 [==============================] - 0s - loss: 4.6226e-04 - acc: 1.0000 73 Epoch 37/50 74 132/132 [==============================] - 0s - loss: 2.9814e-04 - acc: 1.0000 75 Epoch 38/50 76 132/132 [==============================] - 0s - loss: 4.8404e-04 - acc: 1.0000 77 Epoch 39/50 78 132/132 [==============================] - 0s - loss: 3.0782e-04 - acc: 1.0000 79 Epoch 40/50 80 132/132 [==============================] - 0s - loss: 3.2745e-04 - acc: 1.0000 81 Epoch 41/50 82 132/132 [==============================] - 0s - loss: 3.2599e-04 - acc: 1.0000 83 Epoch 42/50 84 132/132 [==============================] - 0s - loss: 8.4097e-04 - acc: 1.0000 85 Epoch 43/50 86 132/132 [==============================] - 0s - loss: 2.8714e-04 - acc: 1.0000 87 Epoch 44/50 88 132/132 [==============================] - 0s - loss: 4.5671e-04 - acc: 1.0000 89 Epoch 45/50 90 132/132 [==============================] - 0s - loss: 3.2355e-04 - acc: 1.0000 91 Epoch 46/50 92 132/132 [==============================] - 0s - loss: 3.3007e-04 - acc: 1.0000 93 Epoch 47/50 94 132/132 [==============================] - 0s - loss: 2.8113e-04 - acc: 1.0000 95 Epoch 48/50 96 132/132 [==============================] - 0s - loss: 4.7191e-04 - acc: 1.0000 97 Epoch 49/50 98 132/132 [==============================] - 0s - loss: 5.0544e-04 - acc: 1.0000 99 Epoch 50/50 100 132/132 [==============================] - 0s - loss: 1.7207e-04 - acc: 1.0000
准确率基本为1
测试模型在训练集上的表现
1 X_test_indices = sentences_to_indices(X_test, word_to_index, max_len = maxLen) #(56, 10) 2 Y_test_oh = convert_to_one_hot(Y_test, C = 5) #(56, 5) 3 loss, acc = model.evaluate(X_test_indices, Y_test_oh) 4 5 print("Test accuracy = ", acc)
32/56 [================>.............] - ETA: 0sTest accuracy = 0.821428562914
查看哪些句子被错误标记
1 C = 5 2 y_test_oh = np.eye(C)[Y_test.reshape(-1)] 3 X_test_indices = sentences_to_indices(X_test, word_to_index, maxLen) 4 pred = model.predict(X_test_indices) 5 for i in range(len(X_test)): 6 x = X_test_indices 7 num = np.argmax(pred[i]) 8 if(num != Y_test[i]): 9 print('Expected emoji:'+ label_to_emoji(Y_test[i]) + ' prediction: '+ X_test[i] + label_to_emoji(num).strip())
Expected emoji:😄 prediction: he got a very nice raise ❤️
Expected emoji:😄 prediction: she got me a nice present ❤️
Expected emoji:😞 prediction: This girl is messing with me ❤️
Expected emoji:😄 prediction: you brighten my day ❤️
Expected emoji:😞 prediction: she is a bully ❤️
Expected emoji:⚾ prediction: enjoy your game😄
Expected emoji:😞 prediction: My life is so boring ❤️
Expected emoji:😄 prediction: will you be my valentine ❤️
Expected emoji:⚾ prediction: what is your favorite baseball game 😄
Expected emoji:😞 prediction: go away ⚾
自己测试:
1 x_test = np.array(["not feeling happy"]) 2 X_test_indices = sentences_to_indices(x_test, word_to_index, maxLen) 3 print(x_test[0] +' '+ label_to_emoji(np.argmax(model.predict(X_test_indices))))
not feeling happy 😞

 浙公网安备 33010602011771号
浙公网安备 33010602011771号