自然语音处理第三课
语音辨识的模型
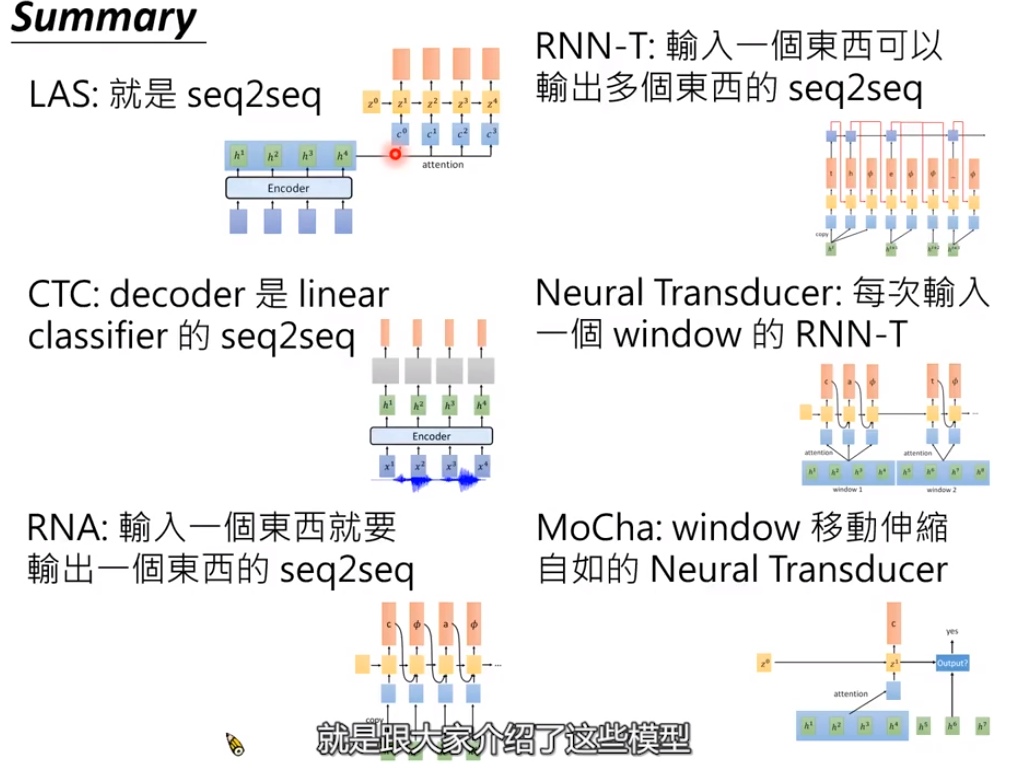
语音识别模型主要分为两种,一种是基于seq2seq的,一种是基于HMM的。
seq2seq的模型主要有LAS,CTC,RNN-T,Neural Transducer,MoChA。
Listen(encoder),Attend,and Spell(decoder) (LAS)
Listen的输入就是一串acoustic features(声学特征),输出另外一串向量。
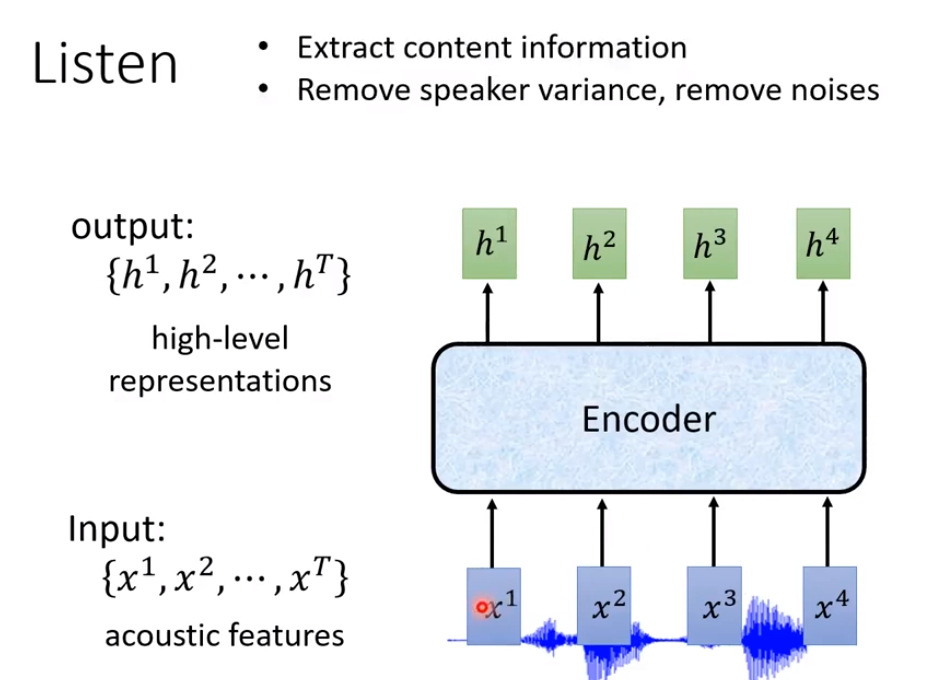
Encoder可以语音里面的杂讯去掉,只抽出跟语音相关的讯息。
Encoder有很多做法,比如RNN(循环神经网络),RNN不只是单向的,还是双向的。https://www.jianshu.com/p/4096bb1ef45b
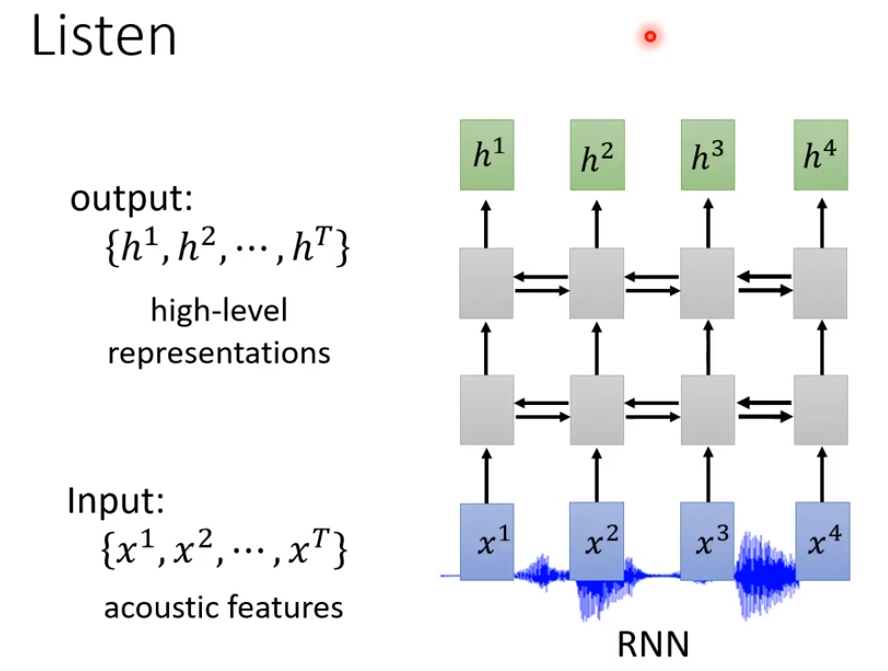
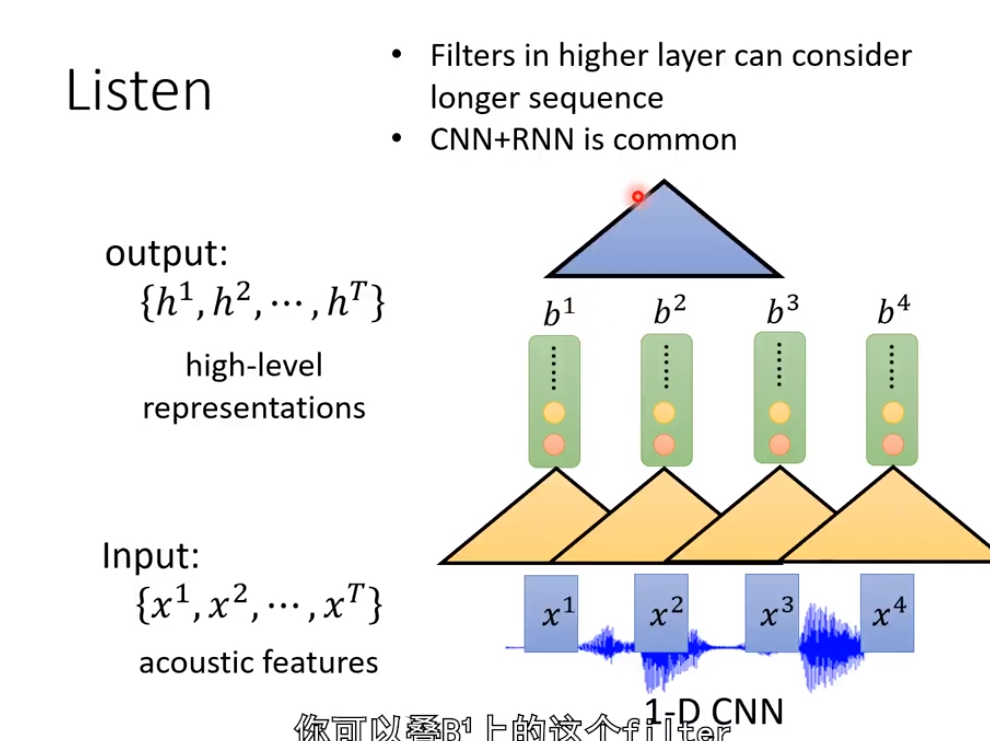
再比如1-D CNN。它采用一个filter沿着时间的方向扫过这些acoustic features,每一个filter会吃一个范围之内的acoustic features进去,然后得到一个数值。
当我们输出b1,b2等这些值的时候,我们不仅考虑x1或者x2,而是考虑x1周边的讯号,x2周边的讯号,再进行处理后得到b1或者b2。
如果b1看的是x1,x2;b2看的是x1,x2,x3;b3看的是x2,x3,x4。再往上叠加一个filter,这个filter覆盖了b1,b2,b3。就说明已经把x1,x2,x3,x4已经全面吃掉。
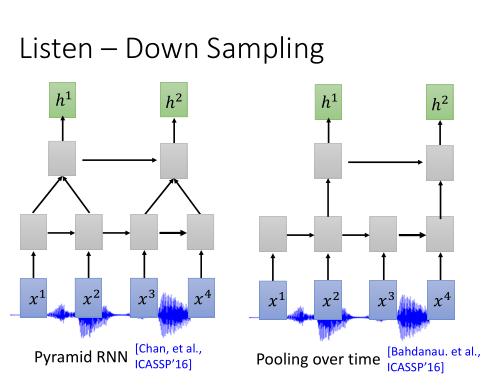
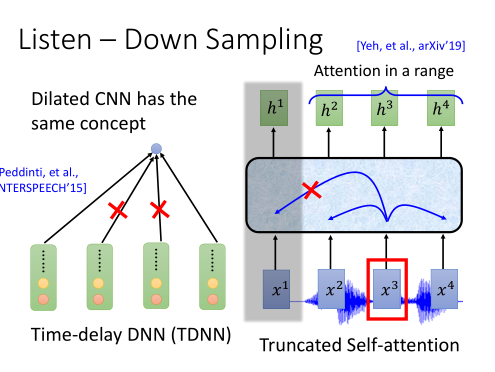
Down Sampling
如果要把一段声讯表示成为acoustic features的话,会非常长(1s的声讯会有100个向量)。因此为了要节省我们在语音辨识的计算量,让我们的训练更有效率,我们就采用Down Sampling,这个方法。
1)Pyramid RNN: 在每一层的RNN输出后,都做一个聚合操作。把两个向量加起来,变成一个向量。
2)Pooling Over time: 两个time step的向量,只选其中一个,输入到下一层。
3)Time-delay DNN: 是CNN常用的一个变形。通常CNN是计算一个窗口内每个元素的加权之和,而TDDNN则只计算第一个和最后一个元素。
4)Truncated self-attention: 是自注意力的一个变形。通常自注意力会对一个序列中每个元素都去注意,而Truncated的做法是只让当前元素去注意一个窗口内的元素。
https://www.cnblogs.com/yanqiang/p/13257228.html
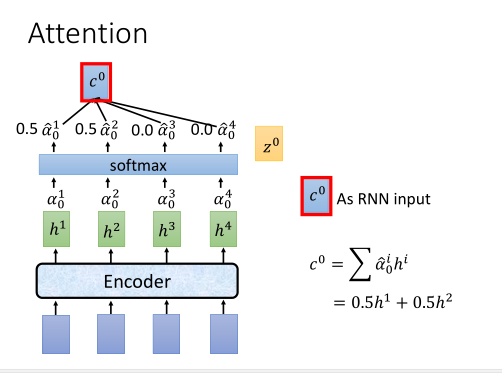
Attention
通过Attention层得到c0。
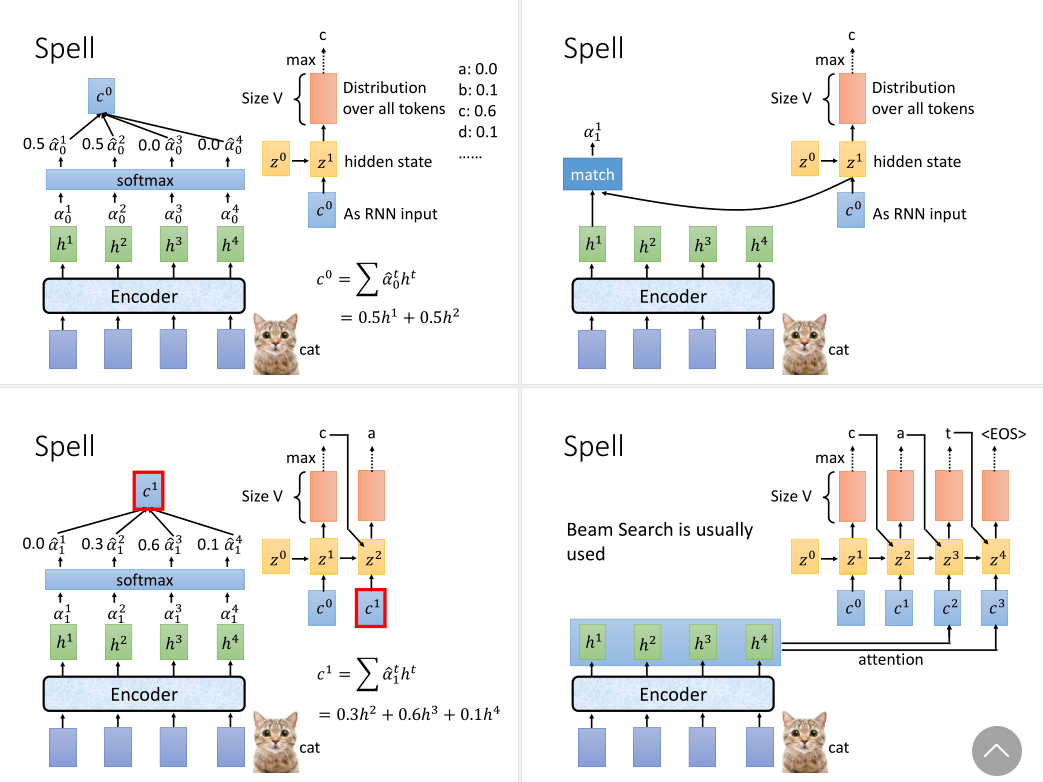
Spell
这个归一化的分布向量和之前的z0会作为解码器RNN的输入,输出是隐层z1,和一个对词表V中所有可能词预测的概率分布向量。我们取max就可以解码得到最可能的第一个token。
再拿z1与原编码器的隐层向量做注意力,得到一个新的注意力分布z2。它与c1一同输入给RNN,同样的方式就能解码得到第二个token。以此类推,直到解码得到的token是一个终止符,就结束。
https://www.cnblogs.com/yanqiang/p/13257228.html
Connectionist Temporal Classification(CTC)

CTC会在output上额外加一个Null来表示辨识结束

可以有很多种output方式
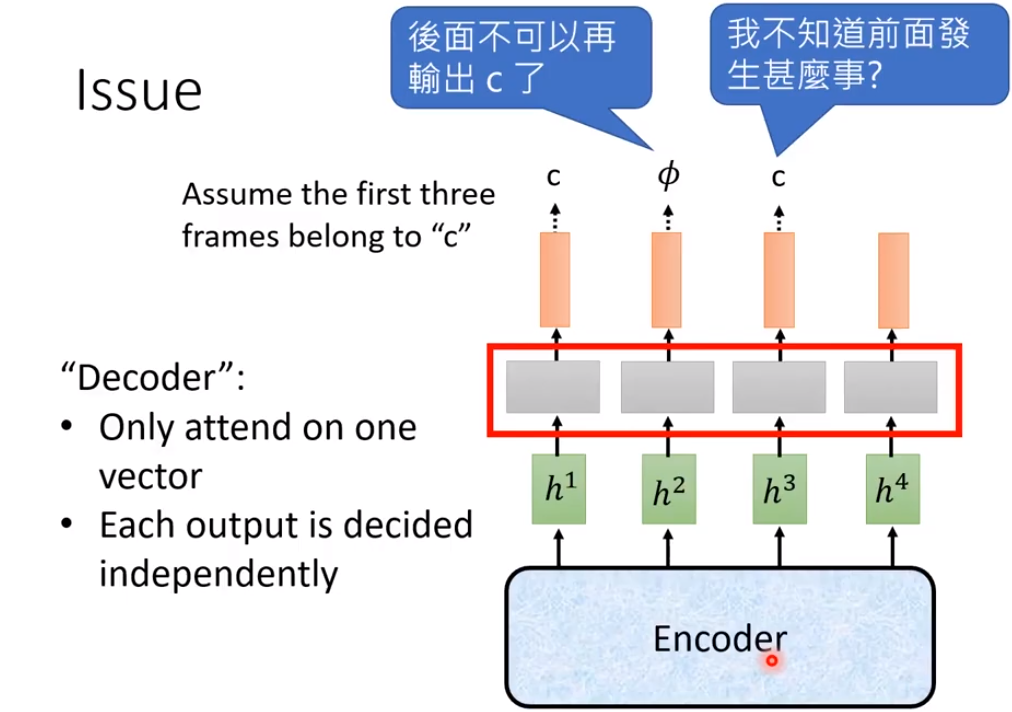
同时CTC也有局限性,如上图。
RNN Transducer(RNN-T)
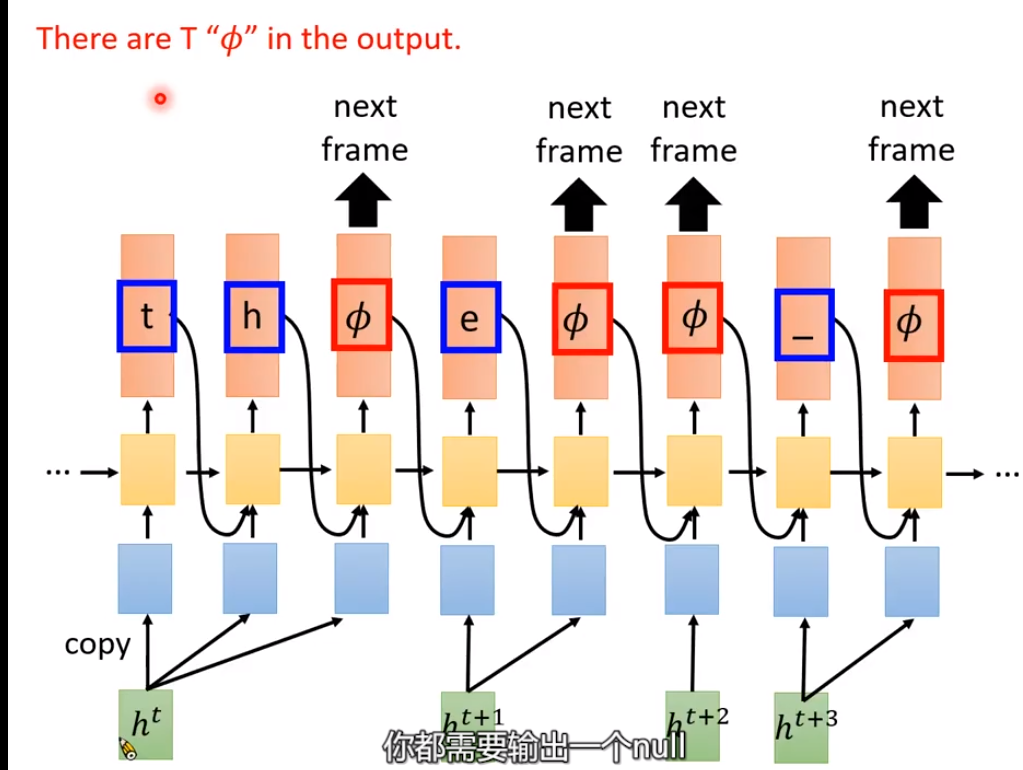
如果有T个acoustic features,也就会生成T个Null。
Neural Transducer
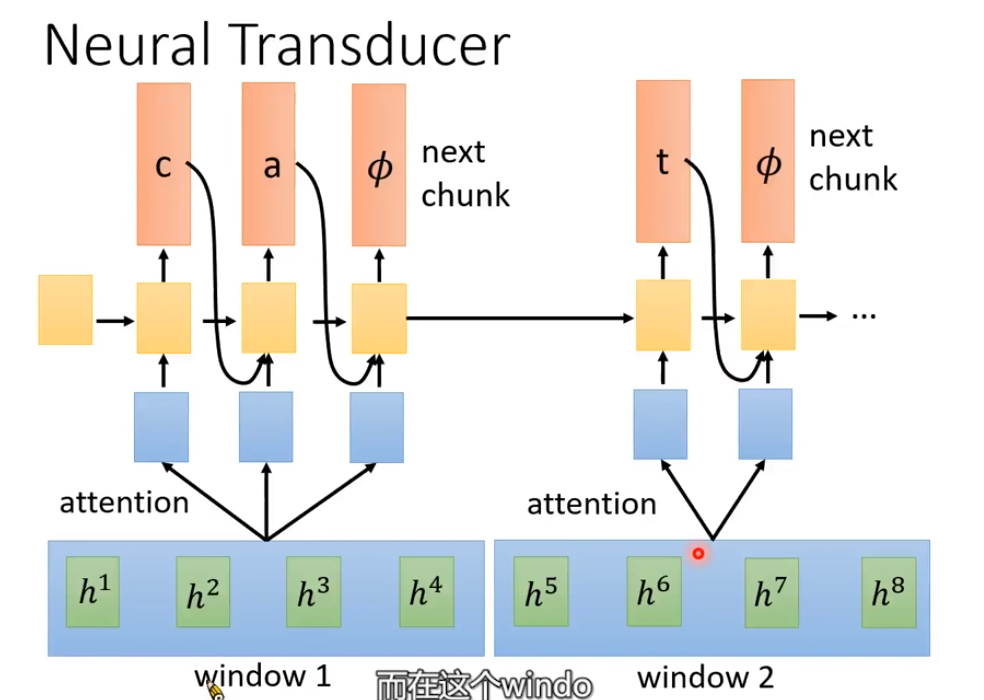
通过对h1,h2,h3,h4做一个window,之后做attention。
Monotonic Chunkwise Attention(MoChA)
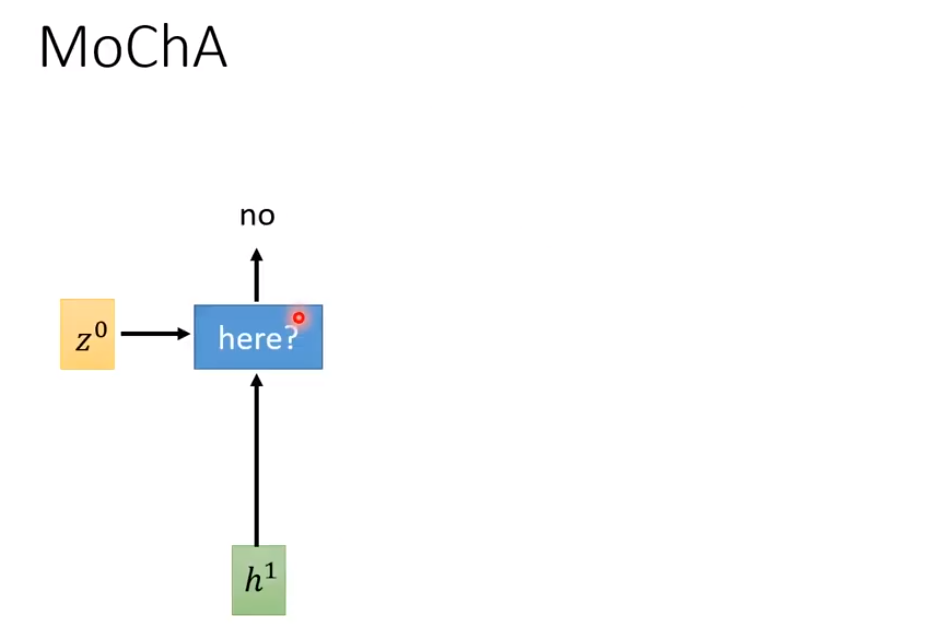
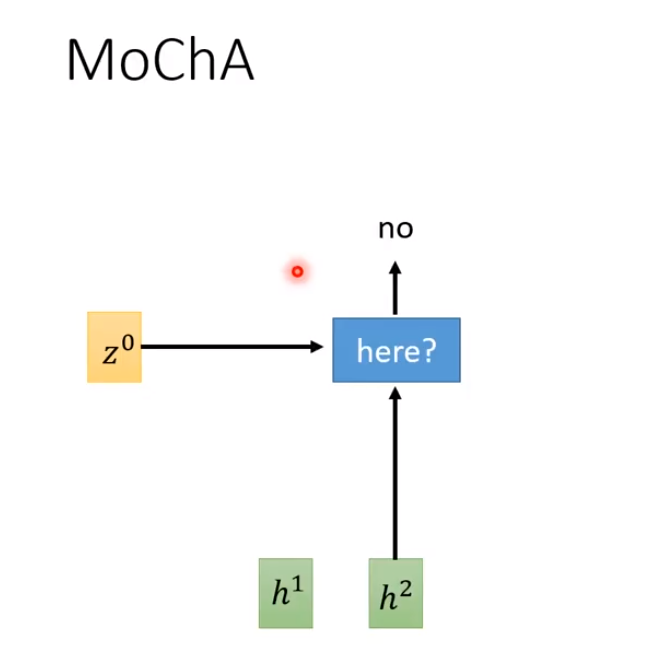
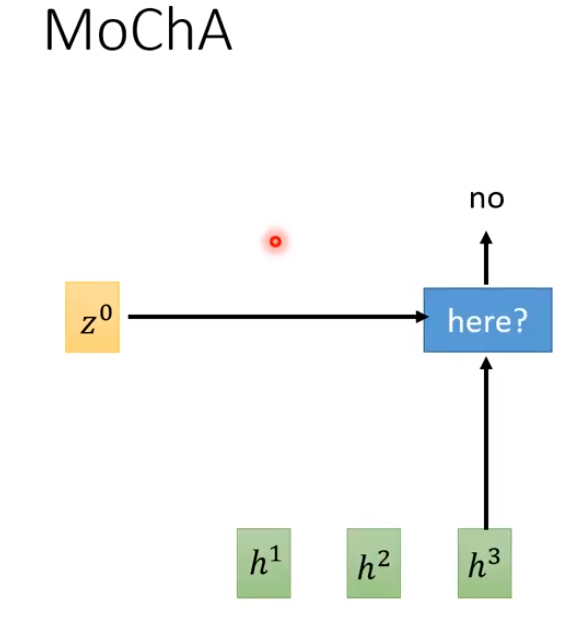
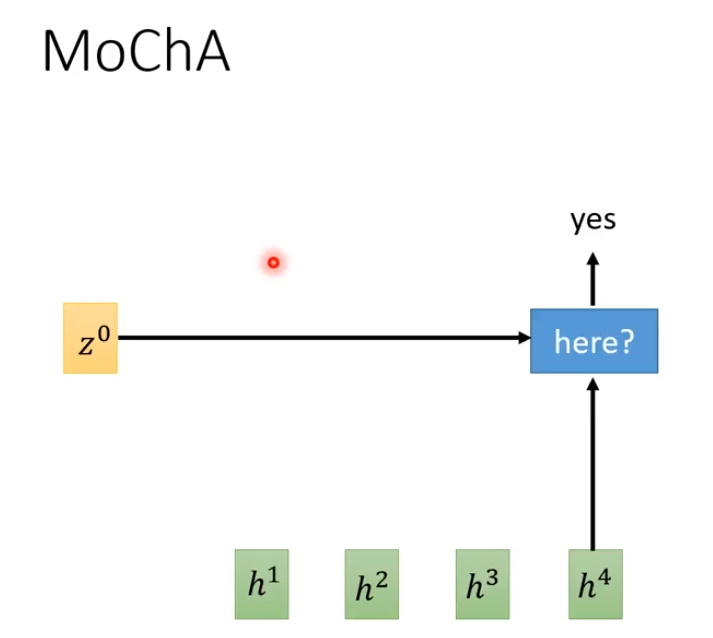
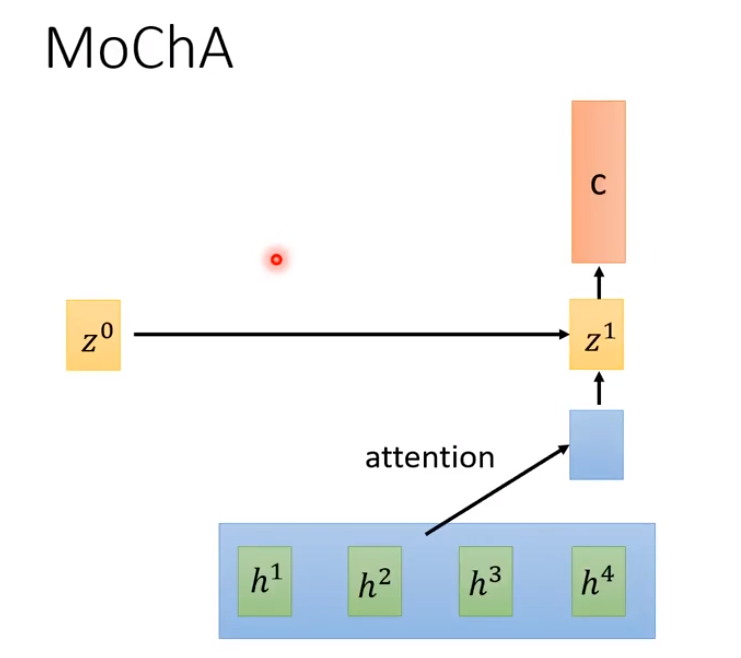
MoChA通过判断要不要把window放在第几个h,然后对其做attention。
Summary

 浙公网安备 33010602011771号
浙公网安备 33010602011771号